如何使用 Azure AI Foundry 評估產生的 AI 模型和應用程式
若要在套用至大量數據集時徹底評估產生 AI 模型和應用程式的效能,您可以起始評估程式。 在此評估期間,您的模型或應用程式會使用指定的數據集進行測試,且其效能會以數學為基礎的計量和 AI 輔助計量進行量化測量。 此評估執行可讓您全面瞭解應用程式的功能和限制。
若要進行這項評估,您可以使用 Azure AI Foundry 入口網站中的評估功能,這是一個完整的平臺,可提供工具和功能,以評估您產生的 AI 模型效能和安全性。 在 Azure AI Foundry 入口網站中,您可以記錄、檢視和分析詳細的評估計量。
在本文中,您將瞭解如何針對來自 Azure AI Foundry UI 的內建評估計量,針對模型、測試數據集或流程建立評估回合。 如需更多彈性,您可以建立自訂評估流程,並採用自訂評估功能。 或者,如果您的目標只有進行批次執行而不進行任何評估,也可以使用自訂評估功能。
必要條件
若要使用 AI 輔助的計量執行評估,您必須備妥下列項目:
- 下列其中一種格式的測試資料集:
csv或jsonl。 - Azure OpenAI 連線。 下列任一種模型的部署:GPT 3.5 模型、GPT 4 模型或 Davinci 模型。 只有在執行 AI 輔助質量評估時,才需要此專案。
使用內建評估計量建立評估
評估執行可讓您為測試資料集中的每個資料列產生計量輸出。 您可以選擇一個或多個評估計量,以評估來自不同層面的輸出。 您可以從 Azure AI Foundry 入口網站中的評估、模型目錄或提示流程頁面建立評估回合。 隨後會出現評估建立精靈,引導您完成設定評估執行的流程。
透過評估頁面
從可折疊的左側功能表中,選取 [評估>+ 建立新的評估]。

從模型目錄頁面
從可折疊的左側功能表中,選取 [模型目錄> ] 移至特定模型 > ,流覽至 [基準檢驗 > ] 索引標籤 [試用您自己的數據]。 這會開啟模型評估面板,讓您針對選取的模型建立評估回合。

透過流程頁面
從可折疊的左側功能表中,選取 [ 提示流程>評估>自動化評估]。

評估目標
當您從評估頁面開始評估時,必須先決定評估目標是什麼。 藉由指定適當的評估目標,我們可以針對應用程式的特定性質量身打造評估,以確保計量精確且符合需求。 我們支援三種類型的評估目標:
- 模型和提示:您想要評估所選模型和使用者定義提示所產生的輸出。
- 資料集:您已在測試資料集中具備模型產生的輸出。
- 提示流程:您已建立流程,而且您想要評估流程中的輸出。

數據集或提示流程評估
當您輸入評估建立精靈時,可以提供評估回合的選擇性名稱。 我們目前提供查詢和回應案例的支援,此案例專為涉及回應使用者查詢的應用程式所設計,並提供內容信息的回應。
您可以選擇性地將描述和標籤新增至評估回合,以改善組織、內容和輕鬆擷取。
您也可以使用說明面板來檢查常見問題,並引導您完成精靈。

如果您要評估提示流程,您可以選取要評估的流程。 如果您是從 [流程] 頁面起始評估,我們會自動選取流程進行評估。 如果您想要評估另一個流程,也可以選取不同的流程。 請特別注意,在流程中可能會有多個節點,而每個節點可能都有自己的變體集。 在這種情況下,您必須指定節點以及要在評估程式期間評估的變體。

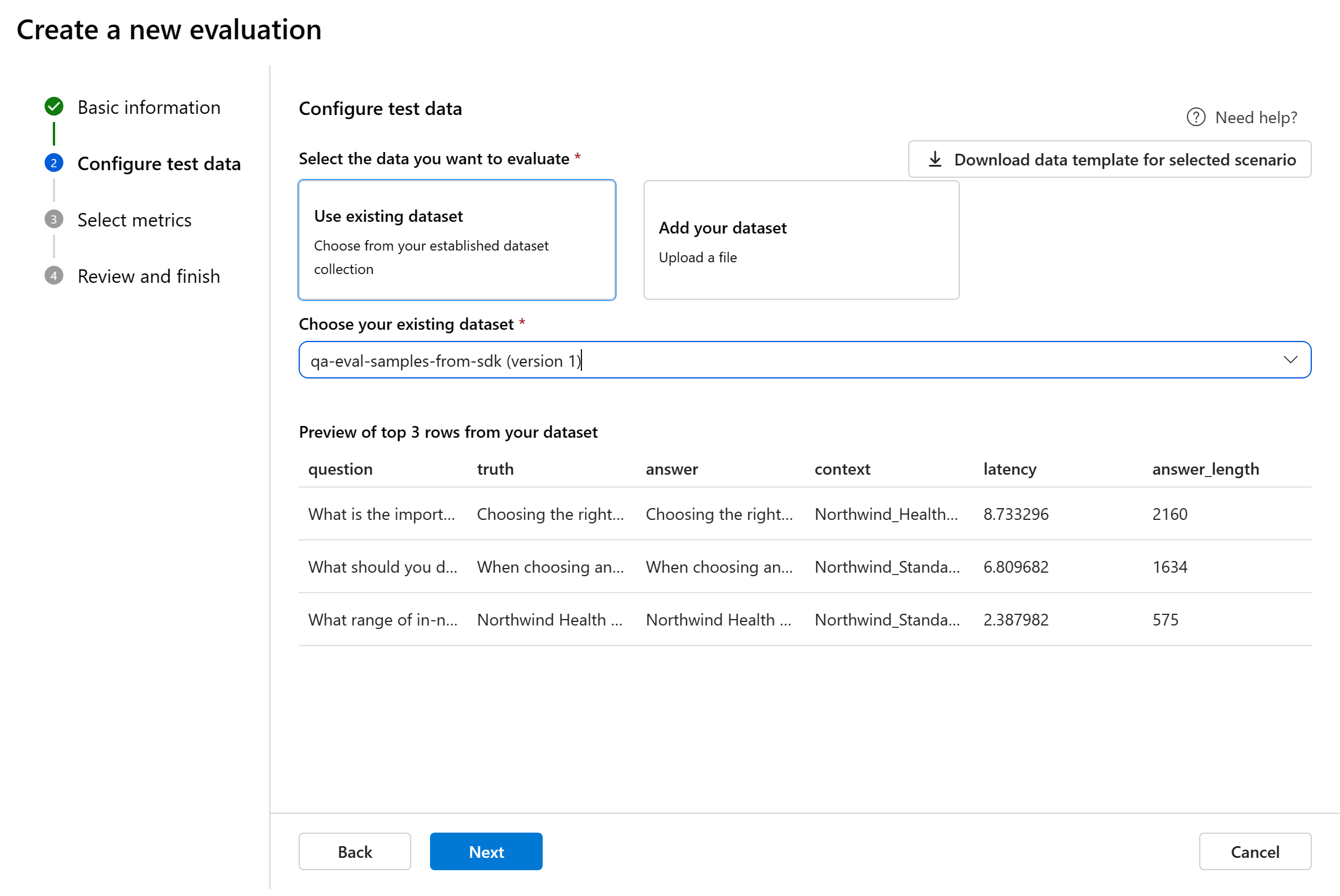
設定測試資料
您可以選取自預先存在的資料集,或是上傳評估專用的新資料集。 如果沒有在前一步驟中選取流程,測試資料集必須有模型產生的輸出以用於評估。
選擇現有的資料集:您可以從已建立的資料集集合中選擇測試資料集。
新增資料集:您可以從本機儲存體上傳檔案。 我們只支援
.csv和.jsonl檔案格式。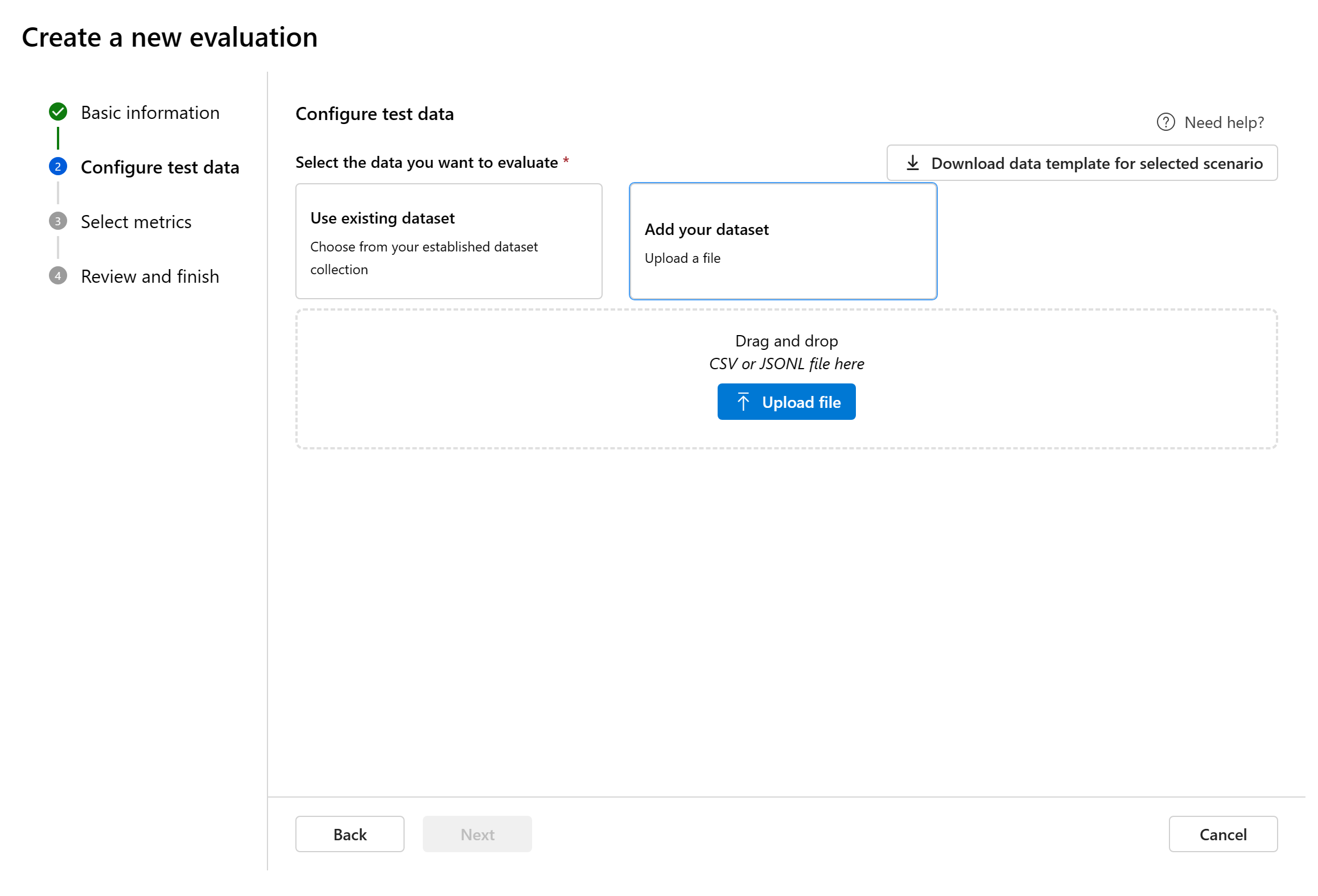
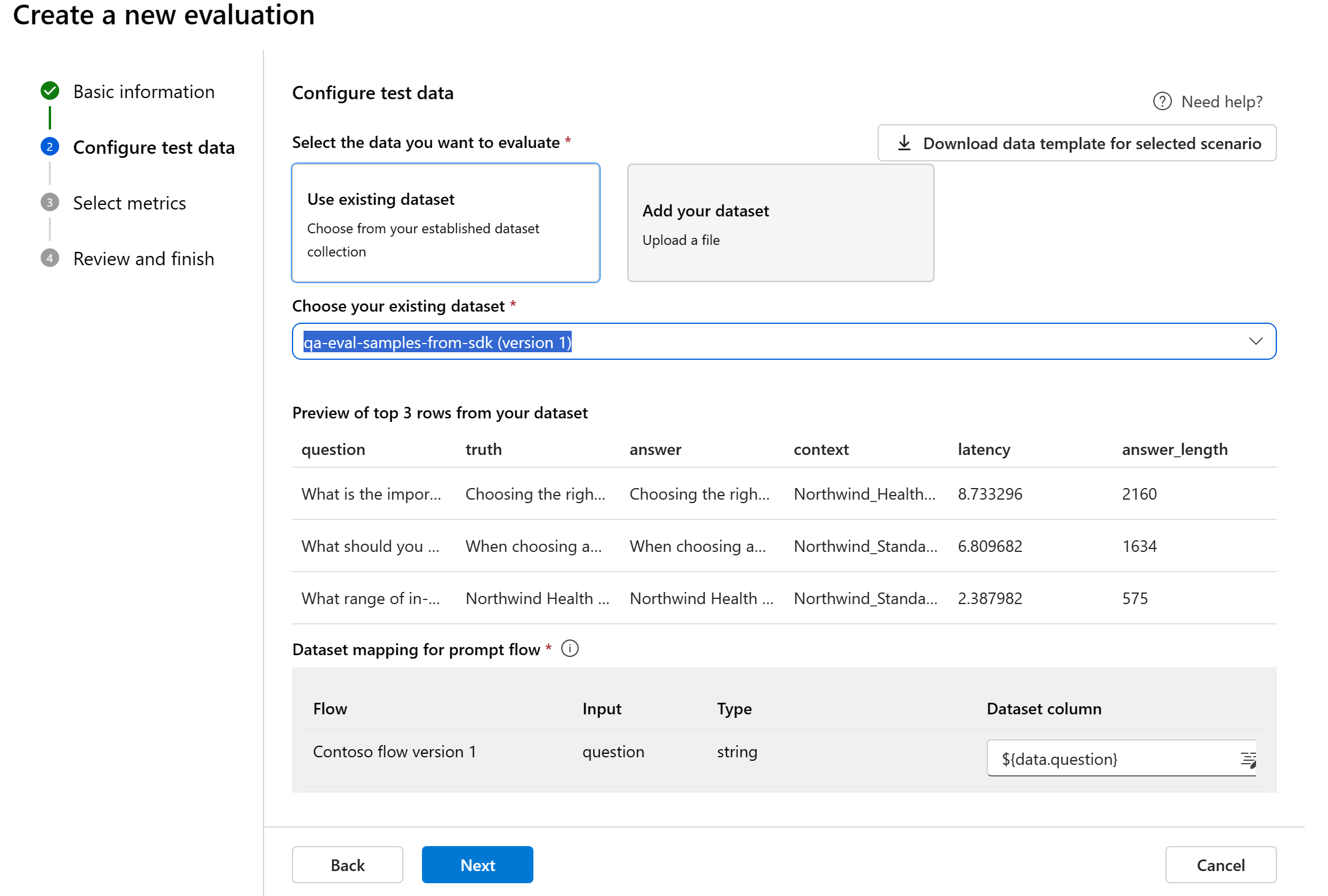
流程的資料對應:如果您選取要評估的流程,請確定您的資料行已設定為與要執行批次執行的流程所需的輸入一致,以便產生評量輸出。 然後,就可以使用流程的輸出來執行評估。 接著,在下一個步驟中設定評估輸入的資料對應。



選取計量
我們支援由 Microsoft 策劃的三種計量類型,以協助您全面評估您的應用程式:
- AI 品質(AI 輔助):這些計量會評估所產生內容的整體品質和一致性。 若要執行這些計量,它需要模型部署作為判斷。
- AI 品質 (NLP):這些 NLP 計量是以數學為基礎,也會評估所產生內容的整體品質。 它們通常需要地面真相數據,但不需要模型部署作為判斷。
- 風險和安全性計量:這些計量著重於識別潛在的內容風險,並確保所產生內容的安全性。

您可以參考表格,以取得我們在每個情境中所支援的完整計量清單。 若想進一步了解每個計量定義及其計算方式的資訊,請參閱評估和監視計量。
| AI 品質(AI 輔助) | AI 品質 (NLP) | 風險和安全性計量 |
|---|---|---|
| 基礎性、相關性、連貫性、流暢性、GPT 相似性 | F1 分數, ROUGE, 分數, BLEU分數, GLEU 分數, 流星分數 | 自殘相關內容、仇恨和不公平的內容、暴力內容、色情內容、受保護的材料、間接攻擊 |
執行 AI 輔助質量評估時,您必須指定計算程式的 GPT 模型。 選擇 Azure OpenAI 連線和使用 GPT-3.5、GPT-4 或 Davinci 模型的部署以進行計算。

AI Quality (NLP) 計量是以數學為基礎的度量,可評估應用程式的效能。 它們通常需要基礎真相數據來進行計算。 ROUGE 是一系列計量。 您可以選取 ROUGE 類型來計算分數。 各種類型的 ROUGE 計量提供評估文字產生品質的方法。 ROUGE-N 測量候選文字與參考文字之間的 n-gram 重疊。

對於風險和安全性計量,您不需要提供連線和部署。 Azure AI Foundry 入口網站安全性評估後端服務會布建 GPT-4 模型,以產生內容風險嚴重性分數和推理,讓您評估應用程式是否有內容危害。
您可以設定閾值來計算內容傷害計量的瑕疵率 (自殘相關內容、仇恨和不公平的內容、暴力內容、色情內容)。 缺陷率的計算方式是採用執行個體超過閾值的嚴重性層級 (非常低、低、中、高) 百分比。 根據預設,我們會將閾值設定為「中」。
針對受保護的材料和間接攻擊,瑕疵率會計算為輸出為 'true' 的執行個體百分比 (瑕疵率 = (#trues / #instances) × 100)。

注意
AI 輔助的風險和安全性計量是由 Azure AI Foundry 安全性評估後端服務所裝載,且僅適用於下列區域:美國東部 2、法國中部、英國南部、瑞典中部
評估的資料對應:您必須指定資料集中的哪些資料行對應評估所需的輸入。 不同的評估計量需要不同類型的資料輸入,才能進行精確的計算。

注意
如果您要從數據進行評估,「回應」應該對應至數據集 ${data$response}中的響應數據行。 如果您要從流程進行評估,「回應」應該來自流程輸出 ${run.outputs.response}。
如需每個計量的具體資料對應需求指引,請參閱下表提供的資訊:
查詢和回應計量需求
| 計量 | Query | 回應 | 上下文 | 有根據事實 |
|---|---|---|---|---|
| 根據性 | 需要:Str | 需要:Str | 需要:Str | N/A |
| 連貫性 | 需要:Str | 需要:Str | N/A | N/A |
| 流暢度 | 需要:Str | 需要:Str | N/A | N/A |
| 相關性 | 需要:Str | 需要:Str | 需要:Str | N/A |
| GPT 相似度 | 需要:Str | 需要:Str | N/A | 需要:Str |
| F1 分數 | N/A | 需要:Str | N/A | 需要:Str |
| BLEU 分數 | N/A | 需要:Str | N/A | 需要:Str |
| GLEU 分數 | N/A | 需要:Str | N/A | 需要:Str |
| METEOR 分數 | N/A | 需要:Str | N/A | 需要:Str |
| ROUGE 分數 | N/A | 需要:Str | N/A | 需要:Str |
| 自我傷害相關內容 | 需要:Str | 需要:Str | N/A | N/A |
| 仇恨和不公平的內容 | 需要:Str | 需要:Str | N/A | N/A |
| 暴力內容 | 需要:Str | 需要:Str | N/A | N/A |
| 性內容 | 需要:Str | 需要:Str | N/A | N/A |
| 受保護的資料 | 需要:Str | 需要:Str | N/A | N/A |
| 間接攻擊 | 需要:Str | 需要:Str | N/A | N/A |
- 查詢:搜尋特定信息的查詢。
- 回應:模型所產生的查詢回應。
- 內容:回應所產生的來源(也就是基礎檔)...
- 基礎事實:使用者/人類產生的查詢回應為真實答案。
檢閱並完成
完成所有必要的設定之後,您可以檢閱並接著選取 [提交] 以提交評估執行。

模型和提示評估
若要為選取的模型部署和定義的提示建立新的評估,請使用簡化的模型評估面板。 這個簡化的介面可讓您在單一合併面板內設定和起始評估。
基本資訊
若要開始,您可以設定評估回合的名稱。 然後選取您想要評估的 模型部署 。 我們同時支援 Azure OpenAI 模型和其他與模型即服務 (MaaS) 相容的開放模型,例如 Meta Llama 和 Phi-3 系列模型。 您可以選擇性地根據需求來調整模型參數,例如最大響應、溫度和最高 P。
在 [系統消息] 文本框中,提供案例的提示。 如需如何製作提示的詳細資訊,請參閱提示目錄。 您可以選擇新增範例來顯示聊天您想要的回應。 它會嘗試模擬您在此處新增的任何回應,以確保它們符合您在系統訊息中配置的規則。

設定測試資料
設定模型並提示之後,請設定將用於評估的測試數據集。 此數據集會傳送至模型,以產生評量回應。 您有三個選項可用來設定測試資料:
- 產生範例資料
- 使用現有的數據集
- 新增數據集
如果您沒有現成可用的數據集,而且想要以小型範例執行評估,您可以選取選項,以使用 GPT 模型根據您選擇的主題產生範例問題。 本主題可協助量身打造您感興趣的領域所產生的內容。 查詢和回應將即時產生,而且您可以選擇視需要重新產生它們。
注意
建立評估執行之後,產生的數據集將會儲存至專案的 Blob 記憶體。

資料對應
如果您選擇使用現有的數據集或上傳新的數據集,則必須將數據集的數據行對應至必要的欄位以供評估。 在評估期間,系統會根據關鍵輸入來評估模型的回應,例如:
- 查詢:所有計量都需要
- 內容:選擇性
- 基礎真相:AI 品質 (NLP) 計量所需的選擇性
這些對應可確保數據與評估準則之間的正確對齊。

選擇評估計量
最後一個步驟是選取您想要評估的內容。 我們不需要選取個別計量,而且必須熟悉所有可用的選項,而是讓您選取最符合您需求的計量類別,以簡化程式。 當您選擇類別時,該類別中的所有相關計量都會根據您在上一個步驟中提供的數據行來計算。 選取計量類別之後,您可以選取 [建立] 來提交評估回合,並移至評估頁面以查看結果。
我們支援三個類別:
- AI 品質(AI 輔助):您必須提供 Azure OpenAI 模型部署作為判斷,以計算 AI 輔助計量。
- AI 品質 (NLP)
- 安全性
| AI 品質(AI 輔助) | AI 品質 (NLP) | 安全性 |
|---|---|---|
| 基礎性(需要內容)、相關性(需要內容)、連貫性、流暢性 | F1 分數, ROUGE, 分數, BLEU分數, GLEU 分數, 流星分數 | 自殘相關內容、仇恨和不公平的內容、暴力內容、色情內容、受保護的材料、間接攻擊 |
使用自訂評估流程建立評估
您可以開發您自己的評估方法:
在流程頁面:在可摺疊的左側功能表中,選取 [提示流程]>[評估]>[自訂評估]。

在評估工具程式庫中檢視和管理評估工具
評估工具程式庫是可讓您查看評估工具詳細資料和狀態的集中式位置。 您可以檢視和管理 Microsoft 策展的評估工具。
提示
您可以透過提示流程 SDK 使用自訂評估工具。 如需更多資訊,請參閱使用提示流程 SDK 進行評估。
評估工具程式庫也會啟用版本管理。 您可以比較不同版本的工作、視需要還原舊版,以及更輕鬆地與其他人員共同作業。
若要在 Azure AI Foundry 入口網站中使用評估工具連結庫,請移至專案的 [評估] 頁面,然後選取 [評估工具連結庫] 索引標籤。

您可以選取評估工具的名稱以查看更多詳細資料。 您可以查看名稱、描述和參數,檢查與評估工具相關聯的任何檔案。 以下是一些 Microsoft 策展的評估工具範例:
- 若是 Microsoft 策展的效能和品質評估工具,您可以在詳細資料頁面上檢視註釋提示。 您可以根據數據和目標 Azure AI 評估 SDK 來變更參數或準則,將這些提示調整為您自己的使用案例。 例如,您可以選取 Groundedness-Evaluator,並檢查顯示計算計量方法的 Prompty 檔案。
- 若是 Microsoft 策展的風險和安全性評估工具,您可以查看計量的定義。 例如,您可以選取 自我傷害相關內容評估工具 ,並瞭解其意義,以及Microsoft如何判斷此安全計量的各種嚴重性層級。
下一步
深入了解如何評估您的生成式 AI 應用程式:
- 透過遊樂場評估您的生成式 AI 應用程式
- 檢視評估結果
- 深入了解損害風險降低技巧。
- Azure AI Foundry 安全性評估的透明度注意事項。