Azure OpenAI 預存完成和釀酒 (預覽)
預存完成可讓您從聊天完成會話擷取交談歷程記錄,以作為評估和微調的數據集。
預存完成支援
API 支援
第一次新增的支援 2024-10-01-preview
模型和區域可用性
| 區域 | o1-preview, 2024-09-12 | o1-mini, 2024-09-12 | gpt-4o,2024-08-06 | gpt-4o,2024-05-13 | gpt-4o-mini, 2024-07-18 |
|---|---|---|---|---|---|
| 瑞典中部 | ✅ | ✅ | ✅ | ✅ | ✅ |
| 美國中北部 | - | - | ✅ | - | - |
| 美國東部 2 | - | - | ✅ | - | - |
設定預存完成
若要啟用 Azure OpenAI 部署的預存完成,請將 store 參數設定為 True。
metadata使用 參數,以其他資訊擴充預存的完成數據集。
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2024-10-01-preview"
)
completion = client.chat.completions.create(
model="gpt-4o", # replace with model deployment name
store= True,
metadata = {
"user": "admin",
"category": "docs-test",
},
messages=[
{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."},
{"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random subsets of data), boosting (sequentially training models to correct previous errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree focusing on correcting the errors of previous trees. These methods often achieve better performance than single models by reducing overfitting and variance while capturing different aspects of the data."}
]
)
print(completion.choices[0].message)
啟用 Azure OpenAI 部署的預存完成之後,它們就會開始顯示在 [預存完成] 窗格中的 Azure AI Foundry 入口網站中。

擷取
釀酒可讓您將預存完成轉換成微調數據集。 常見的使用案例是針對特定工作使用預存完成與較強大的模型,然後使用預存完成,針對模型互動的高品質範例定型較小的模型。
釀酒至少需要 10 個預存完成,不過建議提供數十到數千個預存完成,以獲得最佳結果。
從 Azure AI Foundry 入口網站中的 [預存完成] 窗格中,使用 [篩選] 選項來選取您要用來定型模型的完成。
若要開始釀酒,請選取 [ 釀酒]
挑選您想要微調儲存完成數據集的模型。
確認您想要微調的模型版本:
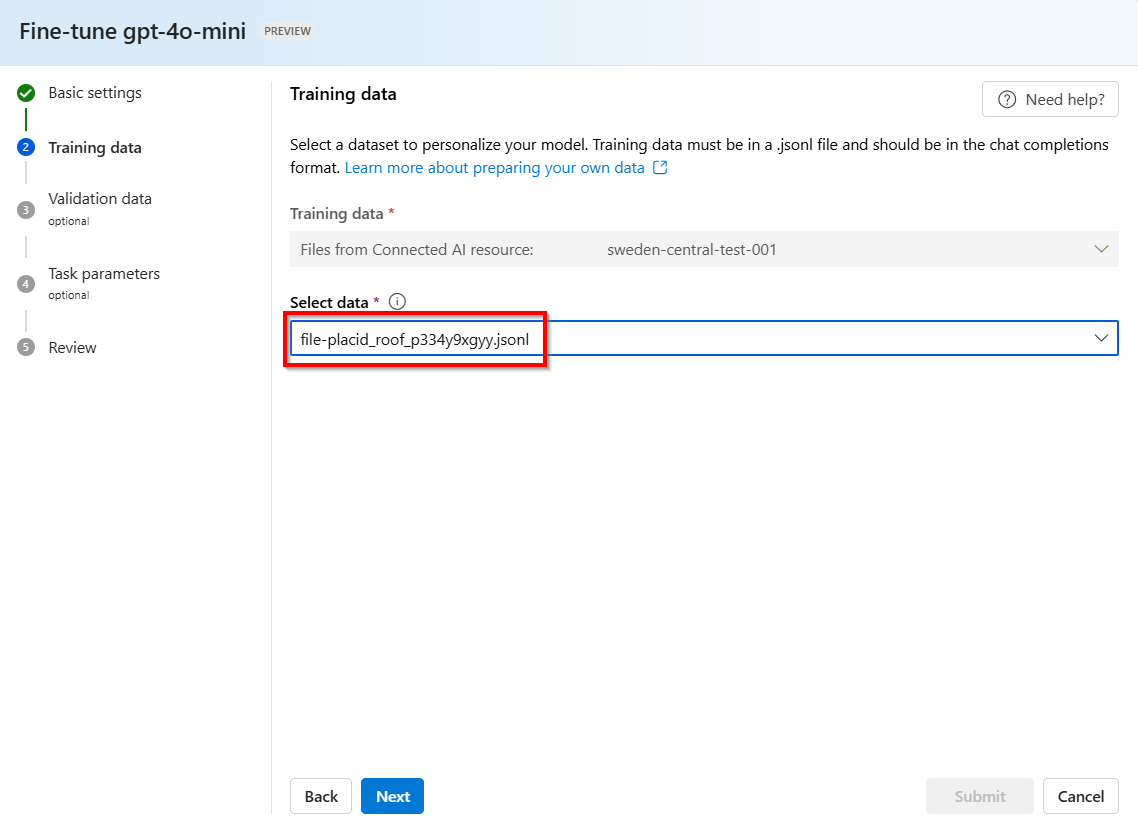
.jsonl隨機產生名稱的檔案將會從預存完成建立為定型數據集。 選取 [下一步] 檔案。>注意
無法直接存取預存完成精釀定型檔案,而且無法從外部/下載匯出。




其餘步驟會對應至一般的 Azure OpenAI 微調步驟。 若要深入瞭解,請參閱我們的 微調入門指南。
評估
大型 語言模型的評估 是測量不同工作和維度效能的重要步驟。 對於微調的模型來說,這特別重要,其中評估訓練的效能收益(或損失)非常重要。 徹底的評估可協助您瞭解不同版本的模型如何影響您的應用程式或案例。
預存完成可作為執行評估的數據集。
從 Azure AI Foundry 入口網站的 [預存完成] 窗格中,使用 [篩選] 選項來選取您想要成為評估數據集一部分的完成。
若要設定評估,請選取 [ 評估]
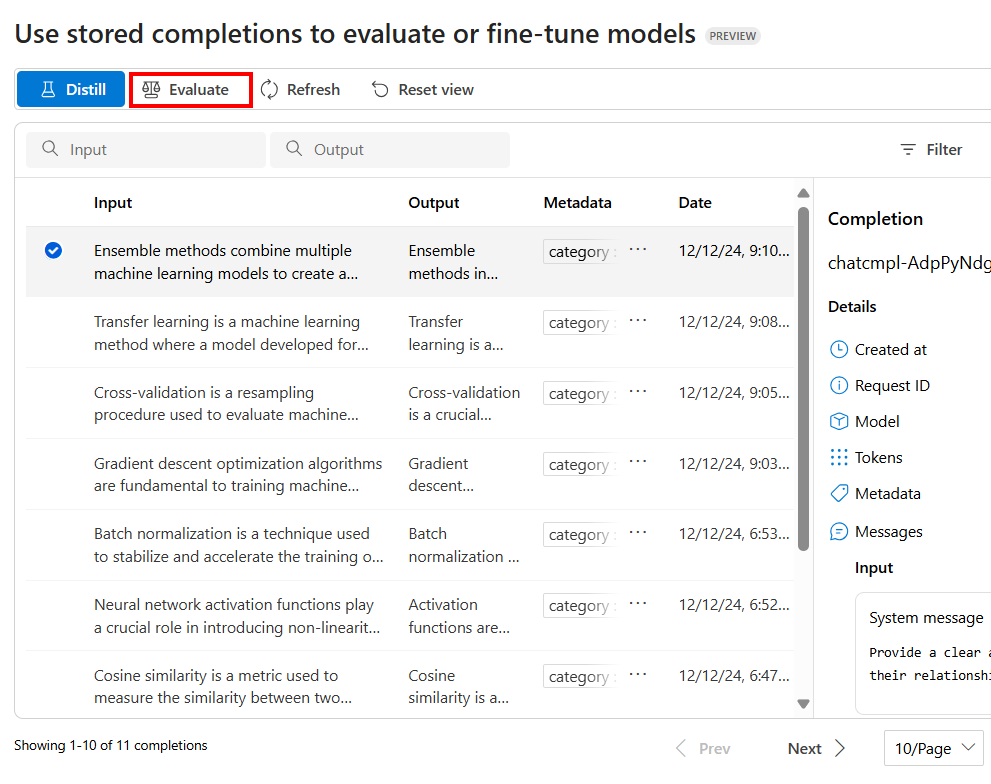
這會啟動 [評估 ] 窗格,其中包含預先填
.jsonl入的檔案,其中包含從預存完成建立為評估數據集的隨機產生名稱。注意
無法直接存取預存完成評估數據檔,而且無法從外部/下載匯出。


若要深入瞭解評估, 請參閱開始使用評估
疑難排解
我需要特殊許可權才能使用預存完成嗎?
預存完成存取是透過兩個 DataActions 來控制:
Microsoft.CognitiveServices/accounts/OpenAI/stored-completions/readMicrosoft.CognitiveServices/accounts/OpenAI/stored-completions/action
根據預設 Cognitive Services OpenAI Contributor ,可以存取這兩個許可權:

如何? 刪除儲存的數據嗎?
您可以藉由刪除相關聯的 Azure OpenAI 資源來刪除資料。 如果您只想要刪除預存的完成資料,您必須向客戶支持開啟案例。
我可以儲存多少預存完成數據?
您可以儲存最多 10 GB 的數據。
是否可以防止在訂用帳戶上啟用預存完成?
您必須向客戶支持開啟案例,才能停用訂用帳戶層級的預存完成。
TypeError:Completions.create() 收到非預期的自變數 'store'
當您執行較舊版本的 OpenAI 用戶端連結庫時,就會發生此錯誤,該連結庫會預先發行預存完成功能。 執行 pip install openai --upgrade。