使用 Azure Data Factory 或 Synapse Analytics 從 Spark 複製資料
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
此文章概述如何使用 Azure Data Factory 或 Synapse Analytics 管線中的複製活動,從 Spark 複製資料。 本文是根據複製活動概觀一文,該文提供複製活動的一般概觀。
支援的功能
此 Spark 連接器支援下列功能:
| 支援的功能 | IR |
|---|---|
| 複製活動 (來源/-) | (1) (2) |
| 查閱活動 | (1) (2) |
① Azure 整合執行階段 ② 自我裝載整合執行階段
如需複製活動所支援作為來源/接收器的資料存放區清單,請參閱支援的資料存放區表格。
此服務提供的內建驅動程式可啟用連線,因此,您不需手動安裝任何驅動程式,即可使用此連接器。
必要條件
如果您的資料存放區位於內部部署網路、Azure 虛擬網路或 Amazon 虛擬私人雲端中,則必須設定自我裝載整合執行階段以與其連線。
如果您的資料存放區是受控雲端資料服務,則可使用 Azure Integration Runtime。 如果只能存取防火牆規則中核准的 IP,您可以將 Azure Integration Runtime IP 新增至允許清單。
您也可以使用 Azure Data Factory 中的受控虛擬網路整合執行階段功能來存取內部部署網路,而不需要安裝和設定自我裝載整合執行階段。
如需 Data Factory 支援的網路安全性機制和選項的詳細資訊,請參閱資料存取策略。
開始使用
若要透過管線執行複製活動,您可以使用下列其中一個工具或 SDK:
使用 UI 建立連結至 Spark 的服務
使用下列步驟,在 Azure 入口網站 UI 中建立連結至 Spark 的服務。
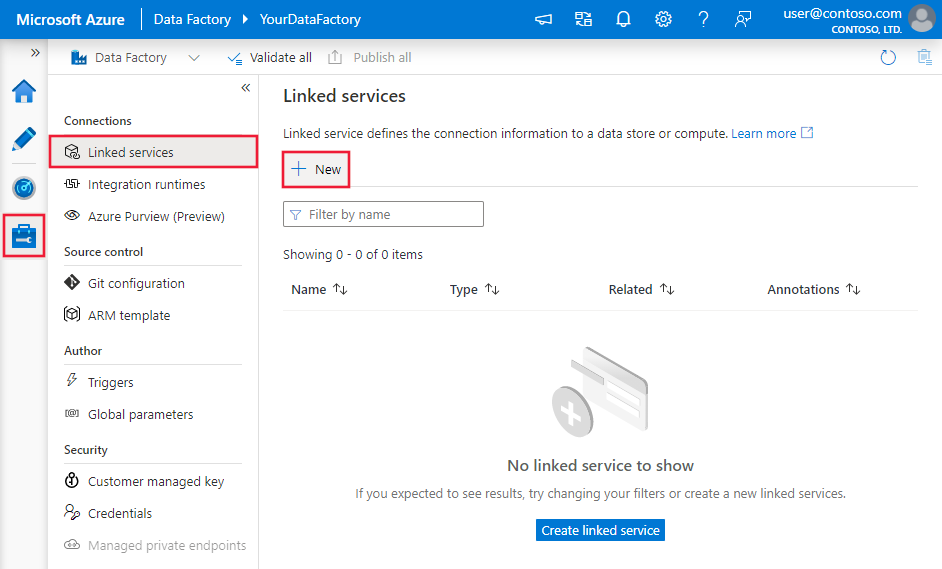
前往 Azure Data Factory 或 Synapse 工作區的 [管理] 索引標籤,選取 [連結服務],然後按一下 [新增]:
搜尋 Spark 並選取 Spark 連接器。

設定服務詳細資料,測試連線,然後建立新的連結服務。
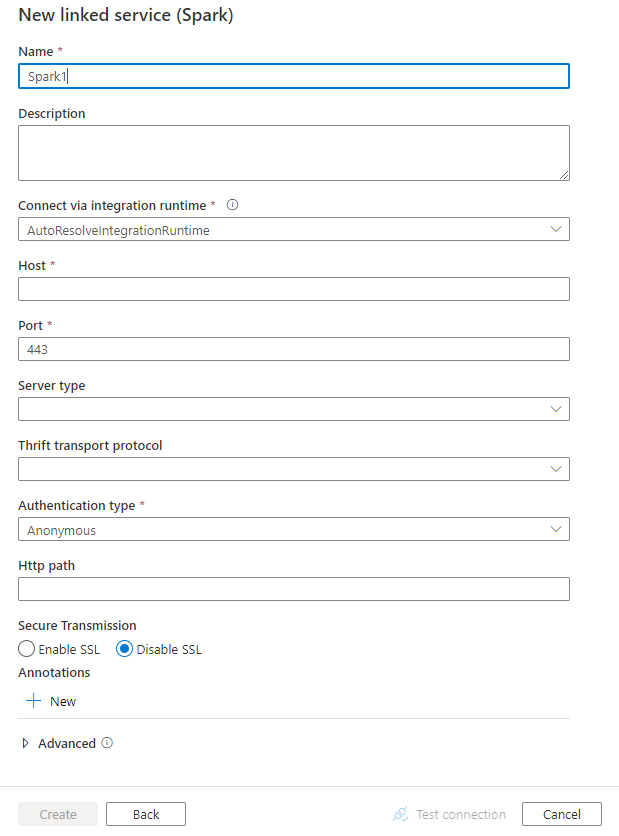
連接器設定詳細資料
下列各節提供屬性的相關詳細資料,這些屬性是用來定義 Spark 連接器專屬的 Data Factory 實體。
連結服務屬性
以下是針對 Spark 已連結服務支援的屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | Type 屬性必須設定為:Spark | Yes |
| host | Spark 伺服器的 IP 位址或主機名稱 | Yes |
| port | Spark 伺服器用來接聽用戶端連線的 TCP 連接埠。 如果您連線到 Azure HDInsights,請將連接埠指定為 443。 | Yes |
| serverType | Spark 伺服器的類型。 允許的值為:SharkServer、SharkServer2、SparkThriftServer |
No |
| thriftTransportProtocol | Thrift 層中使用的傳輸通訊協定。 允許的值為:Binary、SASL、HTTP |
No |
| authenticationType | 用來存取 Spark 伺服器的驗證方法。 允許的值為:Anonymous、UsernameUsernameAndPasswordWindowsAzureHDInsightService |
Yes |
| username | 您用來存取 Spark 伺服器的使用者名稱。 | No |
| password | 對應到使用者的密碼。 將此欄位標記為 SecureString 以便安全儲存,或參考 Azure Key Vault 中儲存的祕密。 | No |
| httpPath | 對應至 Spark 伺服器的部分 URL。 | No |
| enableSsl | 指定是否使用 TLS 加密與伺服器的連線。 預設值為 false。 | No |
| trustedCertPath | .pem 檔案的完整路徑,其中包含在透過 TLS 連線時,用來驗證伺服器的受信任 CA 憑證。 只有在自我裝載 IR 上使用 TLS 時,才能設定這個屬性。 預設值為隨 IR 安裝的 cacerts.pem 檔案。 | No |
| useSystemTrustStore | 指定是否使用來自系統信任存放區或來自指定 PEM 檔案的 CA 憑證。 預設值為 false。 | No |
| allowHostNameCNMismatch | 指定在透過 TLS 連線時,是否要求 CA 所核發的 TLS/SSL 憑證名稱符合伺服器的主機名稱。 預設值為 false。 | No |
| allowSelfSignedServerCert | 指定是否允許來自伺服器的自我簽署憑證。 預設值為 false。 | No |
| connectVia | 用於連線到資料存放區的 Integration Runtime。 深入了解必要條件一節。 如果未指定,就會使用預設的 Azure Integration Runtime。 | No |
範例:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"typeProperties": {
"host" : "<cluster>.azurehdinsight.net",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
資料集屬性
如需可用來定義資料集的區段和屬性完整清單,請參閱資料集一文。 本節提供 Spark 資料集所支援的屬性清單。
若要從 Spark 複製資料,請將資料集的 type 屬性設定為 SparkObject。 以下是支援的屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 資料集的類型屬性必須設為 SparkObject | Yes |
| schema | 結構描述的名稱。 | 否 (如果已指定活動來源中的「查詢」) |
| table | 資料表的名稱。 | 否 (如果已指定活動來源中的「查詢」) |
| tableName | 具有結構描述的資料表名稱。 支援此屬性是基於回溯相容性。 對於新的工作負載,請使用 schema 和 table。 |
否 (如果已指定活動來源中的「查詢」) |
範例
{
"name": "SparkDataset",
"properties": {
"type": "SparkObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Spark linked service name>",
"type": "LinkedServiceReference"
}
}
}
複製活動屬性
如需可用來定義活動的區段和屬性完整清單,請參閱管線一文。 本節提供 Spark 來源所支援的屬性清單。
Spark 作為來源
若要從 Spark 複製資料,請將複製活動中的來源類型設定為 SparkSource。 複製活動的 source 區段支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 複製活動來源的 type 屬性必須設定為:SparkSource | Yes |
| query | 使用自訂 SQL 查詢來讀取資料。 例如: "SELECT * FROM MyTable" 。 |
否 (如果已指定資料集中的 "tableName") |
範例:
"activities":[
{
"name": "CopyFromSpark",
"type": "Copy",
"inputs": [
{
"referenceName": "<Spark input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SparkSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
查閱活動屬性
若要了解屬性的詳細資料,請參閱查閱活動。
相關內容
如需複製活動支援作為來源和接收器的資料存放區清單,請參閱支援的資料存放區。