如何改善自訂視覺模型
在本指南中,您將瞭解如何改善 自訂視覺 模型的品質。 分類器或物件偵測器的品質取決於您提供的已標示資料數量、品質及種類,以及整體資料集的平衡程度。 良好的模型具有平衡的定型數據集,可代表提交至該數據集的內容。 建置這類模型的程序為反覆程序,通常要進行幾個回合的定型,才會達到預期的結果。
以下是可協助您定型更精確模型的一般模式:
- 第一回合定型
- 新增更多影像並平衡資料;重新定型
- 新增背景、光源、物件大小、攝影機角度及樣式各異的影像;重新定型
- 使用新的影像來測試預測
- 根據預測結果修改現有的定型資料
防止過度學習
有時候,模型會學習根據影像共同擁有的任意特性進行預測。 例如,如果您建立蘋果與柑橘的分類器,且已使用手拿蘋果與白盤裝柑橘的影像,分類器可能過度重視手與白盤,而不是蘋果與柑橘。
若要更正這個問題,請提供具有不同角度、背景、物件大小、群組及其他變化的影像。 下列各節會根據這些概念進行擴充。
確定數據數量
定型影像數目是資料集最重要的因素。 建議您一開始每個標籤至少使用 50 個影像。 使用較少影像,過度學習的風險比較高,雖然您的效能數字可能暗示品質良好,但您的模型可能在與真實世界的資料奮戰。
確保數據平衡
此外,務必考慮定型資料的相對數量。 例如,對一個標籤使用 500 個影像且對另一個標籤使用 50 個影像,會讓定型資料集不平衡。 這會導致模型在預測一個標籤時比另一個標籤更精確。 如果影像最少的標籤與影像最多的標籤之間可至少維持 1:2 的比例,可能會看到較佳的結果。 例如,如果具有最多影像的標籤有 500 個影像,那麼最少影像的標籤應該至少有 250 個影像用於定型。
確保數據多樣性
務必使用代表在正常使用期間將送出到分類器的影像。 否則,模型可以學習如何根據您影像共同的任意特性進行預測。 例如,如果您建立蘋果與柑橘的分類器,且已使用手拿蘋果與白盤裝柑橘的影像,分類器可能過度重視手與白盤,而不是蘋果與柑橘。

若要更正這個問題,請包含各種影像,以確保模型可以妥善歸納。 以下一些方式可讓您的定型集更為多元:
背景:提供物件放在不同背景前方的影像。 自然內容中的相片會將更多資訊提供給分類器,所以比放在中性背景前方的相片更好。

光源:提供多樣化光源的影像 (也就是,以閃光燈、高曝光等方式拍攝等),特別是當用於預測的影像有不同的光源時。 對於使用具有各種飽和度、色調、亮度的影像也很有幫助。

物件大小:提供內含物件大小和數目不同的影像 (例如,多串香蕉的相片和單根香蕉的特寫)。 不同的大小可協助分類器更適當地一般化。

攝影機角度:提供以不同攝影機角度拍攝的影像。 或者,如果所有相片都必須以固定式相機 (例如,監視相機) 拍攝,請務必對每個定期發生的物件指派不同的標籤,以避免過度學習—將不相關的物件 (例如,路燈柱) 解讀為主要特徵。

樣式:提供類別相同但樣式不同的影像 (例如,各種同類水果)。 不過,如果您有樣式迥異的物件 (例如米老鼠與現實中的老鼠),建議您分別標示為不同類別,更清楚地表示不同的特徵。

使用負影像 (僅限分類器)
如果您使用影像分類器,您可能需要新增 負樣本 ,以協助分類器更精確。 負面樣本是不符合其他任何標籤的影像。 您上傳這些影像時,將特別的 [負向] 標籤套用於影像。
物件偵測器會自動處理負面樣本,因為繪製周框方塊以外的任何影像區域都會被視為負的。
注意
自訂視覺服務支援某些自動處理負片的功能。 例如,如果您正在建置葡萄與香蕉的分類器,並送出了一隻鞋子的影像進行預測,則分類器應該會針對葡萄與香蕉,將該影像評分為接近 0%。
反過來說,如果負類影像只是用來定型之影像的變化,由於相似度極高,模型很可能會將負類影像分類為標記的類別。 例如,如果有一個柳橙與葡萄柚分類器,但您饋送小柑橘的影像,它可能會將小柑橘評分為柳橙,因為小柑橘有許多和柳橙類似的特徵。 如果您的負面影像屬於此性質,建議您在定型期間建立一或多個額外的標記(例如 Other),並在定型期間使用這個標籤來標記負影像,讓模型能夠更好地區分這些類別。
處理遮蔽和截斷 (僅限物件偵測器)
如果您想要物件偵測器偵測截斷的物件 (已將部分物件從影像中剪下) 或被遮蔽的物件 (物件被影像中其他物件擋住),則您必須包含涵蓋這些案例的定型影像。
注意
其他物件所遮蔽的物件問題不會與重疊閾值混淆,也就是分級模型效能的參數。 自訂視覺網站上的重疊閾值滑杆會處理預測的周框方塊必須與真正的周框方塊重疊多少,才算正確。
使用預測影像以供進一步定型
當您藉由將影像送出到預測端點來使用或測試模型時,自訂視覺服務會儲存這些影像。 您可以接著使用它們來改善模型。
若要檢視送出到模型的影像,開啟自訂視覺網頁 \(英文\),前往您的專案,然後選取 [預測] 索引標籤。預設檢視會顯示來自目前反覆項目的影像。 您可以使用 [反覆項目] 下拉式功能表欄位,來檢視在先前反覆項目期間送出的影像。
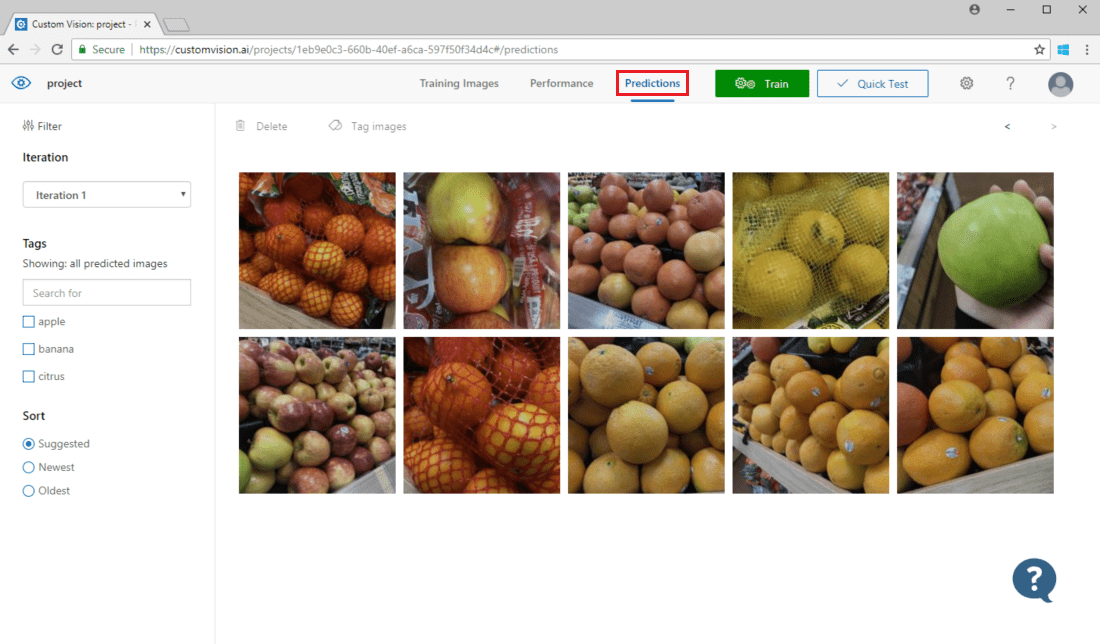
將滑鼠停留在影像上方,以查看由模型所預測的標籤。 影像會排序,如此一來,可為模型帶來最大改善的影像就會列在最上方。 若要使用不同的排序方法,請在 [排序] 區段中進行選取。
若要將影像新增到現有定型資料,請選取影像、設定正確的標籤,然後選取 [儲存並關閉]。 影像會從 預測 中移除,並新增至定型影像集。 您可以選取 [定型影像] 索引標籤加以檢視。
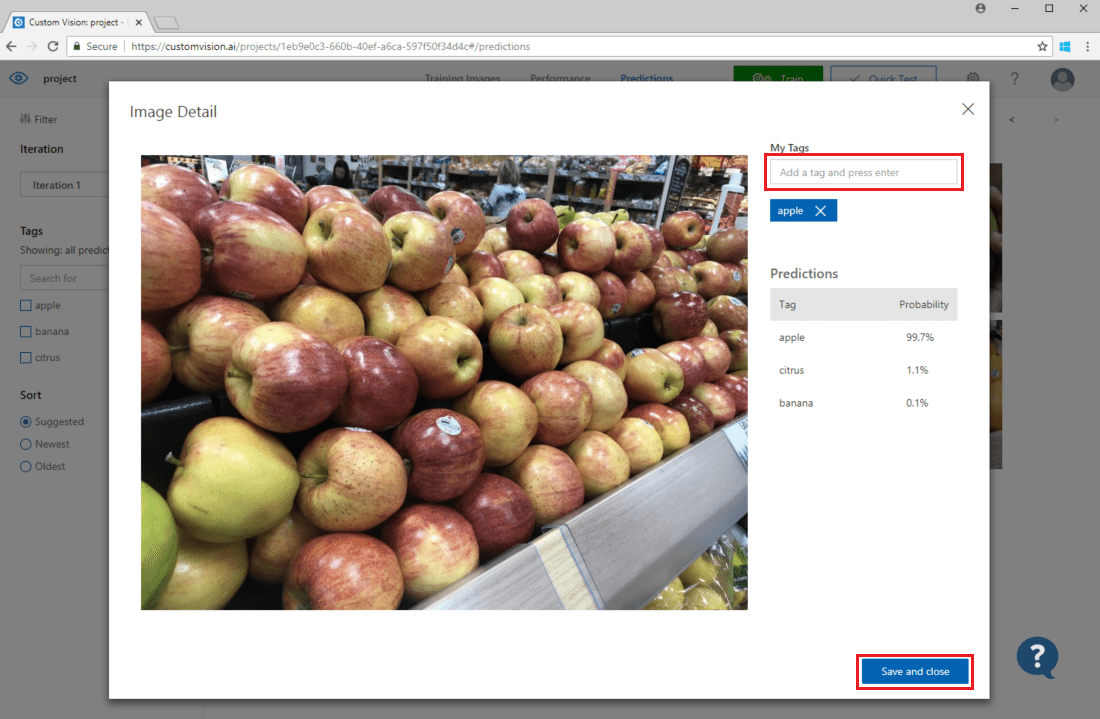
然後使用 [定型] 按鈕來重新定型模型。
以視覺化方式檢查預測
若要檢查影像預測,請移至 [定型影像] 索引標籤,在 [反覆項目] 下拉式功能表中選取您先前的定型反覆項目,,然後檢查 [標記] 區段下的一或多個標記。 檢視現在應該在模型無法正確預測指定標記的每個影像周圍顯示紅色方塊。
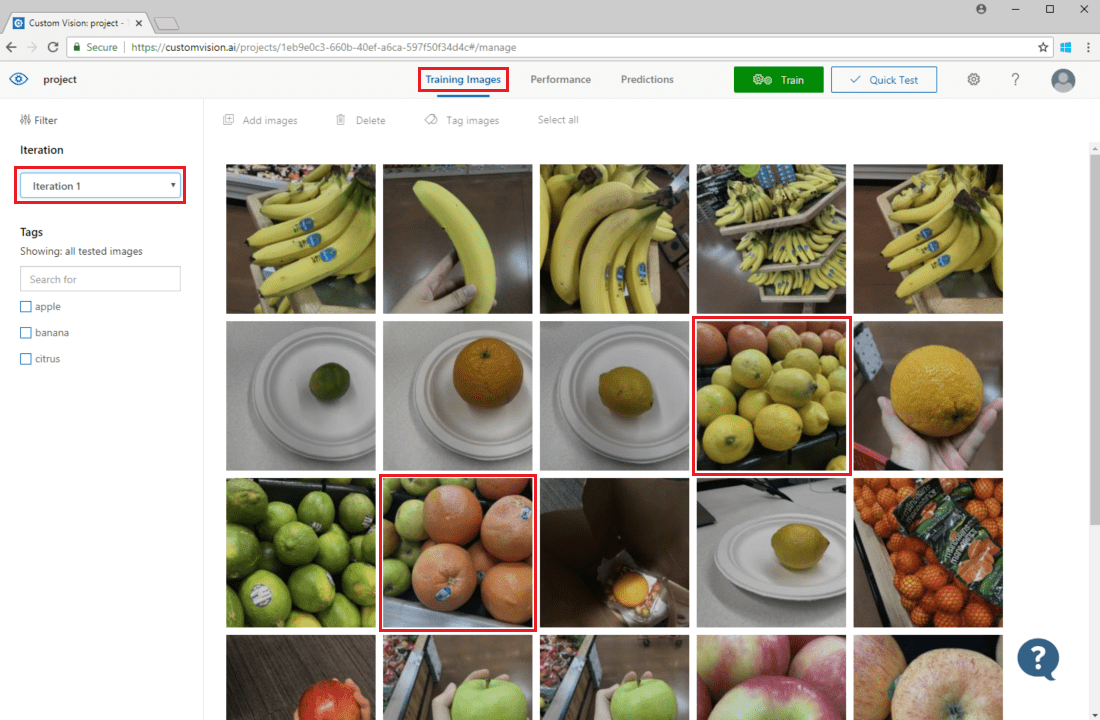
有時,視覺檢查可以識別出您接著可藉由新增更多定型資料,或修改現有定型資料來更正的模式。 例如,蘋果與萊姆的分類器錯誤地將所有青蘋果加上萊姆的標籤。 您可接著讓定型資料包含已標記青蘋果的影像,然後新增並提供此定型資料,藉以更正此問題。
後續步驟
在本指南中,您已了解數種讓自訂影像分類模型或物件偵測器模型更加精確的技術。 接下來,了解如何藉由將影像送出到預測 API,以程式設計方式測試它們。