監視已部署的提示流程應用程式的品質和權杖使用方式
重要
本文中標示為 (預覽) 的項目目前處於公開預覽狀態。 此預覽版本沒有服務等級協定,不建議將其用於生產工作負載。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
監視部署到生產的應用程式是生成式 AI 應用程式生命週期的不可或缺的一部分。 資料與取用者行為的變更可能會隨著時間來影響您的應用程式,導致過時的系統對業務成果產生負面影響,並讓組織面臨合規性、經濟和信譽風險。
注意
如需執行已部署應用程式持續監視(非提示流程)的改良方式,請考慮使用 Azure AI 在線評估。
適用於產生 AI 應用程式的 Azure AI 監視可讓您監視生產環境中的應用程式,以取得權杖使用方式、產生品質和作業計量。
監視提示流程部署的整合可讓您:
- 從已部署的提示流程應用程式收集生產推斷資料。
- 套用負責任的 AI 評估計量 (例如根據性、連貫性、流暢度和相關性),這些計量可與提示流程評估計量交互作用。
- 監視提示流程中每個模型部署的提示、完成和權杖使用量總計。
- 監視作業計量,例如要求計數、延遲和錯誤率。
- 使用預先設定的警示和預設值,以定期執行監視。
- 取用數據視覺效果,並在 Azure AI Foundry 入口網站中設定進階行為。
必要條件
遵循本文中的步驟之前,請確定您已滿足下列必要條件:
具有有效付款方式的 Azure 訂用帳戶。 免費或試用版 Azure 訂用帳戶不適用此案例。 如果您沒有 Azure 訂用帳戶,請建立付費 Azure 帳戶以開始。
備妥提示流程以進行部署。 如果您沒有提示流程,請參閱開發提示流程。
Azure 角色型訪問控制 (Azure RBAC) 可用來授與 Azure AI Foundry 入口網站中作業的存取權。 若要執行本文中的步驟,您的使用者帳戶必須獲派資源群組上的 Azure AI 開發人員角色。 如需許可權的詳細資訊,請參閱 Azure AI Foundry 入口網站中的角色型訪問控制。
監視計量的需求
監視計量是由以特定評估指示 (提示範本) 設定的某些最先進 GPT 語言模型所產生。 這些模型可作為序列到序列工作的評估工具模型。 相較於標準生成式 AI 評估計量,使用這項技術來產生監視計量會顯示強式的經驗結果,並與人類判斷高度相互關聯。 如需提示流程評估的詳細資訊,請參閱提交大量測試並評估流程以及用於生成式 AI 的評估和監視計量。
產生監視計量的 GPT 模型如下所示。 支援以下這些 GPT 模型進行監視並設定為您的 Azure OpenAI 資源:
- GPT-3.5 Turbo
- GPT-4
- GPT-4-32k
支援的監視計量
支援監視以下計量:
| 計量 | 描述 |
|---|---|
| 根據性 | 測量模型產生的答案與來源資料 (使用者定義的內容) 中資訊的相符程度。 |
| 相關性 | 測量模型所產生回應與指定問題相關和直接相關的程度。 |
| 連貫性 | 測量模型產生的回應在邏輯上一致和關聯的程度。 |
| 流暢度 | 測量生成式 AI 預測答案的文法熟練度。 |
資料行名稱對應
建立流程時,您必須確定資料行名稱已對應。 以下輸入資料的資料行名稱可用來測量生成的安全性和品質:
| 輸入資料行名稱 | 定義 | 必要/選用 |
|---|---|---|
| 詢問問題 | 提供的原始提示 (也稱為「輸入」或「問題」) | 必要 |
| 回答 | 傳回的 API 呼叫最終完成項目 (也稱為「輸出」或「答案」) | 必要 |
| 上下文 | 與原始提示一起傳送至 API 呼叫的任何內容資料。 例如,如果您想要只從特定認證資訊來源或網站取得搜尋結果,您可以在評估步驟中定義此內容。 | 選擇性 |
計量所需的參數
資料資產中設定的參數會根據下表決定您可以產生的計量:
| 計量 | 問題 | 回答 | 上下文 |
|---|---|---|---|
| 連貫性 | 必要 | 必要 | - |
| 流暢度 | 必要 | 必要 | - |
| 根據性 | 必要 | 必要 | 必要 |
| 相關性 | 必要 | 必要 | 必要 |
如需每個計量之特定數據對應需求的詳細資訊,請參閱 查詢和回應計量需求。
設定對提示流程的監視
若要設定提示流程應用程式的監視,必須先使用推斷資料收集來部署提示流程應用程式,然後可以設定已部署應用程式的監視。
使用推斷資料收集來部署提示流程應用程式
在本區段中,您會了解如何部署提示流程,並啟用推斷資料收集。 如需部署提示流程的詳細資訊,請參閱部署流程以進行即時推斷。
登入 Azure AI Foundry。
如果您尚未在專案中,請選取它。
從左側導覽列選取 [提示流程 ]。
選取您先前建立的提示流程。
注意
本文假設您已建立可供部署的提示流程。 如果您沒有提示流程,請參閱開發提示流程。
確認您的流程執行成功,並針對您想要評估的計量設定了必要的輸入和輸出。
提供最低必要參數 (問題/輸入和答案/輸出) 只提供兩個計量:連貫性和流暢性。 您必須設定流程,如監視計量需求一節中所述。 此範例使用、
question(問題) 和chat_history(內容) 作為流程輸入,以及answer(答案) 作為流程輸出。選取 [部署] 開始部署流程。
![[部署] 按鈕的提示流程編輯器的螢幕擷取畫面。](../media/deploy-monitor/monitor/user-experience.png)
在部署視窗中,確定已啟用 [推斷資料收集],這會順暢地將應用程式的推斷資料收集到 Blob 儲存體。 監視必須有此資料收集。
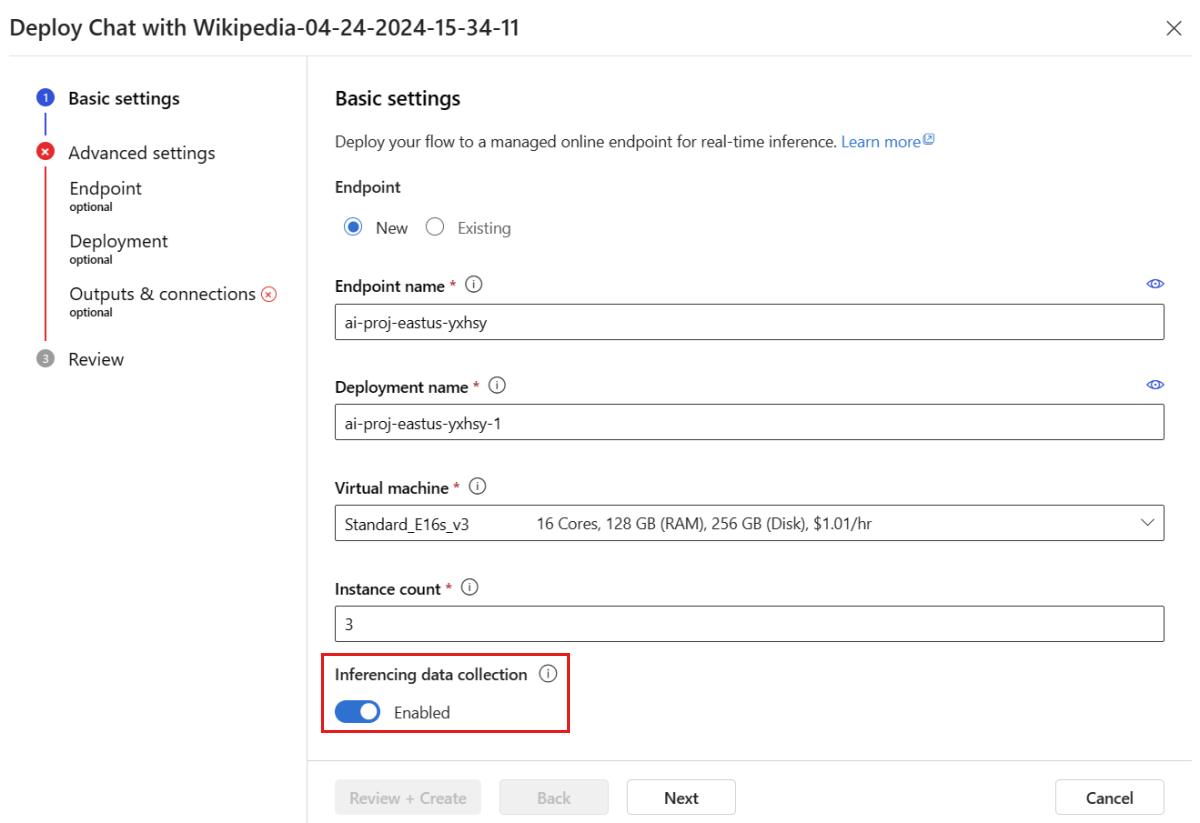
繼續執行部署視窗中的步驟,以完成 [進階設定]。
在 [檢閱] 頁面上,檢閱部署設定,然後選取 [建立] 以部署流程。

注意
根據預設,所有已部署提示流程應用程式的輸入和輸出,都會收集到您的 Blob 儲存體。 當使用者叫用部署時,會收集要供監視使用的資料。
選取部署頁面上的 [測試] 索引標籤,並測試您的部署以確保其正常運作。
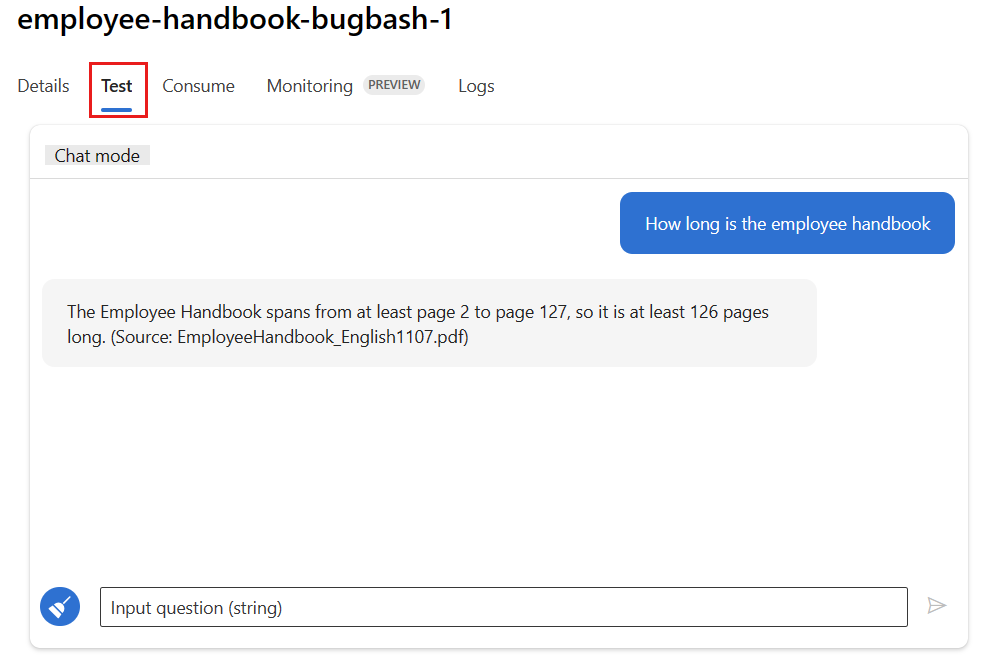
注意
監視要求至少有一個資料點來自部署中 [測試] 索引標籤以外的來源。 建議您使用 [取用] 索引標籤中提供的 REST API,將範例要求傳送至您的部署。 如需如何將範例要求傳送至部署的詳細資訊,請參閱建立線上部署。
![[部署] 按鈕的提示流程編輯器的螢幕擷取畫面。](../media/deploy-monitor/monitor/user-experience.png#lightbox)



設定監視
在本節中,您將了解如何設定已部署提示流程應用程式的監視。
從左側導覽列中,移至 [我的資產>模型 + 端點]。
選取您所建立的提示流程部署。
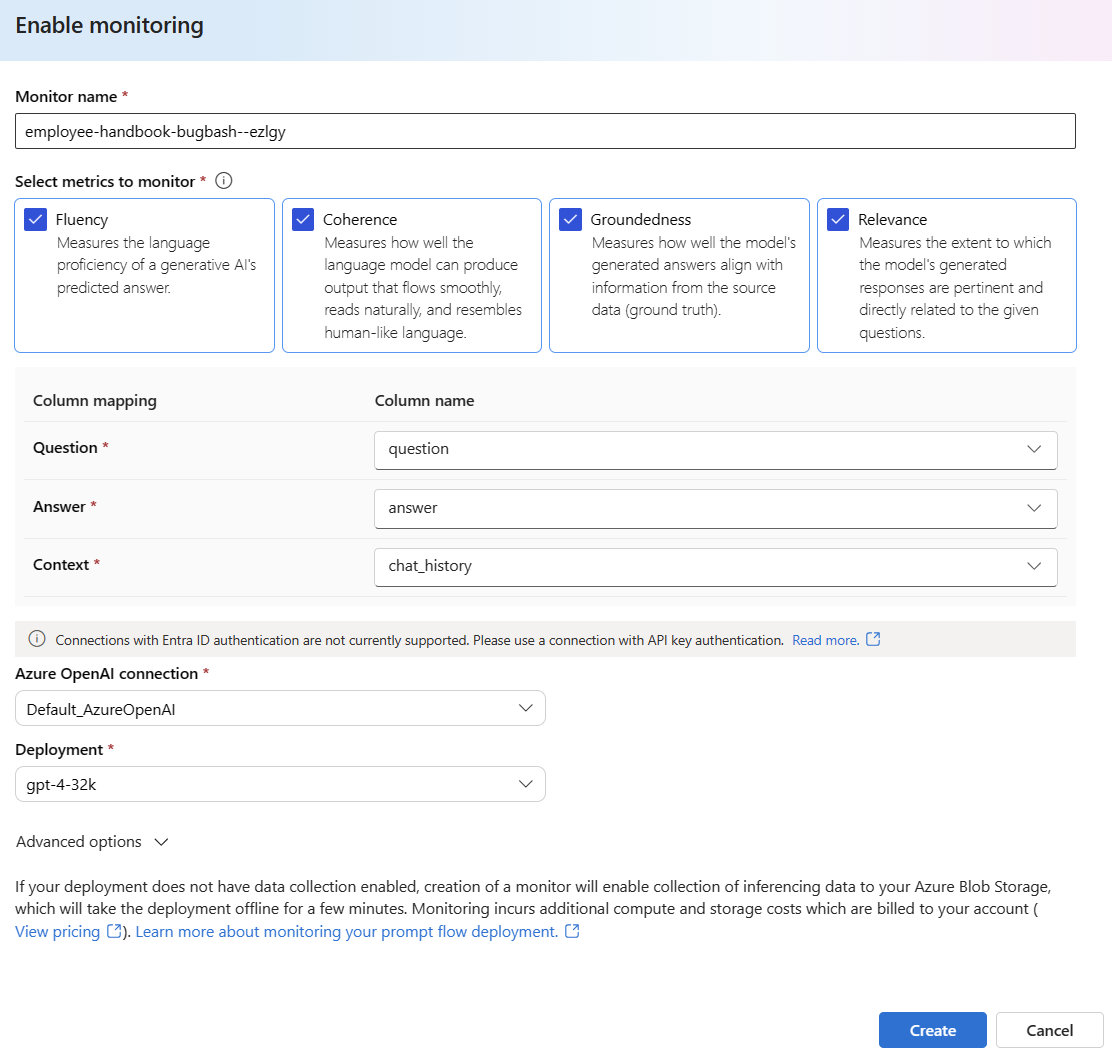
在 [啟用產生品質監視] 方塊中選取 [啟用]。

選取所需的計量,以開始設定監視。
確認您的資料行名稱已從流程中對應,如資料行名稱對應中所定義。
選取您想用來執行提示流程應用程式之監視的 [Azure OpenAI 連線] 和 [部署]。
選取 [進階選項],以查看更多要設定的選項。
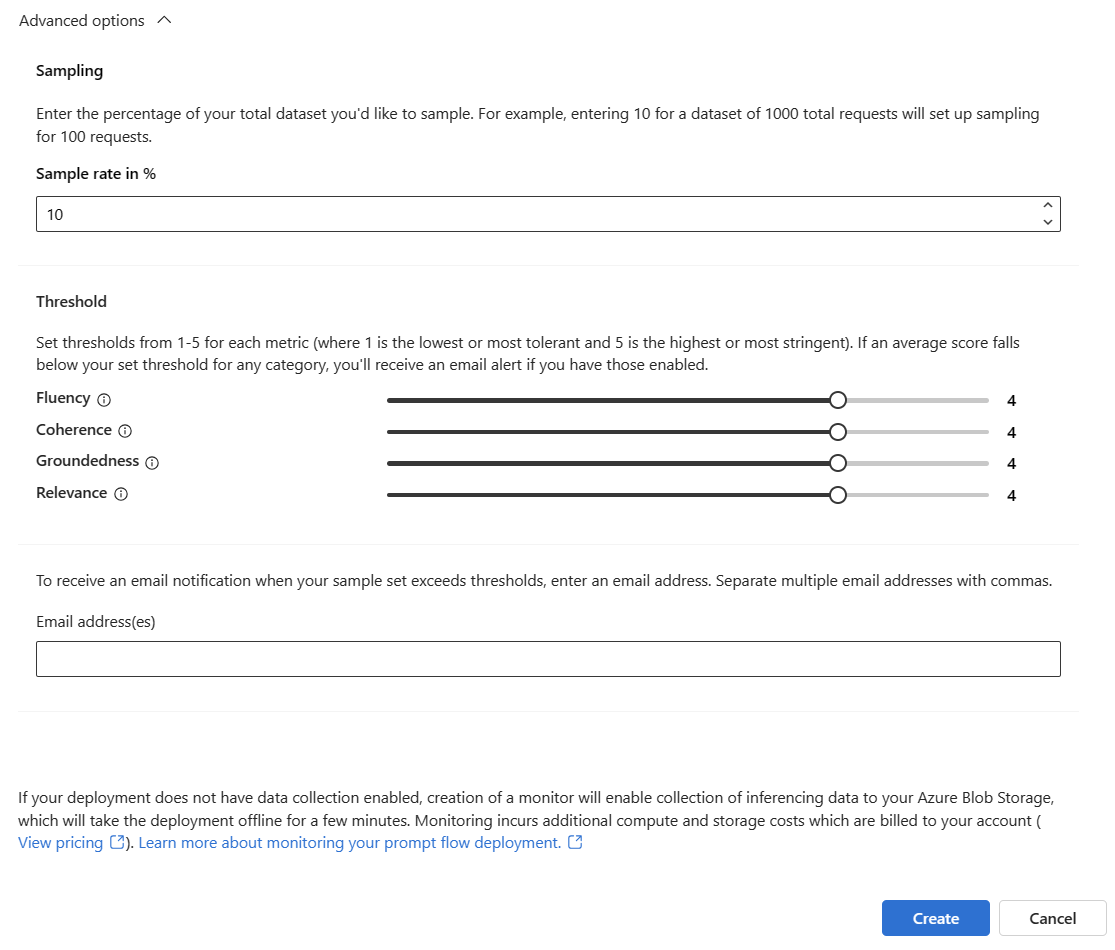
調整取樣率、設定計量的閾值,並且當某個指定計量的平均分數低於閾值時,指定應接收警示的電子郵件地址。
注意
如果您的部署未啟用資料收集,則建立監視器會啟用將推斷資料收集到 Azure Blob 儲存體的功能,這會讓部署離線幾分鐘。
選取 [建立] 以建立您的監視器。



取用監視結果
建立監視器之後,監視器會每天執行,以計算權杖使用量和產生品質計量。
從部署內移至 [監視 (預覽)] 索引標籤,以檢視監視結果。 您可以在此看到所選時間範圍期間的監視結果概觀。 您可以使用日期選擇器來變更您所監視的資料時間範圍。 在此概觀中可取得下列計量:
- 要求的總數:在所選時間範圍內傳送至部署的要求總數。
- 權杖總數:在所選時間範圍內部署使用的權杖總數。
- 提示權杖計數:在所選時間範圍內部署使用的提示權杖數目。
- 完成權杖計數:在所選時間範圍內部署使用的完成權杖數目。
在 [權杖使用方式] 索引標籤中檢視計量 (預設會選取此索引標籤)。 您可以在此檢視應用程式一段時間的權杖使用方式。 也可以檢視一段時間的提示和完成權杖分佈。 您可以變更趨勢線範圍,以監視整個應用程式中的所有權杖,或應用程式內使用特定部署 (例如,gpt-4) 的權杖使用方式。
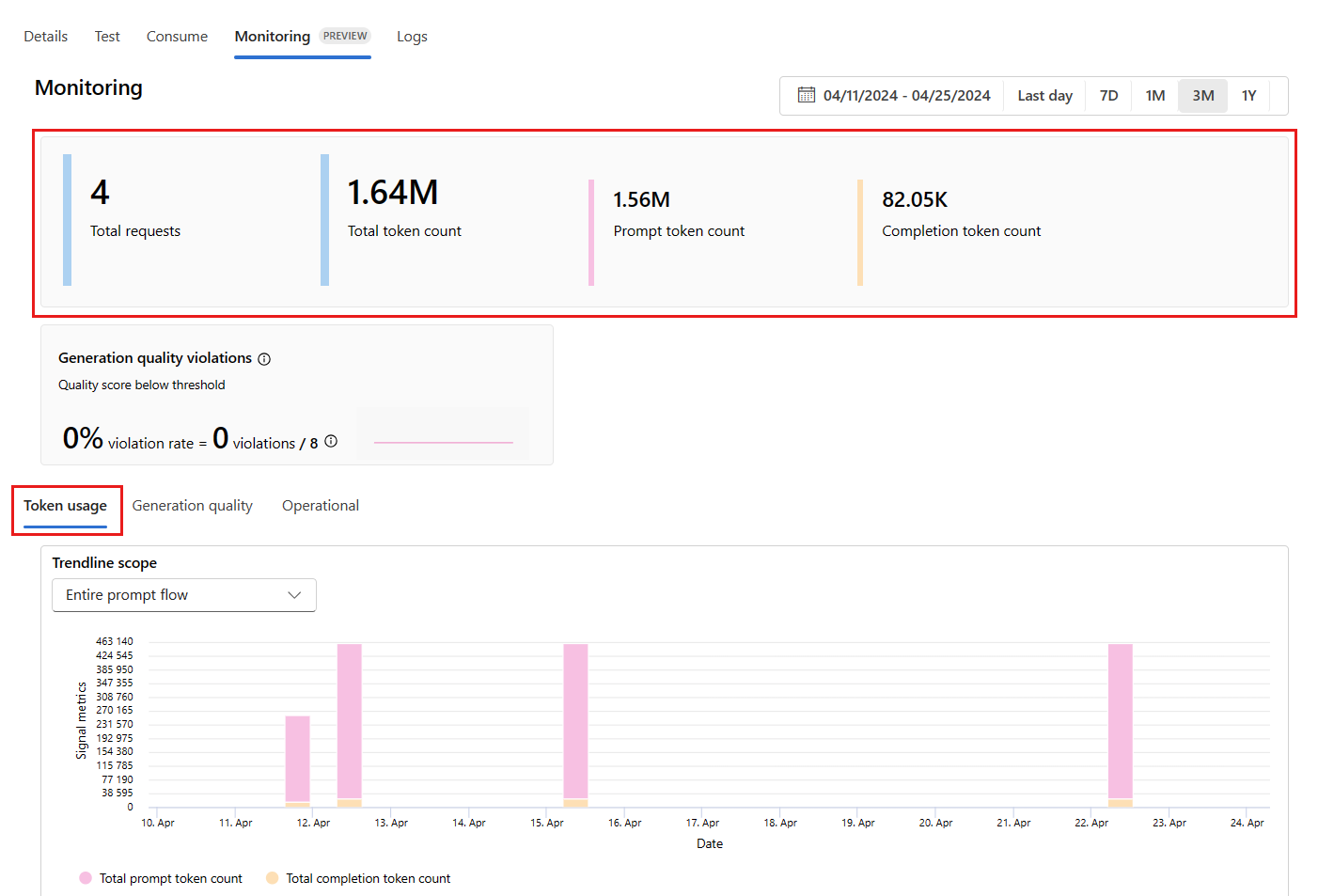
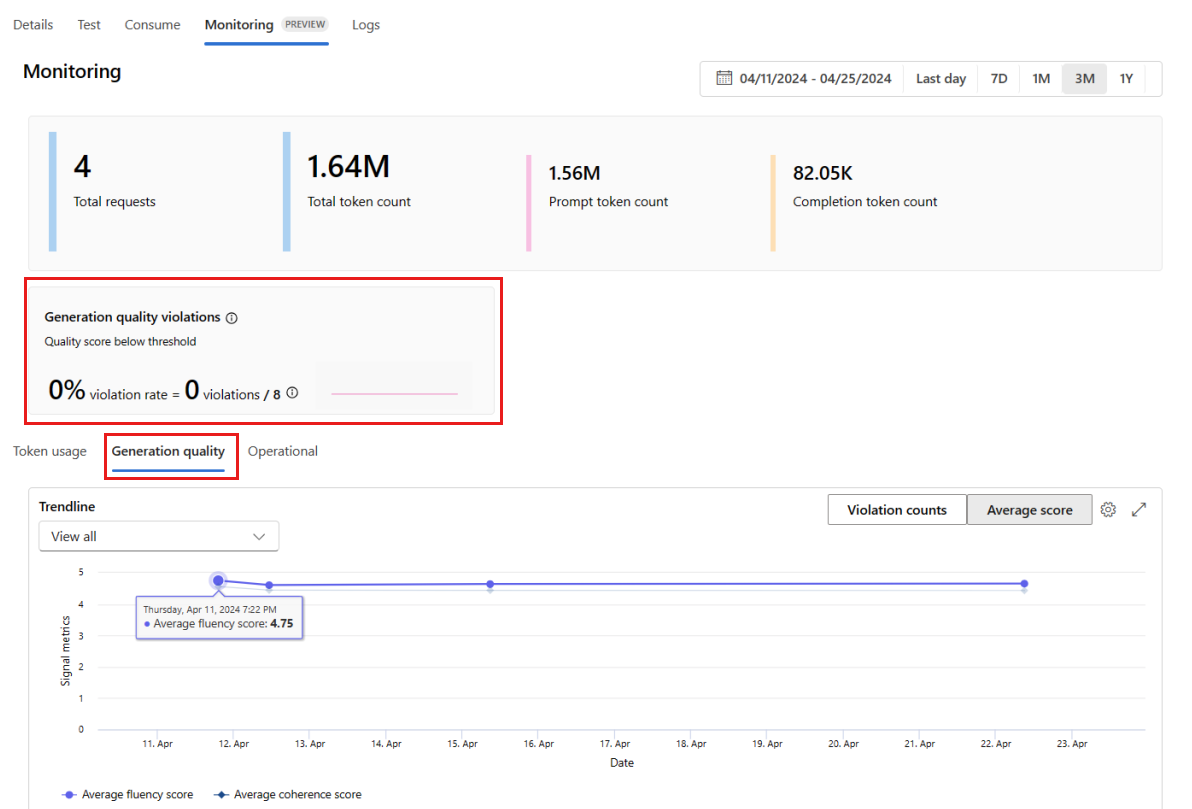
移至 [產生品質] 索引標籤,以監視一段時間後應用程式的品質。 時間圖中會顯示下列計量:
- 違規計數:指定計量的違規計數 (例如,流暢度) 是所選時間範圍內的違規總和。 如果計量的計算值低於設定的閾值,則當計算計量 (預設為每天) 時,該計量會發生違規。
- 平均分數:指定計量的平均分數 (例如,流暢度) 是所選時間範圍內所有執行個體 (或要求) 除以執行個體數目 (或要求) 的總和。
[產生品質違規] 卡片會顯示所選時間範圍內的違規率。 違規率是違規次數除以可能的違規總數。 您可以在設定中調整計量的閾值。 根據預設,計量會每日計算;這個頻率也可以在設定中調整。
您也可以從 [監視 (預覽)] 索引標籤,檢視所選時間範圍內傳送至部署之所有取樣要求的完整資料表。
注意
監視會將預設取樣率設定為10%。 這表示如果將 100 個要求傳送至您的部署,則會取樣 10 個,並用來計算產生品質計量。 您可以在設定中調整取樣率。
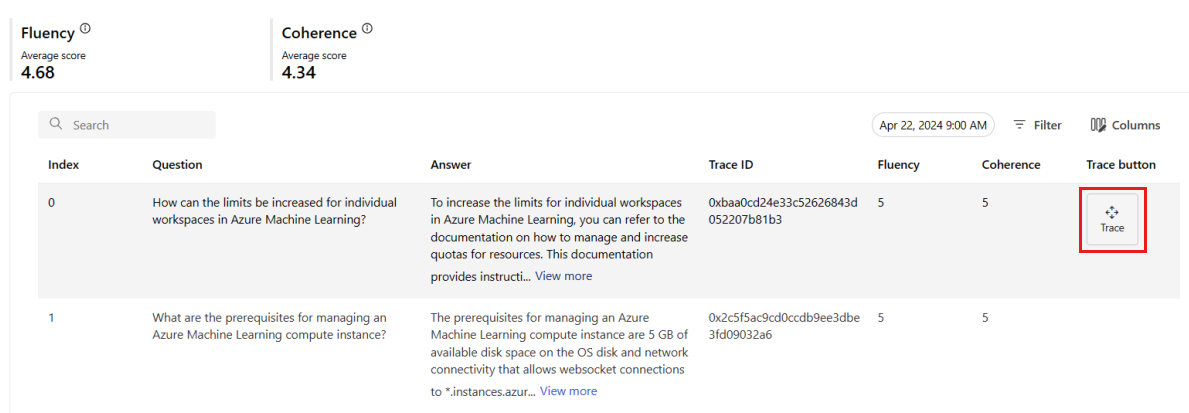
選取資料表中資料列右側的 [追蹤] 按鈕,以查看指定要求的追蹤詳細資料。 此檢視提供應用程式要求的完整追蹤詳細資料。
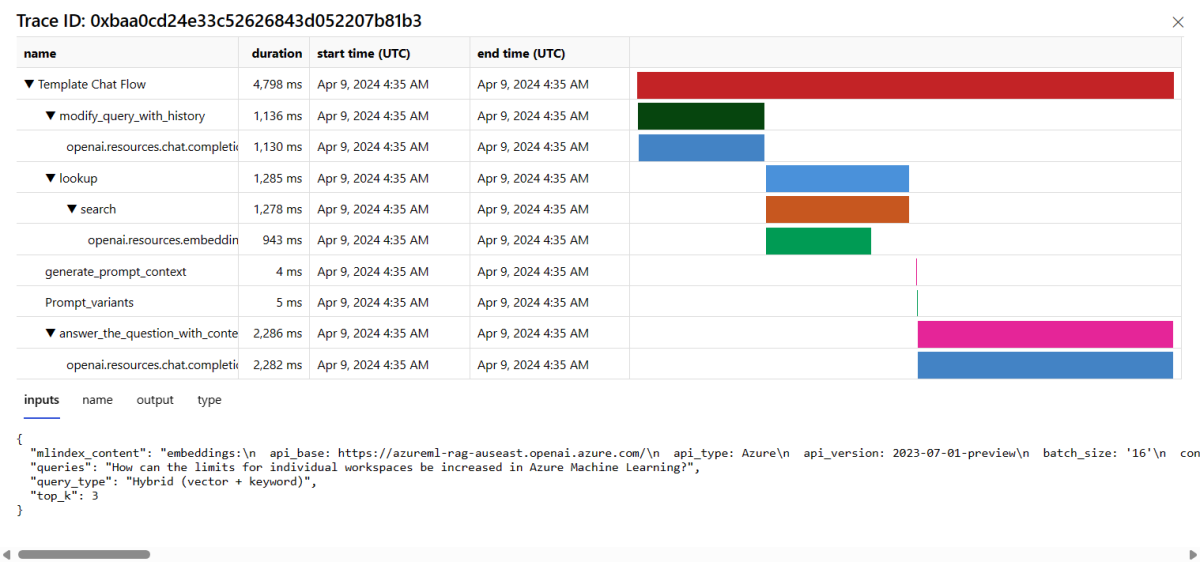
關閉 [追蹤] 檢視。
移至 [作業] 索引標籤,以近乎即時的方式檢視部署的作業計量。 我們支援下列作業計量:
- 要求計數
- 延遲
- 錯誤率





部署的 [監視 (預覽)] 索引標籤中的結果提供深入解析,以協助您主動改善提示流程應用程式的效能。
使用 SDK v2 進行進階監視設定
監視也支援使用 SDK v2 的進階設定選項。 以下是支援的案例:
啟用權杖使用方式的監視
如果只想為已部署的提示流程應用程式啟用權杖使用方式監視,則可以針對案例調整下列指令碼:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationTokenStatisticsSignal,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
# These variables can be renamed but it is not necessary
monitor_name ="gen_ai_monitor_tokens"
defaulttokenstatisticssignalname ="token-usage-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Create an instance of token statistic signal
token_statistic_signal = GenerationTokenStatisticsSignal()
monitoring_signals = {
defaulttokenstatisticssignalname: token_statistic_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
啟用產生品質的監視
如果只想為已部署的提示流程應用程式啟用產生品質監視,則可以針對案例調整下列指令碼:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationSafetyQualityMonitoringMetricThreshold,
GenerationSafetyQualitySignal,
BaselineDataRange,
LlmData,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
aoai_deployment_name ="INSERT YOUR AOAI DEPLOYMENT NAME"
aoai_connection_name = "INSERT YOUR AOAI CONNECTION NAME"
# These variables can be renamed but it is not necessary
app_trace_name = "app_traces"
app_trace_Version = "1"
monitor_name ="gen_ai_monitor_generation_quality"
defaultgsqsignalname ="gsq-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Set thresholds for passing rate (0.7 = 70%)
aggregated_groundedness_pass_rate = 0.7
aggregated_relevance_pass_rate = 0.7
aggregated_coherence_pass_rate = 0.7
aggregated_fluency_pass_rate = 0.7
# Create an instance of gsq signal
generation_quality_thresholds = GenerationSafetyQualityMonitoringMetricThreshold(
groundedness = {"aggregated_groundedness_pass_rate": aggregated_groundedness_pass_rate},
relevance={"aggregated_relevance_pass_rate": aggregated_relevance_pass_rate},
coherence={"aggregated_coherence_pass_rate": aggregated_coherence_pass_rate},
fluency={"aggregated_fluency_pass_rate": aggregated_fluency_pass_rate},
)
input_data = Input(
type="uri_folder",
path=f"{endpoint_name}-{deployment_name}-{app_trace_name}:{app_trace_Version}",
)
data_window = BaselineDataRange(lookback_window_size="P7D", lookback_window_offset="P0D")
production_data = LlmData(
data_column_names={"prompt_column": "question", "completion_column": "answer", "context_column": "context"},
input_data=input_data,
data_window=data_window,
)
gsq_signal = GenerationSafetyQualitySignal(
connection_id=f"/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{project_name}/connections/{aoai_connection_name}",
metric_thresholds=generation_quality_thresholds,
production_data=[production_data],
sampling_rate=1.0,
properties={
"aoai_deployment_name": aoai_deployment_name,
"enable_action_analyzer": "false",
"azureml.modelmonitor.gsq_thresholds": '[{"metricName":"average_fluency","threshold":{"value":4}},{"metricName":"average_coherence","threshold":{"value":4}}]',
},
)
monitoring_signals = {
defaultgsqsignalname: gsq_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
從 SDK 建立監視器之後,您可以在 Azure AI Foundry 入口網站中取用監視結果 。
相關內容
- 深入瞭解您可以在 Azure AI Foundry 中執行的動作。
- 在 Azure AI 常見問題集一文中取得常見問題集的解答。