Azure Data Factory 和 Synapse Analytics (舊版) 中支援的檔案格式和壓縮轉碼器
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
此文章適用於下列連接器:Amazon S3、Azure Blob、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2、Azure 檔案儲存體、檔案系統、FTP、Google 雲端儲存空間、HDFS、HTTP和 SFTP。
重要
服務引進了以格式為基礎的新資料集模型,請參閱對應的格式文章,其中包含下列詳細資料:
-
Avro 格式
-
二進位格式
-
分隔符號文字格式
-
JSON 格式
-
ORC 格式
-
Parquet 格式
本文中所述的其餘組態仍受支援,以保持回溯相容性。 建議您未來使用新的模型。
文字格式 (舊版)
注意
了解分隔符號文字格式文章中的新模型。 檔案型數據存放區數據集上的下列組態仍受支援,以符合回溯相容性。 建議您未來使用新的模型。
如果您想要從文字檔讀取或寫入至文字檔,請將資料集之 format 區段中的 type 屬性設定成 TextFormat。 您也可以在 format 區段中指定下列選擇性屬性。 關於如何設定,請參閱 TextFormat 範例一節。
| 屬性 | 說明 | 允許的值 | 必要 |
|---|---|---|---|
| columnDelimiter | 用來分隔檔案中的資料行的字元。 您可以考慮使用資料中不太可能存在的罕見不可列印字元。 例如,指定 "\u0001",這代表「標題開頭」(SOH)。 | 只允許一個字元。
預設值是逗號 (',')。 若要使用 Unicode 字元,請參考 Unicode 字元 (英文) 以取得其對應的代碼。 |
No |
| rowDelimiter | 用來分隔檔案中資料列的字元。 | 只允許一個字元。 預設值是下列任一個值:["\r\n", "\r", "\n"] (讀取時) 與 "\r\n" (寫入時)。 | No |
| escapeChar | 用來逸出輸入檔內容中資料行分隔符號的特殊字元。 您無法為資料表同時指定 escapeChar 和 quoteChar。 |
只允許一個字元。 無預設值。 例如,如果您以逗號 (',') 做為資料行分隔符號,但您想要在文字中使用逗號字元 (例如:"Hello, world"),您可以定義 '$' 做為逸出字元,並在來源中使用字串 "Hello$, world"。 |
No |
| quoteChar | 用來為字串值加上引號的字元。 系統會將引號字元內資料行和資料列分隔符號視為字串值的一部分。 這個屬性同時適用於輸入和輸出資料集。 您無法為資料表同時指定 escapeChar 和 quoteChar。 |
只允許一個字元。 無預設值。 例如,如果您以逗號 (',') 做為資料行分隔符號,但您想要在文字中使用逗號字元 (例如:<Hello, world>),您可以定義 " (雙引號) 作為引用字元,並在來源中使用字串 "Hello, world"。 |
No |
| nullValue | 用來代表 Null 值的一或多個字元。 | 一或多個字元。 預設值為 "\N" 和 "NULL" (讀取時) 及 "\N" (寫入時)。 | No |
| encodingName | 指定編碼名稱。 | 有效的編碼名稱。 請參閱 Encoding.EncodingName 屬性。 例如:windows-1250 或 shift_jis。 預設值為 UTF-8。 | No |
| firstRowAsHeader | 指定是否將第一個資料列視為標頭。 對於輸入資料集,服務會讀取第一個資料列作為標頭。 對於輸出資料集,服務會寫入第一個資料列作為標頭。 相關範例案例請參閱使用 firstRowAsHeader 和 skipLineCount 的案例。 |
True False (預設值) |
No |
| skipLineCount | 指出從輸入檔讀取資料時,要略過的非空白資料列數。 如果同時指定 skipLineCount 和 firstRowAsHeader,則會先略過行,然後從輸入檔讀取標頭資訊。 相關範例案例請參閱使用 firstRowAsHeader 和 skipLineCount 的案例。 |
整數 | No |
| treatEmptyAsNull | 指定從輸入檔讀取資料時是否將 Null 或空字串視為 Null 值。 |
True (預設值) False |
No |
TextFormat 範例
在以下的資料集 JSON 定義中,已指定一些選擇性屬性。
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
若要使用 escapeChar 而不是quoteChar,請使用下列 escapeChar 取代含有 quoteChar 的那一行:
"escapeChar": "$",
使用 firstRowAsHeader 和 skipLineCount 的案例
- 您正從非檔案來源複製到文字檔,並想要加入標頭行,其中包含結構描述中繼資料 (例如︰SQL 結構描述)。 在此案例的輸出資料集,將
firstRowAsHeader指定為 true。 - 您正從包含標頭行的文字檔複製到非檔案接收器,並想要刪除那一行。 在輸入資料集,將
firstRowAsHeader指定為 true。 - 您正從文字檔複製,並想略過不包含資料或標頭資訊的開頭幾行。 指定
skipLineCount以表示要略過的行數。 如果檔案其餘部分包含標頭行,您也可以指定firstRowAsHeader。 如果skipLineCount和firstRowAsHeader都指定,則會先略過那幾行,再從輸入檔讀取標頭資訊
JSON 格式 (舊版)
注意
透過 JSON 格式文章了解新的模型。 檔案型數據存放區數據集上的下列組態仍受支援,以符合回溯相容性。 建議您未來使用新的模型。
若要將 JSON 檔案原封不動匯入到 Azure Cosmos DB 或從中匯出,請參閱將資料移進/移出 Azure Cosmos DB 一文中的「匯入/匯出 JSON 文件」一節。
如果您想要剖析 JSON 檔案,或以 JSON 格式寫入資料,請將 format 區段中的 type 屬性設定成 JsonFormat。 您也可以在 format 區段中指定下列選擇性屬性。 關於如何設定,請參閱 JsonFormat 範例一節。
| 屬性 | 描述 | 必要 |
|---|---|---|
| filePattern | 表示每個 JSON 檔案中儲存的資料模式。 允許的值為︰setOfObjects 和 arrayOfObjects。 預設值為 setOfObjects。 關於這些模式的詳細資訊,請參閱 JSON 檔案模式一節。 | No |
| jsonNodeReference | 如果您想要逐一查看陣列欄位內相同模式的物件並擷取資料,請指定該陣列的 JSON 路徑。 從 JSON 檔案複製資料時,才支援這個屬性。 | No |
| jsonPathDefinition | 指定 JSON 路徑運算式,以自訂資料行名稱來對應每個資料行 (開頭為小寫)。
從 JSON 檔案複製資料時,才支援這個屬性,而您可以從物件或陣列中擷取資料。 如果是根物件下的欄位,請從根 $ 開始,如果是 jsonNodeReference 屬性所選陣列內的欄位,請從陣列元素開始。 關於如何設定,請參閱 JsonFormat 範例一節。 |
No |
| encodingName | 指定編碼名稱。 如需有效編碼名稱的清單,請參閱: Encoding.EncodingName 屬性。 例如:windows-1250 或 shift_jis。 預設值為 UTF-8。 | No |
| nestingSeparator | 用來分隔巢狀層級的字元。 預設值為 '.' (點)。 | No |
注意
針對將陣列中的資料交叉套用至多個資料列的情況 (案例 1 - JsonFormat 範例 中的範例 2 >),您僅可選擇使用屬性 jsonNodeReference 展開單一陣列。
JSON 檔案模式
複製活動可以剖析下列 JSON 檔案模式︰
類型 I:setOfObjects
每個檔案都會包含單一物件,或以行分隔/串連的多個物件。 在輸出資料集中選擇此選項時,複製活動會產生單一 JSON 檔案,每行一個物件 (以行分隔)。
單一物件 JSON 範例
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }以行分隔的 JSON 範例
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}串連的 JSON 範例
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
類型 II:arrayOfObjects
每個檔案都會包含物件的陣列。
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
JsonFormat 範例
案例 1︰從 JSON 檔案複製資料
範例 1︰從物件和陣列擷取資料
在此範例中,預計會有一個根 JSON 物件對應至表格式結果中的單一記錄。 如果您的 JSON 檔案含有下列內容:
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
而且想要使用下列格式,將它複製到 Azure SQL 資料表,請同時從物件和陣列擷取資料︰
| 識別碼 | deviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | 電腦 | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 1/13/2017 11:24:37 AM |
JsonFormat 類型的輸入資料集定義如下:(僅含相關元素的局部定義)。 更明確地說:
-
structure區段定義自訂資料行名稱,以及轉換成表格式資料時對應的資料類型。 除非您需要對應資料行,否則這個區段是選擇性。 如需詳細資訊,請參閱將來源資料集資料行對應至目的地資料集資料行。 -
jsonPathDefinition指定每個資料行的 JSON 路徑,以指出從哪裡擷取資料。 若要從陣列複製資料,您可以使用array[x].property從第xth個物件擷取指定屬性的值,也可以使用array[*].property從包含這類屬性的物件中尋找此值。
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
範例 2︰交叉套用陣列中具有相同模式的多個物件
在此範例中,預計會將一個根 JSON 物件轉換成表格式結果中的多筆記錄。 如果您的 JSON 檔案含有下列內容:
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
您想要簡維陣列內的資料,將內容複製到下列格式的 Azure SQL 資料表,並與一般根資訊交叉聯結︰
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
JsonFormat 類型的輸入資料集定義如下:(僅含相關元素的局部定義)。 更明確地說:
-
structure區段定義自訂資料行名稱,以及轉換成表格式資料時對應的資料類型。 除非您需要對應資料行,否則這個區段是選擇性。 如需詳細資訊,請參閱將來源資料集資料行對應至目的地資料集資料行。 -
jsonNodeReference表示逐一查看陣列orderlines下相同模式的物件並擷取資料。 -
jsonPathDefinition指定每個資料行的 JSON 路徑,以指出從哪裡擷取資料。 在此範例中,ordernumber、orderdate和city位於根物件下,JSON 路徑開頭為$.,而order_pd和order_price以衍生自陣列元素的路徑定義,不含$.。
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
請注意下列幾點:
- 如果資料集中未定義
structure和jsonPathDefinition,複製活動會偵測第一個物件的結構描述,並簡維整個物件。 - 如果 JSON 輸入具有陣列,依預設,複製活動會將整個陣列值轉換為字串。 您可以選擇使用
jsonNodeReference及/或jsonPathDefinition從其中擷取資料,或不要在jsonPathDefinition中指定以略過它。 - 如果相同層級中有重複的名稱,複製活動會挑選最後一個。
- 屬性名稱會區分大小寫。 名稱相同但大小寫不同的兩個屬性會被視為兩個不同的屬性。
案例 2︰將資料寫入 JSON 檔案
如果您在 SQL Database 中有下列資料表︰
| 識別碼 | order_date | order_price | order_by |
|---|---|---|---|
| 1 | 20170119 | 2000 | David |
| 2 | 20170120 | 3500 | Patrick |
| 3 | 20170121 | 4000 | Jason |
而針對每一筆記錄,您預期以下列格式寫入 JSON 物件︰
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
JsonFormat 類型的輸出資料集定義如下:(僅含相關元素的局部定義)。 更具體來說,structure 區段會定義目的檔案中的自訂屬性名稱,nestingSeparator (預設值是 ".") 則用來識別名稱中的巢狀層。 除非您想要變更屬性名稱與來源資料行名稱之間的對照,或巢狀化某些屬性,否則這個區段是選擇性。
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Parquet 格式 (舊版)
注意
透過 Parquet 格式文章了解新的模型。 檔案型數據存放區數據集上的下列組態仍受支援,以符合回溯相容性。 建議您未來使用新的模型。
如果您想要剖析 Parquet 檔案,或以 Parquet 格式寫入資料,請將 formattype 屬性設定為 ParquetFormat。 您不需要在 typeProperties 區段內的 Format 區段中指定任何屬性。 範例:
"format":
{
"type": "ParquetFormat"
}
請注意下列幾點:
- 不支援複雜資料類型 (MAP、LIST)。
- 不支援資料行名稱中的空白字元。
- Parquet 檔案已有下列壓縮相關選項:NONE、SNAPPY、GZIP 和 LZO。 服務會支援以這其中任一種壓縮格式從 Parquet 檔案中讀取資料,但 LZO 除外,此項目會在中繼資料內使用壓縮轉碼器來讀取資料。 不過,寫入 Parquet 檔案時,服務會選擇 SNAPPY,這是 Parquet 格式的預設值。 目前沒有任何選項可覆寫這個行為。
重要
針對由自我裝載 Integration Runtime 所授權的複製 (例如,在內部部署與雲端資料存放區之間),如果您不會依原樣複製 Parquet 檔案,就需要在 IR 機器上安裝 64 位元的 JRE 8 (Java Runtime Environment) 或 OpenJDK。 如需更多詳細資料,請參閱接下來的段落。
針對在自我裝載 IR 上搭配 Parquet 檔案序列化/還原序列化來執行的複製,服務會找出 JAVA 執行階段,方法是先檢查登錄 (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome)是否有 JRE,如果找不到,就接著檢查系統變數JAVA_HOME是否有 OpenJDK。
- 若要使用 JRE:64 位元 IR 需要 64 位元 JRE。 您可以從這裡找到該程式。
- 使用 OpenJDK:自 IR 3.13 版開始便可支援。 請將 jvm.dll 與所有其他必要的 OpenJDK 組件一起封裝至自我裝載 IR 機器,然後相應地設定 JAVA_HOME 系統環境變數。
提示
如果您使用自我裝載 Integration Runtime 將資料複製到 Parquet 格式 (或從該格式複製資料),而且遇到錯誤顯示 [叫用 Java 時發生錯誤。訊息: java.lang.OutOfMemoryError:Java heap space],您可以在裝載自我裝載 IR 的機器中新增環境變數 _JAVA_OPTIONS,以調整 JVM 的堆積大小下限/上限,使系統能執行這樣的複製,然後重新執行管線。
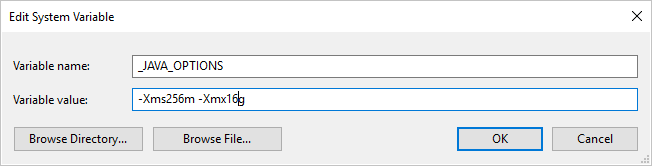
範例:將變數 _JAVA_OPTIONS 的值設定為 -Xms256m -Xmx16g。 旗標 Xms 指定 JAVA 虛擬機器 (JVM) 的初始記憶體配置集區,而 Xmx 指定記憶體配置集區的最大值。 這表示 JVM 啟動時有 Xms 數量的記憶體,且最多可以使用 Xmx 數量的記憶體。 根據預設,服務會使用最小 64MB 和最大 1G。
Parquet 檔案的資料類型對應
| 過渡期服務資料類型 | Parquet 基本類型 | Parquet 原始類型 (還原序列化) | Parquet 原始類型 (序列化) |
|---|---|---|---|
| Boolean | Boolean | N/A | N/A |
| SByte | Int32 | Int8 | Int8 |
| Byte | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Int64/二進位 | UInt64 | Decimal |
| Single | Float | N/A | N/A |
| Double | Double | N/A | N/A |
| Decimal | 二進位 | Decimal | Decimal |
| String | 二進位 | Utf8 | Utf8 |
| Datetime | Int96 | N/A | N/A |
| TimeSpan | Int96 | N/A | N/A |
| DateTimeOffset | Int96 | N/A | N/A |
| ByteArray | 二進位 | N/A | N/A |
| GUID | 二進位 | Utf8 | Utf8 |
| Char | 二進位 | Utf8 | Utf8 |
| CharArray | 不支援 | N/A | N/A |
ORC 格式 (舊版)
注意
透過 ORC 格式文章了解新的模型。 檔案型數據存放區數據集上的下列組態仍受支援,以符合回溯相容性。 建議您未來使用新的模型。
如果您想要剖析 ORC 檔案,或以 ORC 格式寫入資料,請將 formattype 屬性設定為 OrcFormat。 您不需要在 typeProperties 區段內的 Format 區段中指定任何屬性。 範例:
"format":
{
"type": "OrcFormat"
}
請注意下列幾點:
- 不支援複雜資料類型 (STRUCT、MAP、LIST、UNION)。
- 不支援資料行名稱中的空白字元。
- ORC 檔案有 3 種 壓縮相關選項︰NONE、ZLIB、SNAPPY。 服務支援以這些壓縮格式的任一項從 ORC 檔案讀取資料。 它會使用中繼資料裡的壓縮轉碼器來讀取資料。 不過,寫入 ORC 檔案時,服務會選擇 ZLIB,這是 ORC 的預設值。 目前沒有任何選項可覆寫這個行為。
重要
針對由自我裝載 Integration Runtime 所授權的複製 (例如,在內部部署與雲端資料存放區之間),如果您不會依原樣複製 ORC 檔案,就需要在 IR 機器上安裝 64 位元的 JRE 8 (Java Runtime Environment) 或 OpenJDK。 如需更多詳細資料,請參閱接下來的段落。
針對在自我裝載 IR 上搭配 ORC 檔案序列化/還原序列化來執行的複製,服務會找出 JAVA 執行階段,方法是先檢查登錄 (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome)是否有 JRE,如果找不到,就接著檢查系統變數JAVA_HOME是否有 OpenJDK。
- 若要使用 JRE:64 位元 IR 需要 64 位元 JRE。 您可以從這裡找到該程式。
- 使用 OpenJDK:自 IR 3.13 版開始便可支援。 請將 jvm.dll 與所有其他必要的 OpenJDK 組件一起封裝至自我裝載 IR 機器,然後相應地設定 JAVA_HOME 系統環境變數。
ORC 檔案的資料類型對應
| 過渡期服務資料類型 | ORC 類型 |
|---|---|
| Boolean | Boolean |
| SByte | Byte |
| Byte | Short |
| Int16 | Short |
| UInt16 | int |
| Int32 | int |
| UInt32 | Long |
| Int64 | Long |
| UInt64 | String |
| Single | Float |
| Double | Double |
| Decimal | Decimal |
| String | String |
| Datetime | 時間戳記 |
| DateTimeOffset | 時間戳記 |
| TimeSpan | 時間戳記 |
| ByteArray | 二進位 |
| GUID | String |
| Char | Char(1) |
AVRO 格式 (舊版)
注意
透過 Avro 格式文章了解新的模型。 檔案型數據存放區數據集上的下列組態仍受支援,以符合回溯相容性。 建議您未來使用新的模型。
如果您想要剖析 Avro 檔案,或以 Avro 格式寫入資料,請將 formattype 屬性設定為 AvroFormat。 您不需要在 typeProperties 區段內的 Format 區段中指定任何屬性。 範例:
"format":
{
"type": "AvroFormat",
}
若要在 Hive 資料表中使用 Avro 格式,您可以參考 Apache Hive 的教學課程。
請注意下列幾點:
- 不支援複雜資料類型 (記錄、列舉、陣列、對應、等位和固定)。
壓縮支援 (舊版)
服務支援在複製期間壓縮/解壓縮資料。 當您在輸入資料集中指定 compression 屬性時,複製活動可以從來源讀取壓縮的資料並且解壓縮,當您在輸出資料集中指定屬性時,複製活動可以將資料壓縮然後寫入到接收。 以下是一些範例案例:
- 從 Azure blob 讀取 GZIP 壓縮資料,將其解壓縮,並將結果資料寫入到 Azure SQL Database。 您可以利用設為 GZIP 的
compressiontype屬性,定義輸入 Azure Blob 資料集。 - 從來自內部部署檔案系統之純文字檔案讀取資料、使用 GZip 格式加以壓縮並將壓縮的資料寫入到 Azure blob。 您可以利用設為 GZip 的
compressiontype屬性,定義輸出 Azure Blob 資料集。 - 從 FTP 伺服器讀取.zip 檔、將它解壓縮以取得其中的檔案,並將這些檔案放入 Azure Data Lake Store。 您可以利用設為 ZipDeflate 的
compressiontype屬性,定義輸入 FTP 資料集。 - 從 Azure blob 讀取 GZIP 壓縮資料,將其解壓縮、使用 BZIP2 將其壓縮,並將結果資料寫入到 Azure blob。 您會利用設為 GZIP 的
compressiontype定義輸入 Azure Blob 資料集,並利用設為 BZIP2 的compressiontype定義輸出資料集。
若要指定資料集的壓縮,請使用資料集 JSON 中的 壓縮 屬性,如下列範例所示:
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
[壓縮] 區段有兩個屬性:
類型:壓縮轉碼器,可以是 GZIP、Deflate、BZIP2 或 ZipDeflate。 請注意,透過複製活動來解壓縮 ZipDeflate 檔案並將其寫入檔案型接收資料存放區時,檔案會解壓縮至資料夾:
<path specified in dataset>/<folder named as source zip file>/。層級:壓縮比,它可以是最佳或最快。
最快: 即使未以最佳方式壓縮所產生的檔案,壓縮作業也應儘速完成。
Optimal:即使作業需要較長時間完成,壓縮作業也應以最佳方式壓縮。
如需詳細資訊,請參閱 壓縮層級 主題。
注意
不支援 AvroFormat、OrcFormat 或 ParquetFormat 的資料壓縮設定。 讀取這些格式的檔案時,服務會偵測並使用中繼資料中的壓縮轉碼器。 寫入這些格式的檔案時,服務會選擇該格式的預設壓縮轉碼器。 例如,ZLIB for OrcFormat 和 SNAPPY for ParquetFormat。
不支援的檔案類型和壓縮格式
您可以使用擴充性功能來轉換不支援的檔案。 兩個選項包括使用 Azure Batch 的 Azure Functions 和自訂工作。
您可以看到使用 Azure 函式來擷取 tar 檔案內容的範例。 如需詳細資訊,請參閱 Azure Functions 活動。
您也可以使用自訂 dotnet 活動來組建此功能。 可在此處取得詳細資訊
相關內容
透過支援檔案格式和壓縮文章了解最新支援的檔案格式和壓縮。