如何使用 Azure AI 模型推斷產生內嵌
重要
本文中標示為 (預覽) 的項目目前處於公開預覽狀態。 此預覽版本沒有服務等級協定,不建議將其用於生產工作負載。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
本文說明如何在 Azure AI 服務中使用內嵌 API 搭配部署至 Azure AI 模型推斷的模型。
必要條件
若要在應用程式中使用內嵌模型,您需要:
Azure 訂用帳戶。 如果您使用 GitHub Models,您可以升級您的體驗,並在程式中建立 Azure 訂用帳戶。 如果您的情況,請閱讀 從 GitHub 模型升級至 Azure AI 模型推斷 。
Azure AI 服務資源。 如需詳細資訊,請參閱 建立 Azure AI 服務資源。
端點 URL 和金鑰。
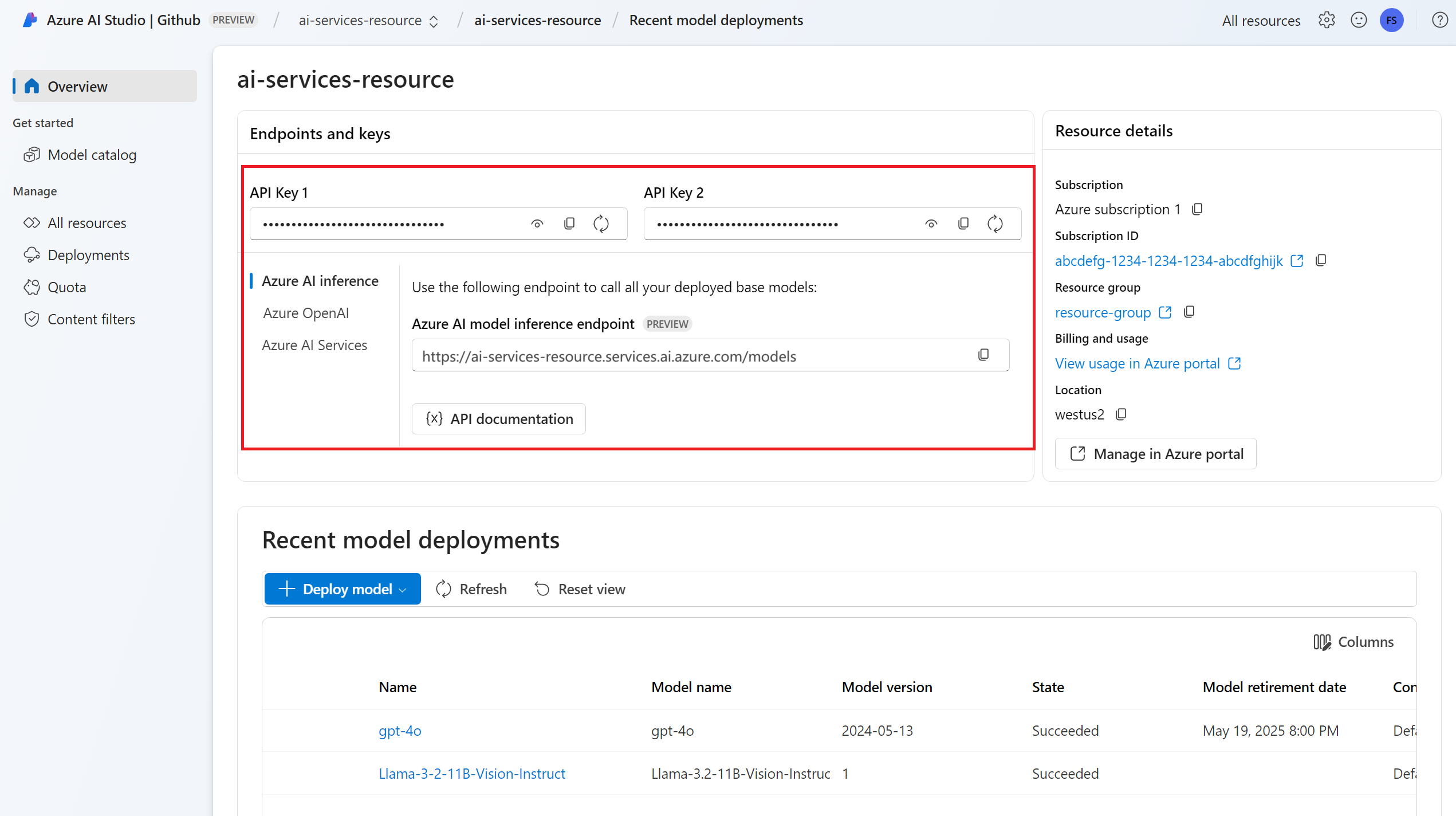

內嵌模型部署。 如果您沒有一個讀取 將模型新增並設定至 Azure AI 服務 ,以將內嵌模型新增至您的資源。
使用下列命令安裝 Azure AI 推斷套件:
pip install -U azure-ai-inference
使用內嵌
首先,建立用戶端以取用模型。 下列程式碼會使用儲存在環境變數中的端點 URL 和金鑰。
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="text-embedding-3-small"
)
如果您已將資源設定為 Microsoft Entra ID 支援,您可以使用下列代碼段來建立用戶端。
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="text-embedding-3-small"
)
建立內嵌
建立內嵌要求以查看模型的輸出。
response = model.embed(
input=["The ultimate answer to the question of life"],
)
提示
建立要求時,請考慮到模型的令牌輸入限制。 如果您需要內嵌較大的文字部分,則需要區塊化策略。
回應如下,其中您可以查看模型的使用量統計資料:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
在輸入批次中計算內嵌很實用。 參數 inputs 可以是字串清單,其中每個字串都是不同的輸入。 接著,回應是內嵌的清單,其中每個內嵌都會對應至相同位置的輸入。
response = model.embed(
input=[
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
)
回應如下,其中您可以查看模型的使用量統計資料:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
提示
建立要求批次時,請考慮到每個模型的批次限制。 大部分的模型都有1024批次限制。
指定內嵌維度
您可以指定內嵌的維度數目。 下列範例程式代碼示範如何使用 1024 維度建立內嵌。 請注意,並非所有內嵌模型都支援指出要求中的維度數目,而且在這些情況下會傳回 422 錯誤。
response = model.embed(
input=["The ultimate answer to the question of life"],
dimensions=1024,
)
建立不同類型的內嵌
根據您打算如何使用這些模型,某些模型可以針對相同的輸入產生多個內嵌。 此功能可讓您針對 RAG 模式擷取更精確的內嵌。
下列範例示範如何建立內嵌,其用來建立將儲存在向量資料庫中之文件的內嵌:
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type=EmbeddingInputType.DOCUMENT,
)
當您處理查詢以擷取這類文件時,您可以使用下列程式碼片段來建立查詢的內嵌,並將擷取效能最大化。
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["What's the ultimate meaning of life?"],
input_type=EmbeddingInputType.QUERY,
)
請注意,並非所有內嵌模型都支援指出要求中的輸入類型,而且在這些情況下會傳回 422 錯誤。 根據預設,會傳回 型 Text 別的內嵌。
重要
本文中標示為 (預覽) 的項目目前處於公開預覽狀態。 此預覽版本沒有服務等級協定,不建議將其用於生產工作負載。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
本文說明如何在 Azure AI 服務中使用內嵌 API 搭配部署至 Azure AI 模型推斷的模型。
必要條件
若要在應用程式中使用內嵌模型,您需要:
Azure 訂用帳戶。 如果您使用 GitHub Models,您可以升級您的體驗,並在程式中建立 Azure 訂用帳戶。 如果您的情況,請閱讀 從 GitHub 模型升級至 Azure AI 模型推斷 。
Azure AI 服務資源。 如需詳細資訊,請參閱 建立 Azure AI 服務資源。
端點 URL 和金鑰。
內嵌模型部署。 如果您沒有一個讀取 將模型新增並設定至 Azure AI 服務 ,以將內嵌模型新增至您的資源。
使用下列命令安裝適用於 JavaScript 的 Azure 推斷連結庫:
npm install @azure-rest/ai-inference
使用內嵌
首先,建立用戶端以取用模型。 下列程式碼會使用儲存在環境變數中的端點 URL 和金鑰。
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL),
"text-embedding-3-small"
);
如果您已將資源設定為 Microsoft Entra ID 支援,您可以使用下列代碼段來建立用戶端。
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential(),
"text-embedding-3-small"
);
建立內嵌
建立內嵌要求以查看模型的輸出。
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
}
});
提示
建立要求時,請考慮到模型的令牌輸入限制。 如果您需要內嵌較大的文字部分,則需要區塊化策略。
回應如下,其中您可以查看模型的使用量統計資料:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
在輸入批次中計算內嵌很實用。 參數 inputs 可以是字串清單,其中每個字串都是不同的輸入。 接著,回應是內嵌的清單,其中每個內嵌都會對應至相同位置的輸入。
var response = await client.path("/embeddings").post({
body: {
input: [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
}
});
回應如下,其中您可以查看模型的使用量統計資料:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
提示
建立要求批次時,請考慮到每個模型的批次限制。 大部分的模型都有1024批次限制。
指定內嵌維度
您可以指定內嵌的維度數目。 下列範例程式代碼示範如何使用 1024 維度建立內嵌。 請注意,並非所有內嵌模型都支援指出要求中的維度數目,而且在這些情況下會傳回 422 錯誤。
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
dimensions: 1024,
}
});
建立不同類型的內嵌
根據您打算如何使用這些模型,某些模型可以針對相同的輸入產生多個內嵌。 此功能可讓您針對 RAG 模式擷取更精確的內嵌。
下列範例示範如何建立內嵌,其用來建立將儲存在向量資料庫中之文件的內嵌:
var response = await client.path("/embeddings").post({
body: {
input: ["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type: "document",
}
});
當您處理查詢以擷取這類文件時,您可以使用下列程式碼片段來建立查詢的內嵌,並將擷取效能最大化。
var response = await client.path("/embeddings").post({
body: {
input: ["What's the ultimate meaning of life?"],
input_type: "query",
}
});
請注意,並非所有內嵌模型都支援指出要求中的輸入類型,而且在這些情況下會傳回 422 錯誤。 根據預設,會傳回 型 Text 別的內嵌。
重要
本文中標示為 (預覽) 的項目目前處於公開預覽狀態。 此預覽版本沒有服務等級協定,不建議將其用於生產工作負載。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
本文說明如何在 Azure AI 服務中使用內嵌 API 搭配部署至 Azure AI 模型推斷的模型。
必要條件
若要在應用程式中使用內嵌模型,您需要:
Azure 訂用帳戶。 如果您使用 GitHub Models,您可以升級您的體驗,並在程式中建立 Azure 訂用帳戶。 如果您的情況,請閱讀 從 GitHub 模型升級至 Azure AI 模型推斷 。
Azure AI 服務資源。 如需詳細資訊,請參閱 建立 Azure AI 服務資源。
端點 URL 和金鑰。
內嵌模型部署。 如果您沒有一個讀取 將模型新增並設定至 Azure AI 服務 ,以將內嵌模型新增至您的資源。
將 Azure AI 推斷套件新增至您的專案:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>如果您使用 Entra ID,則也需要下列套件:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>匯入下列命名空間:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
使用內嵌
首先,建立用戶端以取用模型。 下列程式碼會使用儲存在環境變數中的端點 URL 和金鑰。
EmbeddingsClient client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(System.getProperty("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
如果您已將資源設定為 Microsoft Entra ID 支援,您可以使用下列代碼段來建立用戶端。
client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(),
"text-embedding-3-small"
);
建立內嵌
建立內嵌要求以查看模型的輸出。
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList("The ultimate answer to the question of life"));
Response<EmbeddingsResult> response = client.embed(requestOptions);
提示
建立要求時,請考慮到模型的令牌輸入限制。 如果您需要內嵌較大的文字部分,則需要區塊化策略。
回應如下,其中您可以查看模型的使用量統計資料:
System.out.println("Embedding: " + response.getValue().getData());
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
在輸入批次中計算內嵌很實用。 參數 inputs 可以是字串清單,其中每個字串都是不同的輸入。 接著,回應是內嵌的清單,其中每個內嵌都會對應至相同位置的輸入。
requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList(
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
));
response = client.embed(requestOptions);
回應如下,其中您可以查看模型的使用量統計資料:
提示
建立要求批次時,請考慮到每個模型的批次限制。 大部分的模型都有1024批次限制。
指定內嵌維度
您可以指定內嵌的維度數目。 下列範例程式代碼示範如何使用 1024 維度建立內嵌。 請注意,並非所有內嵌模型都支援指出要求中的維度數目,而且在這些情況下會傳回 422 錯誤。
建立不同類型的內嵌
根據您打算如何使用這些模型,某些模型可以針對相同的輸入產生多個內嵌。 此功能可讓您針對 RAG 模式擷取更精確的內嵌。
下列範例示範如何建立內嵌,其用來建立將儲存在向量資料庫中之文件的內嵌:
List<String> input = Arrays.asList("The answer to the ultimate question of life, the universe, and everything is 42");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
response = client.embed(requestOptions);
當您處理查詢以擷取這類文件時,您可以使用下列程式碼片段來建立查詢的內嵌,並將擷取效能最大化。
input = Arrays.asList("What's the ultimate meaning of life?");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
response = client.embed(requestOptions);
請注意,並非所有內嵌模型都支援指出要求中的輸入類型,而且在這些情況下會傳回 422 錯誤。 根據預設,會傳回 型 Text 別的內嵌。
重要
本文中標示為 (預覽) 的項目目前處於公開預覽狀態。 此預覽版本沒有服務等級協定,不建議將其用於生產工作負載。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
本文說明如何在 Azure AI 服務中使用內嵌 API 搭配部署至 Azure AI 模型推斷的模型。
必要條件
若要在應用程式中使用內嵌模型,您需要:
Azure 訂用帳戶。 如果您使用 GitHub Models,您可以升級您的體驗,並在程式中建立 Azure 訂用帳戶。 如果您的情況,請閱讀 從 GitHub 模型升級至 Azure AI 模型推斷 。
Azure AI 服務資源。 如需詳細資訊,請參閱 建立 Azure AI 服務資源。
端點 URL 和金鑰。
內嵌模型部署。 如果您沒有一個讀取 將模型新增並設定至 Azure AI 服務 ,以將內嵌模型新增至您的資源。
使用下列命令安裝 Azure AI 推斷套件:
dotnet add package Azure.AI.Inference --prerelease如果您使用 Entra ID,則也需要下列套件:
dotnet add package Azure.Identity
使用內嵌
首先,建立用戶端以取用模型。 下列程式碼會使用儲存在環境變數中的端點 URL 和金鑰。
EmbeddingsClient client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
如果您已將資源設定為 Microsoft Entra ID 支援,您可以使用下列代碼段來建立用戶端。
client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(includeInteractiveCredentials: true),
"text-embedding-3-small"
);
建立內嵌
建立內嵌要求以查看模型的輸出。
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life"
},
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
提示
建立要求時,請考慮到模型的令牌輸入限制。 如果您需要內嵌較大的文字部分,則需要區塊化策略。
回應如下,其中您可以查看模型的使用量統計資料:
Console.WriteLine($"Embedding: {response.Value.Data}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
在輸入批次中計算內嵌很實用。 參數 inputs 可以是字串清單,其中每個字串都是不同的輸入。 接著,回應是內嵌的清單,其中每個內嵌都會對應至相同位置的輸入。
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
},
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
回應如下,其中您可以查看模型的使用量統計資料:
提示
建立要求批次時,請考慮到每個模型的批次限制。 大部分的模型都有1024批次限制。
指定內嵌維度
您可以指定內嵌的維度數目。 下列範例程式代碼示範如何使用 1024 維度建立內嵌。 請注意,並非所有內嵌模型都支援指出要求中的維度數目,而且在這些情況下會傳回 422 錯誤。
建立不同類型的內嵌
根據您打算如何使用這些模型,某些模型可以針對相同的輸入產生多個內嵌。 此功能可讓您針對 RAG 模式擷取更精確的內嵌。
下列範例示範如何建立內嵌,其用來建立將儲存在向量資料庫中之文件的內嵌:
var input = new List<string> {
"The answer to the ultimate question of life, the universe, and everything is 42"
};
var requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
Response<EmbeddingsResult> response = client.Embed(requestOptions);
當您處理查詢以擷取這類文件時,您可以使用下列程式碼片段來建立查詢的內嵌,並將擷取效能最大化。
var input = new List<string> {
"What's the ultimate meaning of life?"
};
var requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
Response<EmbeddingsResult> response = client.Embed(requestOptions);
請注意,並非所有內嵌模型都支援指出要求中的輸入類型,而且在這些情況下會傳回 422 錯誤。 根據預設,會傳回 型 Text 別的內嵌。
重要
本文中標示為 (預覽) 的項目目前處於公開預覽狀態。 此預覽版本沒有服務等級協定,不建議將其用於生產工作負載。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
本文說明如何在 Azure AI 服務中使用內嵌 API 搭配部署至 Azure AI 模型推斷的模型。
必要條件
若要在應用程式中使用內嵌模型,您需要:
Azure 訂用帳戶。 如果您使用 GitHub Models,您可以升級您的體驗,並在程式中建立 Azure 訂用帳戶。 如果您的情況,請閱讀 從 GitHub 模型升級至 Azure AI 模型推斷 。
Azure AI 服務資源。 如需詳細資訊,請參閱 建立 Azure AI 服務資源。
端點 URL 和金鑰。
- 內嵌模型部署。 如果您沒有一個讀取 將模型新增並設定至 Azure AI 服務 ,以將內嵌模型新增至您的資源。
使用內嵌
若要使用文字內嵌,請使用附加至基底 URL 的路由 /embeddings ,以及 中 api-key指示的認證。
Authorization 格式也支持 Bearer <key>標頭。
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
如果您已使用 Microsoft Entra ID 支援來設定資源,請在標頭中 Authorization 傳遞令牌:
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
建立內嵌
建立內嵌要求以查看模型的輸出。
{
"model": "text-embedding-3-small",
"input": [
"The ultimate answer to the question of life"
]
}
提示
建立要求時,請考慮到模型的令牌輸入限制。 如果您需要內嵌較大的文字部分,則需要區塊化策略。
回應如下,其中您可以查看模型的使用量統計資料:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 9,
"completion_tokens": 0,
"total_tokens": 9
}
}
在輸入批次中計算內嵌很實用。 參數 inputs 可以是字串清單,其中每個字串都是不同的輸入。 接著,回應是內嵌的清單,其中每個內嵌都會對應至相同位置的輸入。
{
"model": "text-embedding-3-small",
"input": [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
]
}
回應如下,其中您可以查看模型的使用量統計資料:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
},
{
"index": 1,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 19,
"completion_tokens": 0,
"total_tokens": 19
}
}
提示
建立要求批次時,請考慮到每個模型的批次限制。 大部分的模型都有1024批次限制。
指定內嵌維度
您可以指定內嵌的維度數目。 下列範例程式代碼示範如何使用 1024 維度建立內嵌。 請注意,並非所有內嵌模型都支援指出要求中的維度數目,而且在這些情況下會傳回 422 錯誤。
{
"model": "text-embedding-3-small",
"input": [
"The ultimate answer to the question of life"
],
"dimensions": 1024
}
建立不同類型的內嵌
根據您打算如何使用這些模型,某些模型可以針對相同的輸入產生多個內嵌。 此功能可讓您針對 RAG 模式擷取更精確的內嵌。
下列範例示範如何建立內嵌,用來建立將儲存在向量資料庫中之檔的內嵌。 由於 text-embedding-3-small 不支援這項功能,因此我們會在下列範例中使用 Cohere 的內嵌模型:
{
"model": "cohere-embed-v3-english",
"input": [
"The answer to the ultimate question of life, the universe, and everything is 42"
],
"input_type": "document"
}
當您處理查詢以擷取這類文件時,您可以使用下列程式碼片段來建立查詢的內嵌,並將擷取效能最大化。 由於 text-embedding-3-small 不支援這項功能,因此我們會在下列範例中使用 Cohere 的內嵌模型:
{
"model": "cohere-embed-v3-english",
"input": [
"What's the ultimate meaning of life?"
],
"input_type": "query"
}
請注意,並非所有內嵌模型都支援指出要求中的輸入類型,而且在這些情況下會傳回 422 錯誤。 根據預設,會傳回 型 Text 別的內嵌。