檢查節點和 Pod 健康情況
本文是一系列文章的一部分。 從概 觀開始。
如果叢集檢查您在上一個步驟中執行的是否清楚,請檢查 Azure Kubernetes Service (AKS) 背景工作節點的健康情況。 請遵循本文中的六個步驟來檢查節點的健康情況、判斷狀況不良節點的原因,以及解決問題。
步驟 1:檢查背景工作節點的健康情況
各種因素都可能導致 AKS 叢集中狀況不良的節點。 其中一個常見原因是控制平面與節點之間的通訊分解。 此錯誤溝通通常是因為路由和防火牆規則中的設定錯誤所造成。
當您為 使用者定義的路由設定 AKS 叢集時,您必須透過網路虛擬設備 (NVA) 或防火牆來設定輸出路徑,例如 Azure 防火牆。 若要解決設定錯誤的問題,建議您根據 AKS 輸出流量指引,設定防火牆以允許必要的埠和完整功能變數名稱 (FQDN)。
狀況不良節點的另一個原因可能是計算、記憶體或記憶體或記憶體資源不足,而造成 kubelet 壓力。 在這種情況下,相應增加資源可以有效地解決問題。
在私人 AKS 叢集中,功能變數名稱系統 (DNS) 解決問題可能會導致控制平面與節點之間的通訊問題。 您必須確認 Kubernetes API 伺服器 DNS 名稱解析為 API 伺服器的私人 IP 位址。 自定義 DNS 伺服器的設定不正確是 DNS 解析失敗的常見原因。 如果您使用自定義 DNS 伺服器,請確定您已在布建節點的虛擬網路上正確地將其指定為 DNS 伺服器。 也請確認 AKS 私人 API 伺服器可以透過自訂 DNS 伺服器解析。
解決與控制平面通訊和 DNS 解析相關的這些潛在問題之後,您可以有效地解決 AKS 叢集中的節點健康情況問題。
您可以使用下列其中一種方法來評估節點的健康情況。
Azure 監視器容器健康情況檢視
若要檢視 AKS 叢集中節點、使用者 Pod 和系統 Pod 的健康情況,請遵循下列步驟:
- 在 Azure 入口網站 中,移至 Azure 監視器。
- 在瀏覽窗格的 [ 深入解析 ] 區段中,選取 [ 容器]。
- 針對要監視的 AKS 叢集清單,選取 [受監視的叢集 ]。
- 從清單中選擇 AKS 叢集,以檢視節點、使用者 Pod 和系統 Pod 的健康情況。

AKS 節點檢視
為了確保 AKS 叢集中的所有節點都處於就緒狀態,請遵循下列步驟:
- 在 Azure 入口網站 中,移至您的 AKS 叢集。
- 在瀏覽窗格的 [設定] 區段中,選取 [節點集區]。
- 選取 [ 節點]。
- 確認所有節點都處於就緒狀態。

使用 Prometheus 和 Grafana 進行叢集內監視
如果您在 AKS 叢集中部署 Prometheus 和 Grafana ,您可以使用 K8 叢集詳細數據儀錶板 來取得見解。 此儀錶板會顯示 Prometheus 叢集計量,並提供重要資訊,例如 CPU 使用量、記憶體使用量、網路活動和文件系統使用量。 它也會顯示個別 Pod、容器和 系統服務 的詳細統計數據。
在儀錶板中,選取 [節點條件 ] 以查看叢集健康情況和效能的相關計量。 您可以追蹤可能有問題的節點,例如其排程、網路、磁碟壓力、記憶體壓力、比例整數衍生 (PID) 壓力或磁碟空間的問題。 監視這些計量,以便主動識別並解決任何影響 AKS 叢集可用性和效能的潛在問題。

監視 Prometheus 和 Azure Managed Grafana 的受控服務
您可以使用預先建置的儀錶板來可視化和分析 Prometheus 計量。 若要這樣做,您必須設定 AKS 叢集,以在 Prometheus 的監視受控服務中 收集 Prometheus 計量,並將您的 監視器工作區 連線到 Azure 受控 Grafana 工作區。 這些儀錶板 提供 Kubernetes 叢集效能和健康情況的完整檢視。
儀錶板會布建在Managed Prometheus資料夾中的指定 Azure 受控 Grafana 實例中。 某些儀錶板包括:
- Kubernetes / 計算資源 / 叢集
- Kubernetes / 計算資源 / 命名空間 (Pods)
- Kubernetes / 計算資源 / 節點 (Pods)
- Kubernetes / 計算資源 / Pod
- Kubernetes / 計算資源 / 命名空間 (工作負載)
- Kubernetes / 計算資源 / 工作負載
- Kubernetes / Kubelet
- 節點匯出工具/USE 方法/節點
- 節點匯出工具/節點
- Kubernetes / 計算資源 / 叢集 (Windows)
- Kubernetes / 計算資源 / 命名空間 (Windows)
- Kubernetes / 計算資源 / Pod (Windows)
- Kubernetes / USE 方法 / 叢集 (Windows)
- Kubernetes / USE 方法 / 節點 (Windows)
這些內建儀錶板廣泛用於開放原始碼社群,以使用 Prometheus 和 Grafana 監視 Kubernetes 叢集。 使用這些儀錶板來查看計量,例如資源使用量、Pod 健康情況和網路活動。 您也可以建立專為監視需求量身打造的自訂儀錶板。 儀錶板可協助您有效地監視和分析 AKS 叢集中的 Prometheus 計量,這可讓您優化效能、疑難解答問題,並確保 Kubernetes 工作負載的順暢作業。
您可以使用 Kubernetes/ Compute Resources / Node (Pods) 儀錶板來查看 Linux 代理程序節點的計量。 您可以將每個 Pod 的 CPU 使用量、CPU 配額、記憶體使用量和記憶體配額可視化。

如果您的叢集包含 Windows 代理程式節點,您可以使用 Kubernetes /USE 方法/節點 /節點 (Windows) 儀錶板,將收集自這些節點的 Prometheus 計量可視化。 此儀錶板提供叢集中 Windows 節點資源耗用量和效能的完整檢視。
利用這些專用儀錶板,讓您可以輕鬆地監視和分析 Linux 和 Windows 代理程式節點中 CPU、記憶體和其他資源相關的重要計量。 此可見度可讓您識別潛在的瓶頸、優化資源配置,並確保 AKS 叢集間有效率的作業。
步驟 2:確認控制平面和背景工作節點連線能力
如果背景工作節點狀況良好,您應該檢查受控 AKS 控制平面與叢集背景工作角色節點之間的連線。 AKS 可透過安全通道通訊方法,啟用 Kubernetes API 伺服器與個別節點 Kubelets 之間的通訊。 即使這些元件位於不同的虛擬網路上,這些元件仍可進行通訊。 通道會受到相互傳輸層安全性 (mTLS) 加密的保護。 AKS 使用的主要通道稱為 Konnectivity(先前稱為 apiserver-network-proxy)。 請確定所有網路規則和 FQDN 都符合必要的 Azure 網路規則。
若要確認受控 AKS 控制平面與 AKS 叢集的叢集背景工作節點之間的連線,您可以使用 kubectl 命令行工具。
若要確保 Konnectivity 代理程式 Pod 正常運作,請執行下列命令:
kubectl get deploy konnectivity-agent -n kube-system
請確定Pod處於就緒狀態。
如果控制平面與背景工作節點之間的連線發生問題,請在確定允許必要的 AKS 輸出流量規則之後建立連線。
執行下列命令以重新啟動 konnectivity-agent Pod:
kubectl rollout restart deploy konnectivity-agent -n kube-system
如果重新啟動Pod未修正連線,請檢查記錄是否有任何異常狀況。 執行下列命令以檢視 Pod 的 konnectivity-agent 記錄:
kubectl logs -l app=konnectivity-agent -n kube-system --tail=50
記錄應該會顯示下列輸出:
I1012 12:27:43.521795 1 options.go:102] AgentCert set to "/certs/client.crt".
I1012 12:27:43.521831 1 options.go:103] AgentKey set to "/certs/client.key".
I1012 12:27:43.521834 1 options.go:104] CACert set to "/certs/ca.crt".
I1012 12:27:43.521837 1 options.go:105] ProxyServerHost set to "sethaks-47983508.hcp.switzerlandnorth.azmk8s.io".
I1012 12:27:43.521841 1 options.go:106] ProxyServerPort set to 443.
I1012 12:27:43.521844 1 options.go:107] ALPNProtos set to [konnectivity].
I1012 12:27:43.521851 1 options.go:108] HealthServerHost set to
I1012 12:27:43.521948 1 options.go:109] HealthServerPort set to 8082.
I1012 12:27:43.521956 1 options.go:110] AdminServerPort set to 8094.
I1012 12:27:43.521959 1 options.go:111] EnableProfiling set to false.
I1012 12:27:43.521962 1 options.go:112] EnableContentionProfiling set to false.
I1012 12:27:43.521965 1 options.go:113] AgentID set to b7f3182c-995e-4364-aa0a-d569084244e4.
I1012 12:27:43.521967 1 options.go:114] SyncInterval set to 1s.
I1012 12:27:43.521972 1 options.go:115] ProbeInterval set to 1s.
I1012 12:27:43.521980 1 options.go:116] SyncIntervalCap set to 10s.
I1012 12:27:43.522020 1 options.go:117] Keepalive time set to 30s.
I1012 12:27:43.522042 1 options.go:118] ServiceAccountTokenPath set to "".
I1012 12:27:43.522059 1 options.go:119] AgentIdentifiers set to .
I1012 12:27:43.522083 1 options.go:120] WarnOnChannelLimit set to false.
I1012 12:27:43.522104 1 options.go:121] SyncForever set to false.
I1012 12:27:43.567902 1 client.go:255] "Connect to" server="e9df3653-9bd4-4b09-b1a7-261f6104f5d0"
注意
使用 API 伺服器虛擬網路整合和 Azure 容器網路介面 (CNI) 或具有動態 Pod IP 指派的 Azure CNI 來設定 AKS 叢集時,就不需要部署 Konnectivity 代理程式。 整合式 API 伺服器 Pod 可以透過專用網與叢集背景工作角色節點建立直接通訊。
不過,當您使用 API 伺服器虛擬網路與 Azure CNI 重疊或自備 CNI(BYOCNI)整合時,會部署 Konnectivity 來促進 API 伺服器與 Pod IP 之間的通訊。 API 伺服器與背景工作節點之間的通訊會保持直接。
您也可以在記錄和監視服務中搜尋容器記錄,以擷取記錄。 如需搜尋 aks-link 連線錯誤的範例,請參閱 從容器深入解析查詢記錄。
執行下列查詢以擷取記錄:
ContainerLogV2
| where _ResourceId =~ "/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.ContainerService/managedClusters/<cluster-ID>" // Use the IDs and names of your resources for these values.
| where ContainerName has "aks-link"
| project LogSource,LogMessage, TimeGenerated, Computer, PodName, ContainerName, ContainerId
| order by TimeGenerated desc
| limit 200
執行下列查詢來搜尋特定命名空間中任何失敗 Pod 的容器記錄:
let KubePodInv = KubePodInventory
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where _ResourceId =~ "<cluster-resource-ID>" // Use your resource ID for this value.
| where Namespace == "<pod-namespace>" // Use your target namespace for this value.
| where PodStatus == "Failed"
| extend ContainerId = ContainerID
| summarize arg_max(TimeGenerated, *) by ContainerId, PodStatus, ContainerStatus
| project ContainerId, PodStatus, ContainerStatus;
KubePodInv
| join
(
ContainerLogV2
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where PodNamespace == "<pod-namespace>" //update with target namespace
) on ContainerId
| project TimeGenerated, PodName, PodStatus, ContainerName, ContainerId, ContainerStatus, LogMessage, LogSource
如果您無法使用查詢或 kubectl 工具取得記錄,請使用 安全殼層 (SSH) 驗證。 此範例會 透過 SSH 連線到節點之後,尋找通道 Pod 。
kubectl pods -n kube-system -o wide | grep tunnelfront
ssh azureuser@<agent node pod is on, output from step above>
docker ps | grep tunnelfront
docker logs …
nslookup <ssh-server_fqdn>
ssh -vv azureuser@<ssh-server_fqdn> -p 9000
docker exec -it <tunnelfront_container_id> /bin/bash -c "ping bing.com"
kubectl get pods -n kube-system -o wide | grep <agent_node_where_tunnelfront_is_running>
kubectl delete po <kube_proxy_pod> -n kube-system
步驟 3:限制輸出時驗證 DNS 解析
DNS 解析是 AKS 叢集的重要層面。 如果 DNS 解析無法正常運作,可能會導致控制平面錯誤或容器映射提取失敗。 若要確保 Kubernetes API 伺服器的 DNS 解析正常運作,請遵循下列步驟:
執行 kubectl exec 命令,以在 Pod 中執行的容器中開啟命令殼層。
kubectl exec --stdin --tty your-pod --namespace <namespace-name> -- /bin/bash檢查是否已在容器中安裝 nslookup 或 dig 工具。
如果 Pod 中未安裝這兩個工具,請執行下列命令,以在相同的命名空間中建立公用程式 Pod。
kubectl run -i --tty busybox --image=busybox --namespace <namespace-name> --rm=true -- sh您可以從 Azure 入口網站 中 AKS 叢集的概觀頁面擷取 API 伺服器位址,也可以執行下列命令。
az aks show --name <aks-name> --resource-group <resource-group-name> --query fqdn --output tsv執行下列命令以嘗試解析 AKS API 伺服器。 如需詳細資訊,請參閱 針對 Pod 內部的 DNS 解析失敗進行疑難解答,而不是從背景工作節點進行疑難解答。
nslookup myaks-47983508.hcp.westeurope.azmk8s.io檢查 Pod 中的上游 DNS 伺服器,以判斷 DNS 解析是否正常運作。 例如,針對 Azure DNS,請執行
nslookup命令。nslookup microsoft.com 168.63.129.16如果先前的步驟未提供深入解析, 請連線到其中一個背景工作節點,然後嘗試從節點進行 DNS 解析。 此步驟有助於識別問題與 AKS 或網路設定有關。
如果 DNS 解析從節點成功,但不是來自 Pod,問題可能與 Kubernetes DNS 相關。 如需從 Pod 對 DNS 解析進行偵錯的步驟,請參閱 針對 DNS 解析失敗進行疑難解答。
如果節點的 DNS 解析失敗,請檢閱網路設定,以確保已開啟適當的路由路徑和埠,以協助 DNS 解析。
步驟 4:檢查 kubelet 錯誤
確認在每一個背景工作節點上執行的 kubelet 程式條件,並確定它沒有任何壓力。 潛在的壓力可能與 CPU、記憶體或記憶體有關。 若要確認個別節點 kubelets 的狀態,您可以使用下列其中一種方法。
AKS kubelet 活頁簿
若要確保代理程序節點 kubelets 正常運作,請遵循下列步驟:
移至 Azure 入口網站 中的 AKS 叢集。
在瀏覽窗格的 [ 監視] 區段中,選取 [ 活頁簿]。
選取 Kubelet 活頁簿。
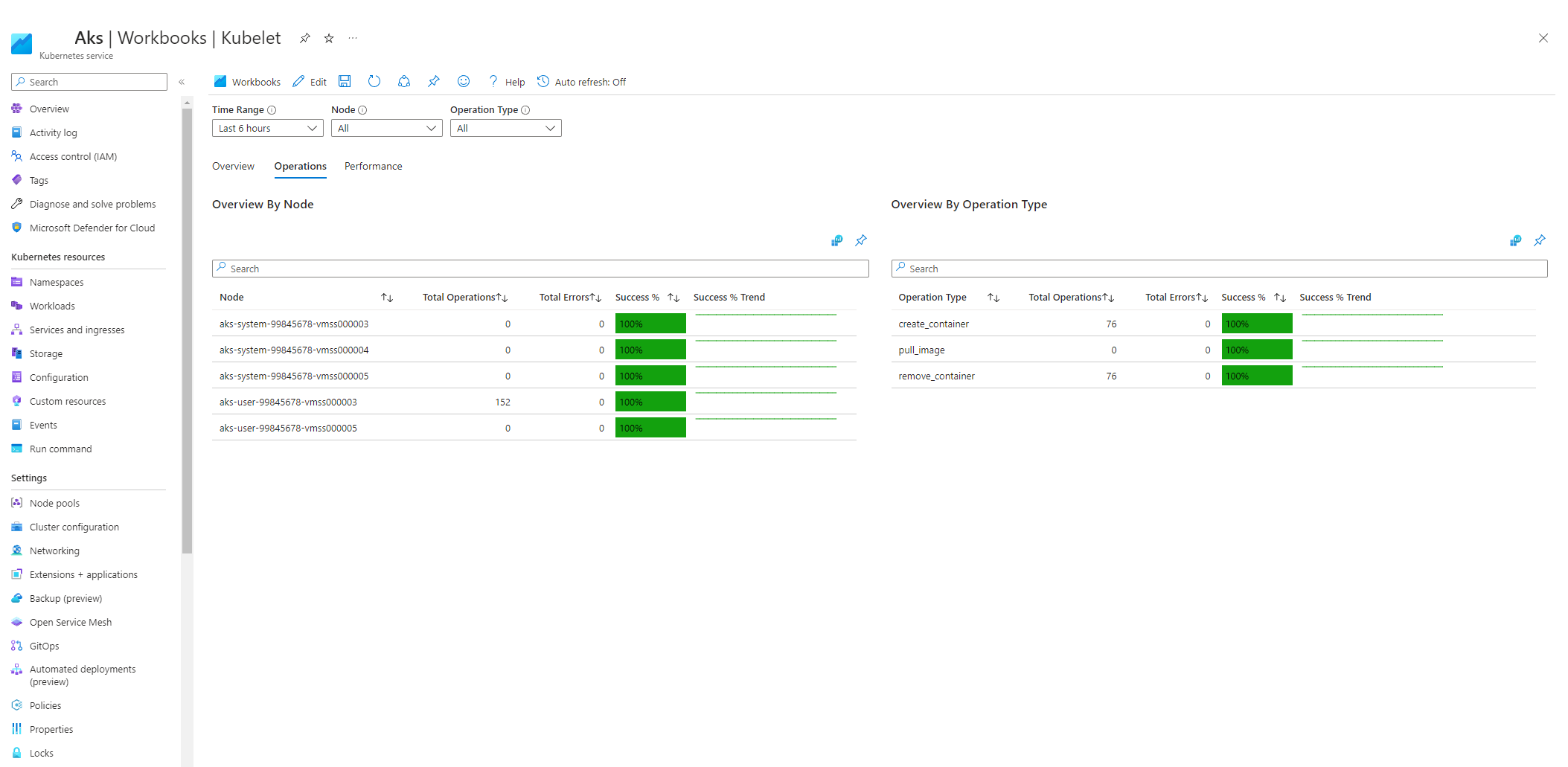
選取 [作業 ],並確定所有背景工作節點的作業都已完成。


使用 Prometheus 和 Grafana 進行叢集內監視
如果您在 AKS 叢集中部署 Prometheus 和 Grafana ,您可以使用 Kubernetes / Kubelet 儀錶板來取得個別節點 Kubelets 健康情況和效能的深入解析。

監視 Prometheus 和 Azure Managed Grafana 的受控服務
您可以使用 Kubernetes / Kubelet 預先建置的儀錶板,將背景工作節點 Kubelets 的 Prometheus 計量可視化和分析。 若要這樣做,您必須設定 AKS 叢集,以在 Prometheus 的監視受控服務中 收集 Prometheus 計量,並將您的 監視器工作區 連線到 Azure 受控 Grafana 工作區。

當 kubelet 重新啟動並造成零星、無法預測的行為時,壓力就會增加。 請確定錯誤計數不會持續成長。 偶爾會發生錯誤,但常數成長表示您必須調查並解決的基礎問題。
步驟 5:使用節點問題偵測器 (NPD) 工具來檢查節點健康情況
NPD 是 Kubernetes 工具,可用來識別和報告節點相關問題。 它會在叢集內的每個節點上以系統服務的形式運作。 它會收集計量和系統資訊,例如CPU使用量、磁碟使用量和網路連線狀態。 偵測到問題時,NPD 工具會產生事件和節點條件的報告。 在 AKS 中,NPD 工具可用來監視和管理裝載於 Azure 雲端的 Kubernetes 叢集中的節點。 如需詳細資訊,請參閱 AKS 節點中的 NPD。
步驟 6:檢查每秒的磁碟 I/O 作業 (IOPS) 以進行節流
若要確保 IOPS 不會受到節流,並影響 AKS 叢集內的服務和工作負載,您可以使用下列其中一種方法。
AKS 節點磁碟 I/O 活頁簿
若要監視 AKS 叢集中背景工作節點的磁碟 I/O 相關計量,您可以使用 節點磁碟 I/O 活頁簿。 請遵循下列步驟來存取活頁簿:
移至 Azure 入口網站 中的 AKS 叢集。
在瀏覽窗格的 [ 監視] 區段中,選取 [ 活頁簿]。
選取 [節點磁碟 IO] 活頁簿。
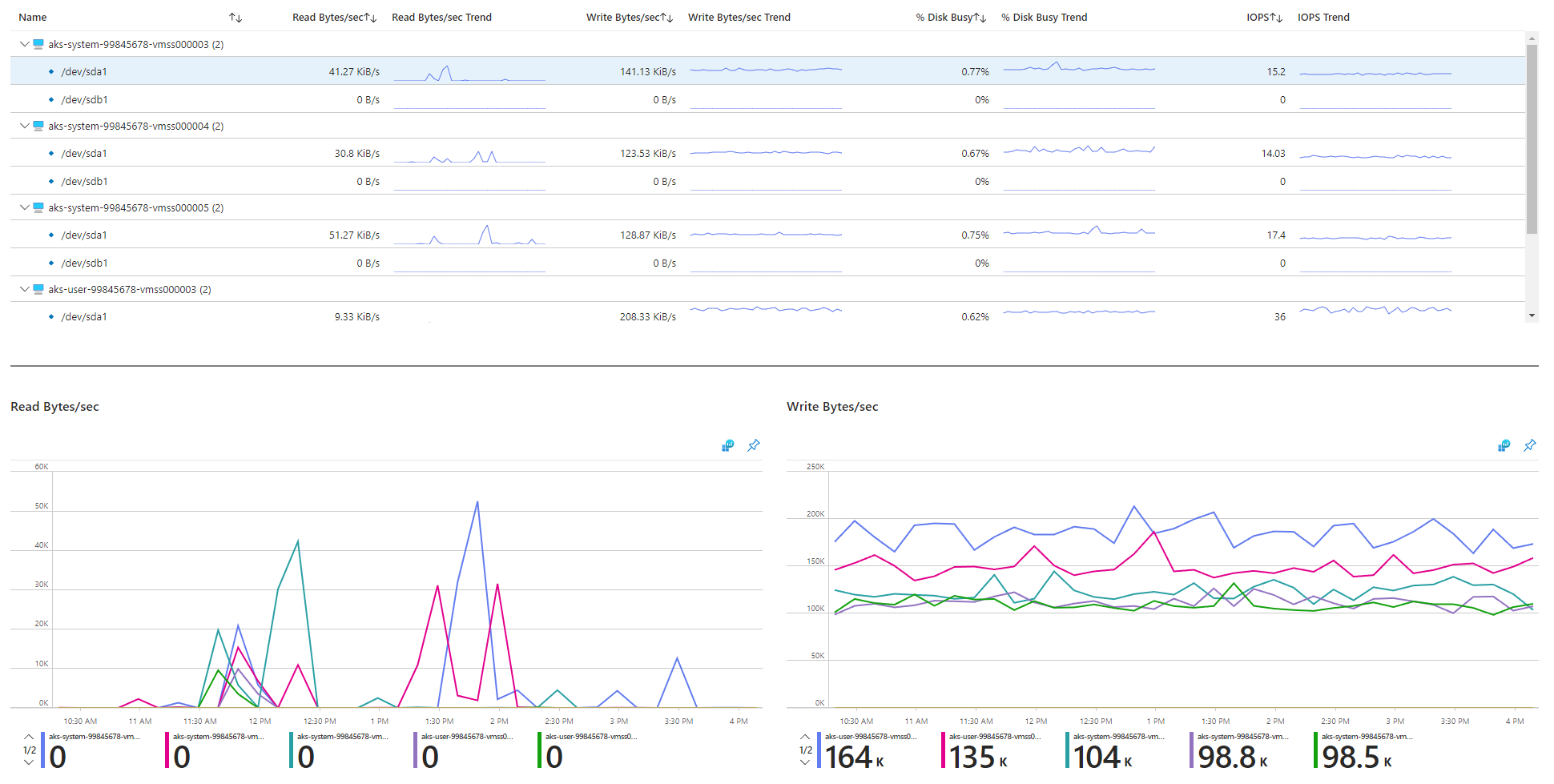
檢閱 I/O 相關計量。


使用 Prometheus 和 Grafana 進行叢集內監視
如果您在 AKS 叢集中部署 Prometheus 和 Grafana,您可以使用 USE 方法/節點儀錶板來取得叢集背景工作節點磁碟 I/O 的深入解析。

監視 Prometheus 和 Azure Managed Grafana 的受控服務
您可以使用 節點匯出工具/節點 預先建置的儀錶板,從背景工作節點可視化和分析磁碟 I/O 相關計量。 若要這樣做,您必須設定 AKS 叢集,以在 Prometheus 的監視受控服務中 收集 Prometheus 計量,並將您的 監視器工作區 連線到 Azure 受控 Grafana 工作區。

IOPS 和 Azure 磁碟
實體存儲設備在頻寬和可處理的檔案作業數目上限方面具有固有的限制。 Azure 磁碟可用來儲存在 AKS 節點上執行的作業系統。 磁碟受限於與作業系統相同的實體記憶體限制。
請考慮輸送量的概念。 您可以將平均 I/O 大小乘以 IOPS,以每秒 MB 為單位來判斷輸送量(MBps)。 較大的 I/O 大小會因為磁碟的固定輸送量而轉譯為較低的 IOPS。
當工作負載超過指派給 Azure 磁碟的最大 IOPS 服務限制時,叢集可能會變得沒有回應,並進入 I/O 等候狀態。 在以Linux為基礎的系統中,許多元件都會被視為檔案,例如網路套接字、CNI、Docker 和其他依賴網路 I/O 的服務。 因此,如果無法讀取磁碟,失敗會延伸到所有這些檔案。
數個事件和案例可以觸發 IOPS 節流,包括:
大量在節點上執行的容器,因為 Docker I/O 會共用作業系統磁碟。
用於安全性、監視和記錄的自定義或第三方工具,這可能會在操作系統磁碟上產生額外的 I/O 作業。
加強工作負載或調整Pod數目的節點故障轉移事件和定期作業。 此增加的負載會增加節流發生的可能性,這可能會導致所有節點在 I/O 作業結束前轉換為 尚未就緒 的狀態。
參與者
本文由 Microsoft 維護。 原始投稿人如下。
主要作者:
- Paolo Salvatori |首席客戶工程師
- 弗朗西斯·西米·納扎雷斯 |資深技術專家
若要查看非公用LinkedIn配置檔,請登入LinkedIn。