如何在 Azure AI Foundry 入口網站中檢視評估結果
Azure AI Foundry 入口網站評估頁面是一個多功能的中樞,不僅可讓您可視化和評估結果,還能做為優化、疑難解答和選取適合您部署需求的理想 AI 模型的控制中心。 這是 Azure AI Foundry 專案中數據驅動決策和效能增強的一站式解決方案。 您可以順暢地存取和解譯來自各種來源的結果,包括您的流程、遊樂場快速測試工作階段、評估提交 UI 和 SDK.。 此彈性可確保您能夠以最符合工作流程和喜好設定的方式與結果互動。
一旦您將評估結果視覺化,您就可以深入完整檢查。 這包括不僅能夠檢視個別結果,還能比較多次評估執行的結果。 如此一來,您就可以識別趨勢、模式和差異,並取得各種條件下 AI 系統效能的寶貴深入解析。
在本文中,您將了解:
- 檢視評估結果和計量。
- 比較評估結果。
- 了解內建評估計量。
- 改善效能。
- 檢視評估結果和計量。
尋找您的評估結果
提交評估之後,您可以導覽至 [評估] 頁面,在執行清單中找出已提交的評估執行。
您可以在執行清單中監視和管理評估執行。 有了使用資料行編輯器修改資料行並實作篩選條件的彈性,您可以自訂並建立自己的執行清單版本。 此外,您也能夠快速檢閱整個執行中的彙總評估計量,讓您能夠進行快速比較。

提示
若要使用任何版本的 promptflow-evals SDK 或 azure-ai-evaluation 1.0.0b1、1.0.0b2、1.0.0b3 來檢視評估,請啟用 [顯示所有執行] 切換來找出執行。
若要深入瞭解評估計量的衍生方式,您可以選取 [深入瞭解計量] 選項,以存取完整的說明。 此詳細資源對於評估流程中所使用計量,提供計算和解譯的寶貴深入解析。

您可以選擇特定的執行,這會帶您前往 [執行詳細資料] 頁面。 您可以在這裡存取全面的資訊,包括測試資料集、工作類型、提示、溫度等評估詳細資料。 此外,您可以檢視與每個資料樣本相關聯的計量。 計量分數圖表提供整個資料集中,每個計量的分數如何散發的視覺表示法。
計量儀錶板圖表
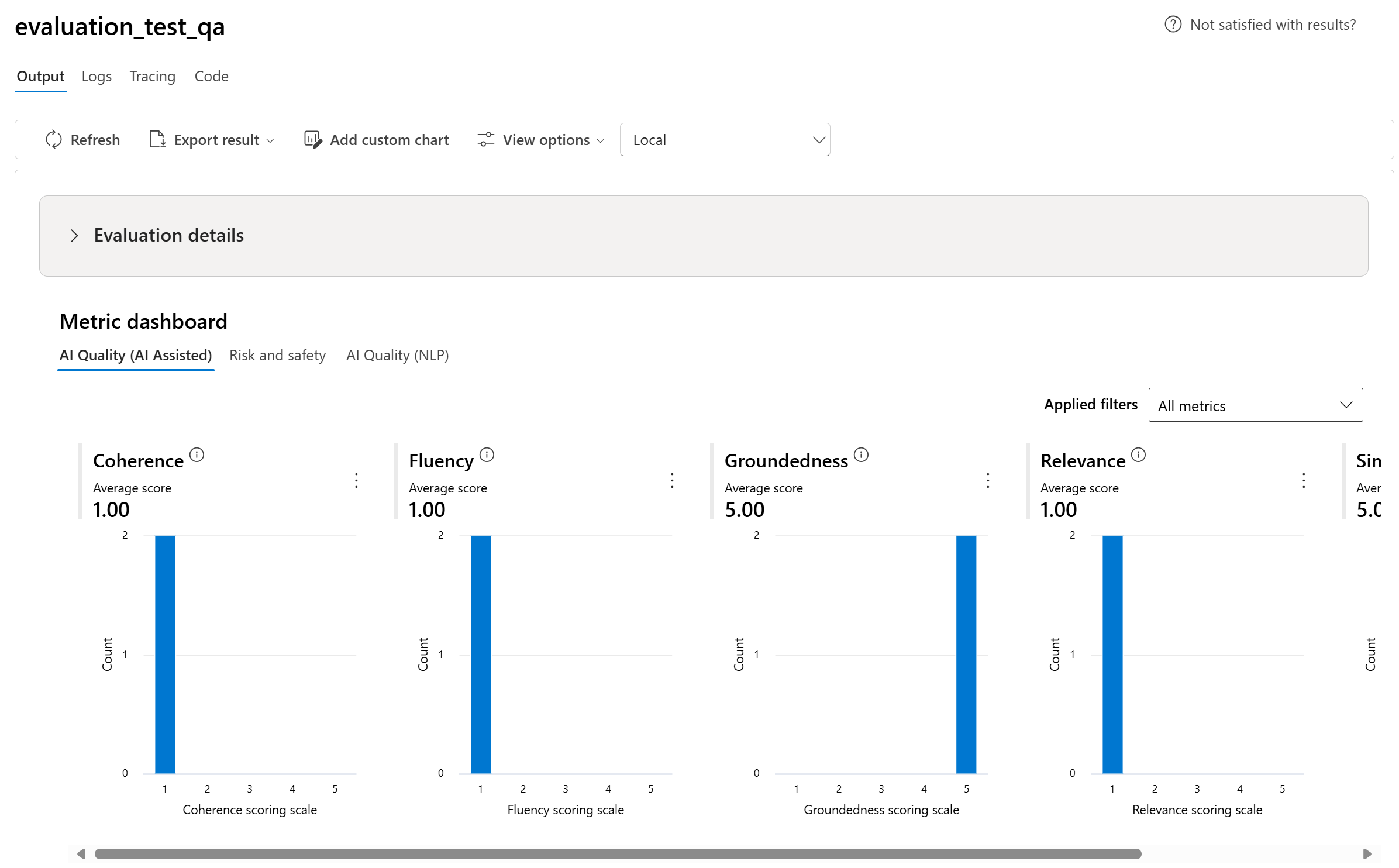
我們會根據 AI 品質(AI 輔助)、風險和安全性、AI 品質 (NLP) 和自定義,以不同類型的計量細分匯總檢視。 您可以檢視評估資料集中分數的分佈,並查看每個計量的彙總分數。
- 針對 AI 品質(AI 協助),我們會計算每個計量的所有分數的平均值來匯總。 如果您計算基礎專業版,則輸出為二進位,因此匯總分數會通過速率,其計算方式為 (#trues / #instances) × 100。
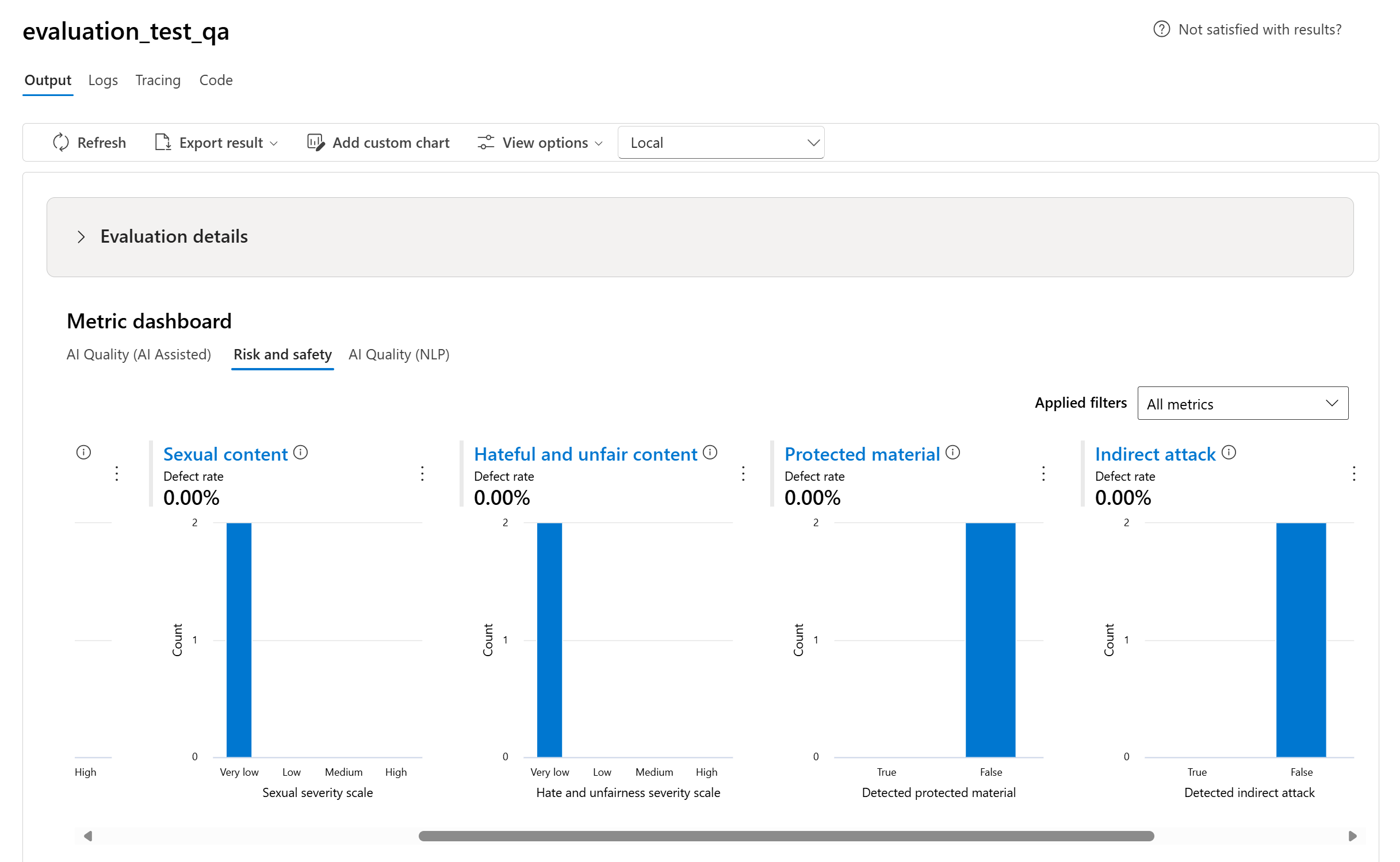
- 針對風險和安全性計量,我們會計算每個計量的瑕疵率來進行彙總。
- 對於內容損害計量,瑕疵率定義為測試資料集中超出嚴重性級別閾值的執行個體佔整個資料集大小的百分比。 根據預設,閾值為「中等」。
- 針對受保護的材料和間接攻擊,瑕疵率會計算為輸出為 'true' 的執行個體百分比 (瑕疵率 = (#trues / #instances) × 100)。
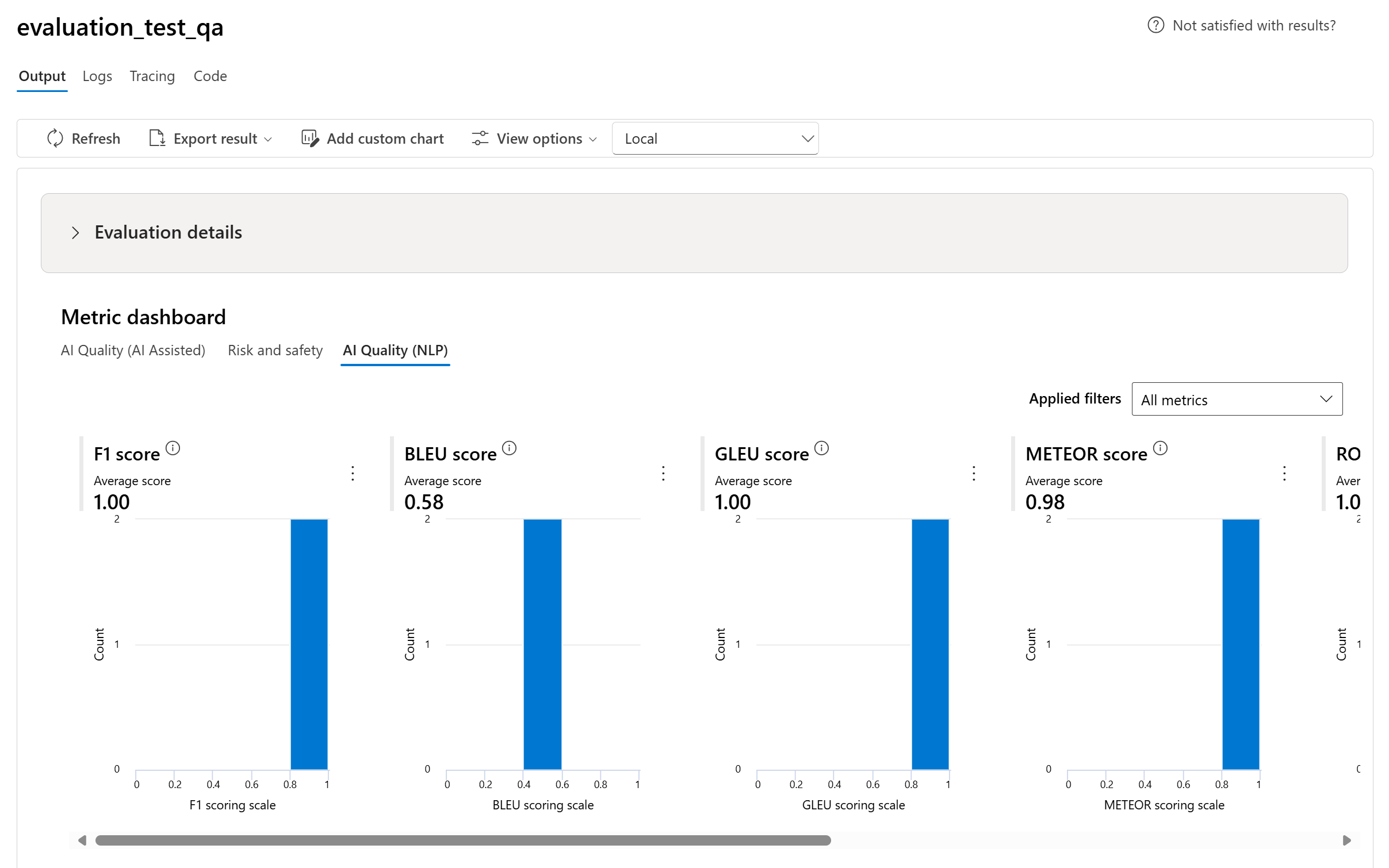
- 針對 AI 品質 (NLP) 計量,我們會顯示 0 到 1 之間的計量分佈直方圖。 我們會計算每個計量的所有分數的平均值來匯總。
- 針對自訂計量,您可以選取 [ 新增自定義圖表],以使用您選擇的計量建立自定義圖表,或針對選取的輸入參數檢視計量。
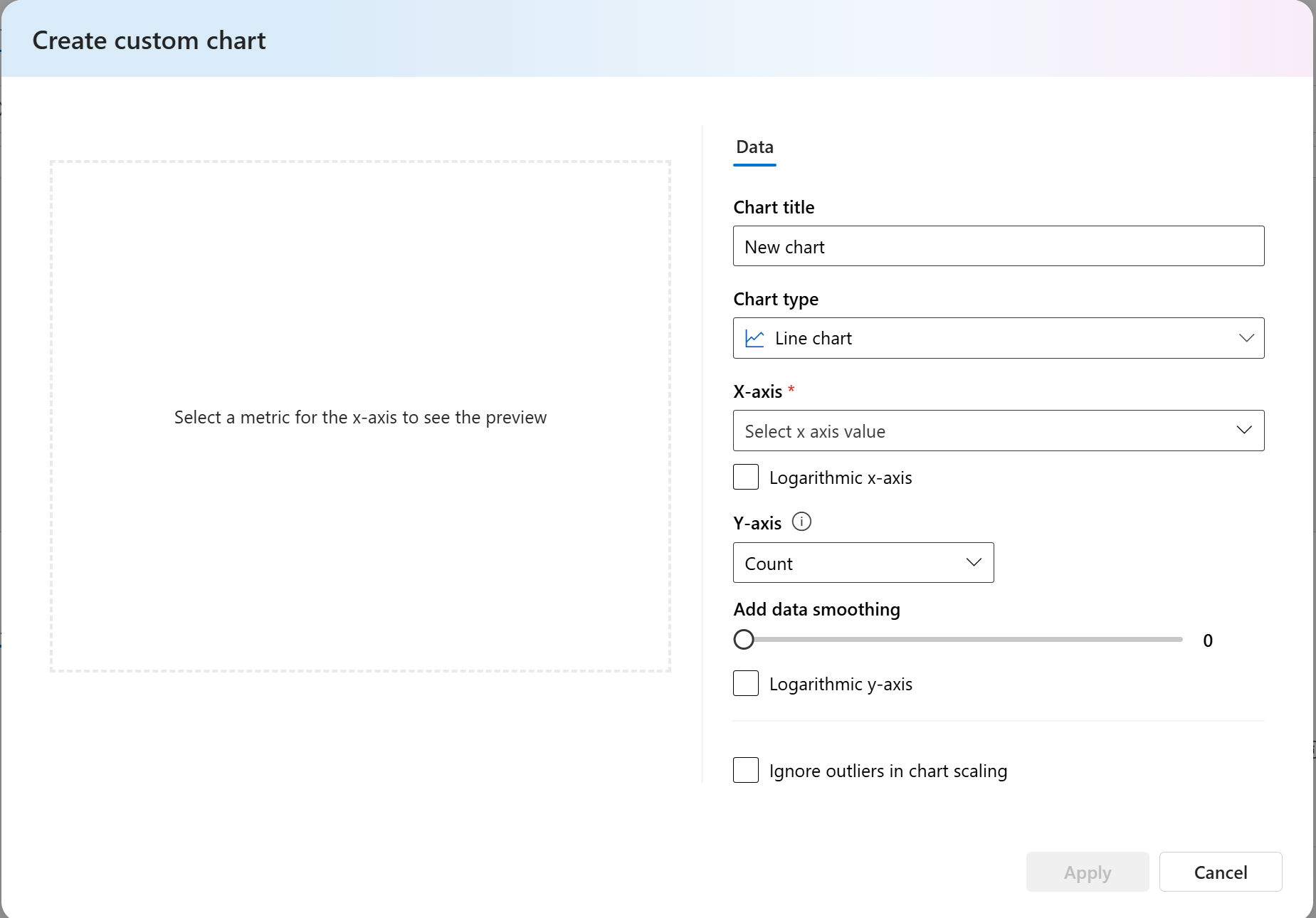




您也可以藉由變更圖表類型來自定義內建計量的現有圖表。

詳細計量結果數據表
在計量詳細資料的資料表中,您可以全面檢查每個個別資料樣本。 您可以在此處仔細檢查產生的輸出,以及其所對應的評估計量分數。 這種程度的詳細資料可讓您做出資料驅動決策,並採取特定動作來改善模型的效能。
一些根據評估計量的可進行的潛在動作項目包括:
- 模式辨識:藉由篩選數值和計量,您可以向下鑽研分數較低的樣本。 調查這些樣本以識別模型回應中的週期性模式或問題。 例如,您可能會注意到模型在特定主題上生成內容時經常會出現低分。
- 模型調整:使用較低評分樣本的深入解析來改善系統提示指示或微調您的模型。 如果您觀察到一致的問題,例如連貫性或相關性問題,您也可以據此調整模型的定型資料或參數。
- 自訂資料行:資料行編輯器可讓您建立資料表的自訂檢視,著重於與評估目標最相關的計量和資料。 這可簡化您的分析,並協助您更有效率地找出趨勢。
- 關鍵詞搜尋:搜尋方塊可讓您在生成的輸出中尋找特定字組或片語。 這適用於找出與特定主題或關鍵字相關的問題或模式,並具體解決這些問題。
計量詳細資料表提供許多資料可輔助您改善模型的工作,從辨識模式到自訂檢視,讓您有效率地分析和根據已識別的問題調整模型。
以下是一些問題解答案例的計量結果範例:

以下是一些交談案例計量結果的範例:

針對多回合交談案例,您可以選取「檢視每個回合的評估結果」來檢查交談中每個回合的評估計量。


如需多重強制回應案例中的安全性評估(文字 + 影像),您可以檢閱詳細計量結果數據表中輸入和輸出的影像,以進一步瞭解評估結果。 由於目前僅支持對話案例的多強制回應評估,因此您可以選取 [檢視每個回合的評估結果],以檢查每個回合的輸入和輸出。


選取要展開並檢視的影像。 根據預設,所有影像都會模糊,以保護您免受潛在有害內容的影響。 若要清楚地檢視影像,請開啟 [檢查模糊影像] 切換。

針對風險和安全性計量,評估會為每個分數提供嚴重性分數和推理。 以下是一些問題解答案例的風險和安全性計量結果範例:

評估結果對於不同的物件可能有不同的意義。 例如,安全性評估可能會產生暴力內容的「低」嚴重性標籤,可能不符合人類檢閱者對特定暴力內容可能有多嚴重性的定義。 在檢閱您的評估結果時,我們會提供一個人工意見反應資料行,其中包含贊成和反對的選項,以顯示哪些實例被人工檢閱者批准或標記為不正確。

了解每個內容風險計量時,您可以藉由選取圖表上方的計量名稱來輕鬆檢視每個計量定義和嚴重性級別,以查看彈出視窗中的詳細說明。

如果執行發生問題,您也可以使用記錄對評估回合進行偵錯。
以下是可用來偵錯評估執行的一些記錄範例:

如果您要評估提示流程,您可以選取 [在流程中檢視] 按鈕,以瀏覽至評估流程頁面,以更新流程。 例如,新增其他中繼提示指令,或變更某些參數並重新評估。
使用檢視選項管理和共享檢視
在 [評估詳細數據] 頁面上,您可以新增自定義圖表或編輯數據行來自定義檢視。 自訂之後,您可以選擇使用檢視選項來儲存檢視和/或與其他人共用。 這可讓您以專為喜好設定量身打造的格式來檢閱評估結果,並協助與同事共同作業。
![[檢視選項] 按鈕下拉式清單的螢幕快照。](../media/evaluations/view-results/view-options-evaluation-details.png#lightbox)
比較評估結果
若要輔助兩次或多次執行之間的全面比較,您可以選取所需的執行並選取 [比較] 按鈕來起始流程,或若要一般詳細儀表板檢視,則選 [切換至儀表板檢視] 按鈕。 這項功能可讓您分析和對比多次執行的效能和結果,以做出更深思熟慮的決策和針對性改善項目。

在儀表板檢視中,您可以存取兩個很有價值的元件:計量分佈比較圖表和比較資料表。 這些工具可讓您執行所選評估執行的並存分析,讓您輕鬆且精確地比較每個資料樣本的各個層面。

在比較資料表中,您可以藉由將滑鼠暫留在您想要作為參考點並設為基準的特定執行上,來建立用於比較的基準。 此外,藉由啟用 [顯示差異] 切換,您就可以輕鬆視覺化基準執行與其他執行之間的數值差異。 此外,啟用 [只顯示差異] 切換時,資料表只會顯示所選執行之間不同的資料列,有助於識別相異的變化。
您可以使用這些比較功能,做出深思熟慮的決策來選取最佳版本:
- 比較基準:藉由設定基準執行,您可以識別用於比較其他執行的參考點。 這可讓您查看每個執行如何偏離您所選擇的標準。
- 數值評估:啟用 [顯示差異] 選項可協助您了解基準與其他執行之間的差異程度。 這很適合用於評估各種執行在特定評估計量方面的執行表現。
- 差異隔離:「只顯示差異」功能將只在執行有差異時才醒目提示區域,以此簡化您的分析。 這有助於找出需要改善或調整的位置。
藉由有效地使用這些比較工具,您可以識別模型或系統在哪個版本中能針對您定義的準則和計量有最佳表現,最終協助您為應用程式選取最理想的選項。

測量越獄弱點
評估越獄是個比較度量,而不是 AI 輔助計量。 在兩個不同紅色小組資料集上執行評估:基準對抗式測試資料集與第一回合越獄插入的相同對抗式測試資料集。 您可以使用對抗式資料模擬器,來產生帶或不帶越獄插入的資料集。
若要了解您的應用程式是否容易受到越獄攻擊,您可以指定基準是什麽,然後在比較資料表中開啟「越獄瑕疵率」開關。 越獄瑕疵率定義為測試資料集中越獄插入相對於整個資料集大小的基準為任何內容風險計量產生更高嚴重性分數的實例的百分比。 您可以在比較儀表板中選取多個評估,以檢視瑕疵率的差異。

提示
越獄瑕疵率只會針對相同大小的資料集計算,而且只有在所有執行都包含內容風險和安全計量時才計算。
了解內建評估計量
了解內建計量對於評估 AI 應用程式的效能和有效性至關重要。 藉由深入了解這些關鍵測量工具,您可以更充分地解譯結果、做出深思熟慮的決策,以及微調您的應用程式以達到最佳結果。 若要深入了解每個計量的意義、其計算方式、其在評估模型各個層面的角色,以及如何解譯結果以進行資料驅動改善,請參閱 評估與監視計量。
下一步
深入了解如何評估您的生成式 AI 應用程式:
深入了解損害風險降低技巧。