對應資料流中的選取轉換
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用 (部分機器翻譯)!
Azure Data Factory 和 Azure Synapse Pipelines 中均可使用資料流。 本文適用於對應資料流。 如果您不熟悉轉換作業,請參閱簡介文章:使用對應資料流轉換資料。
使用選取轉換來重新命名、卸載或重新排序資料行。 此轉換不會改變資料列資料,但會選擇要將哪些資料行傳播到下游。
在選取轉換中,使用者可以指定固定對應、使用模式來執行規則型對應,或啟用自動對應。 固定和規則型對應都可在相同的選取轉換內使用。 如果資料行不符合其中一個定義的對應,即會加以卸除。
固定對應
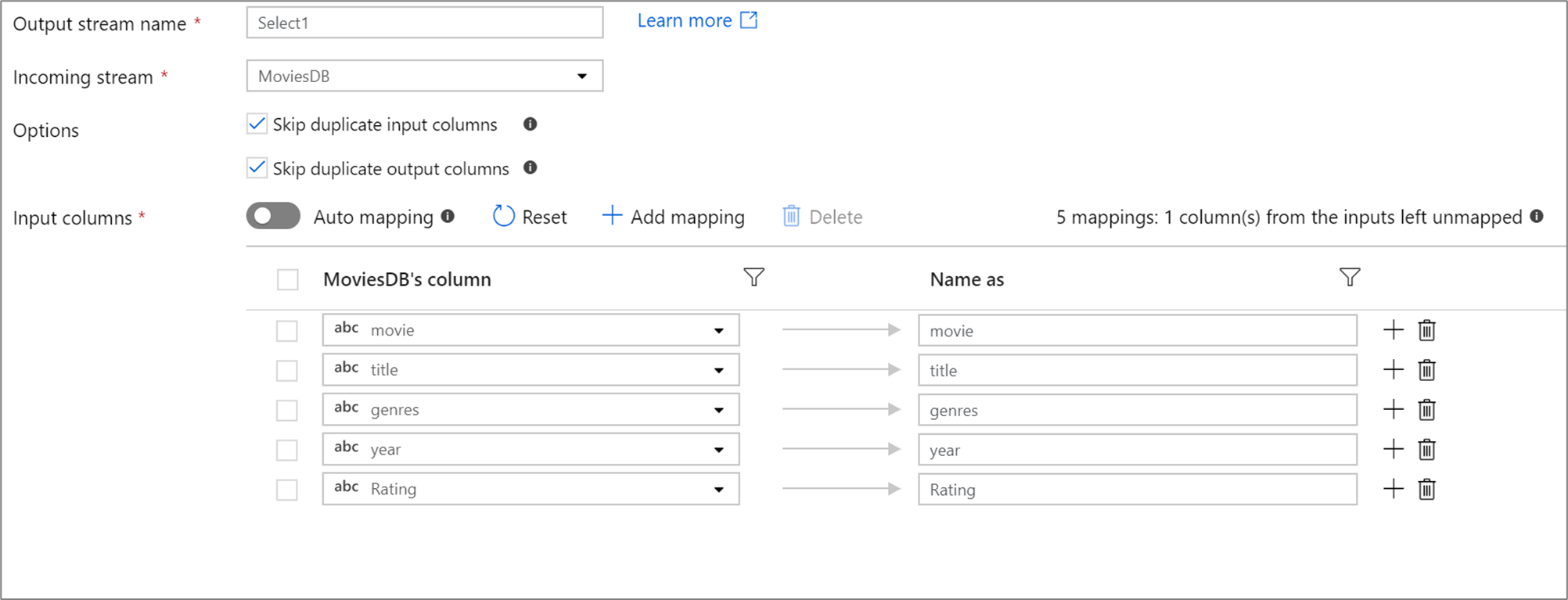
如果投影中定義的資料行少於 50 個,所有定義的資料行預設都將有固定對應。 固定對應會採用定義的傳入資料行,並將其對應到確切名稱。
注意
您無法使用固定對應來對應或重新命名漂移資料行
對應階層式資料行
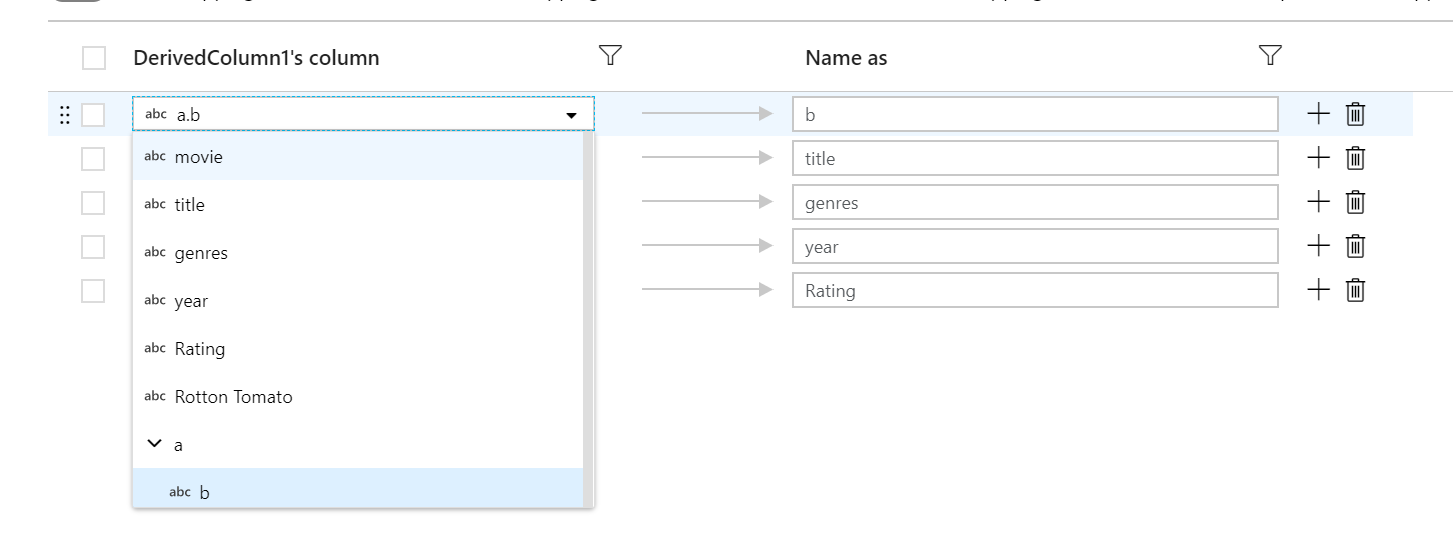
固定對應可用來將階層式資料行的子資料行對應至最上層資料行。 如果您有定義的階層,請使用資料行下拉式清單來選取子資料行。 選取轉換將使用子資料行的值和資料類型來建立新資料行。
規則型對應
如果您想要一次對應許多資料行或將漂移資料行傳遞到下游,請使用規則型對應以使用資料行模式來定義對應。 根據資料行的 name、type、stream 及 position 進行比對。 您可以擁有固定和規則型對應的任意組合。 根據預設,所有大於 50 個資料行的投影都將預設為規則型對應,在每個資料行上進行比對並輸出輸入的名稱。
若要新增規則型對應,請按一下 [新增對應],然後選取 [規則型對應]。
![此螢幕快照顯示從 [新增對應] 選取的規則型對應。](media/data-flow/rule2.png)
每個規則型對應都需要兩個輸入:要比對的條件,以及每個對應資料行的名稱。 這兩個值都是透過運算式產生器輸入。 在左側運算式方塊中,輸入布林比對條件。 在右運算式方塊中,指定相符資料行將對應至哪些項目。

使用 $$ 語法來參考相符資料行的輸入名稱。 以上圖為例,假設使用者想要比對名稱少於六個字元的所有字串資料行。 如果有一個傳入資料行的名稱為 test,運算式 $$ + '_short' 會將該資料行重新命名為 test_short。 如果這是唯一存在的對應,則不符合條件的所有資料行都將從輸出的資料中卸除。
模式會比對漂移和已定義的資料行。 若要查看規則所對應的定義資料行,請按一下規則旁的眼鏡圖示。 使用資料預覽來確認輸出。
Regex 對應
如果您按一下向下>形箭號圖示,您可以指定 RegEx 對應條件。 RegEx 對應條件會比對所有符合指定 RegEx 條件的資料行名稱。 這可以與標準規則型對應合併使用。

上述範例會比對 RegEx 模式 (r) 或任何包含小寫 r 的資料行名稱。 與標準規則型對應類似,所有相符的資料行都會根據右側的條件使用 $$ 語法加以改變。
如果您在資料行名稱中有多個 RegEx 相符項目,您可以使用 $n 來參考特定相符項目,其中 'n' 指出哪一個相符項目。 例如,'$2' 指出資料行名稱內的第二個相符項目。
規則型階層
如果您定義的投影具有階層,您可以使用規則型對應來對應階層子資料行。 指定要對應之子資料行的比對條件和複雜資料行。 每個相符的子資料行都會使用右側指定的 'Name as' 規則來輸出。
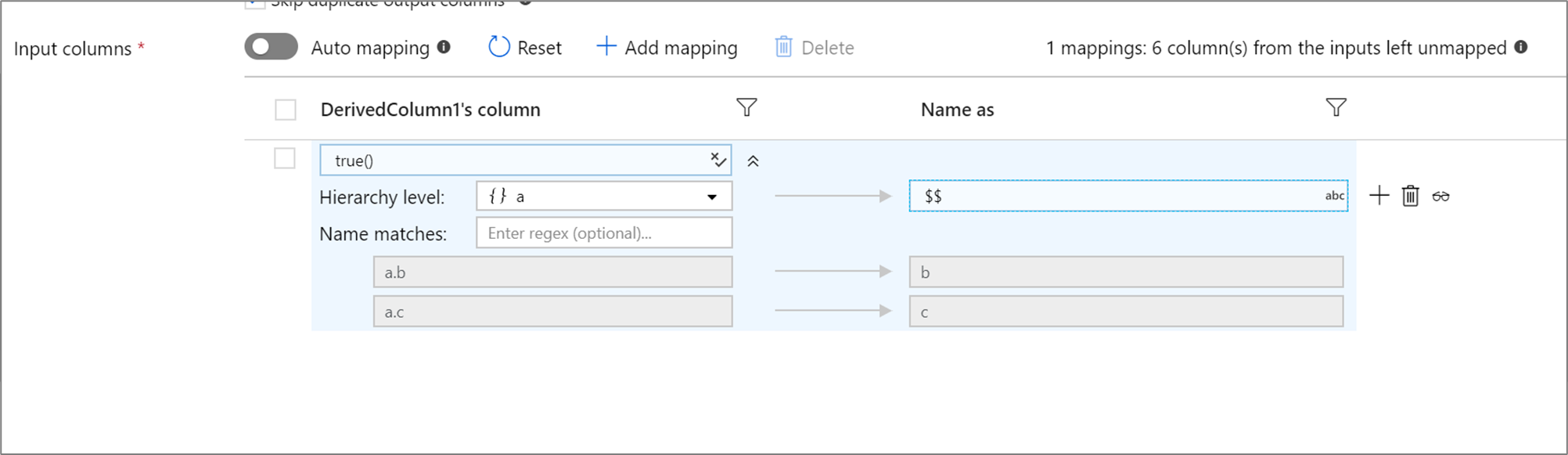
上述範例會比對複雜資料行 a 的所有子資料行。 a 包含兩個子資料行 b 和 c。 由於 'Name as' 條件是 $$,所以輸出結構描述將包括兩個資料行 b 和 c。
參數化
您可以使用規則型對應來將資料行名稱參數化。 使用 name 關鍵字來比對傳入的資料行名稱與參數。 例如,如果您有資料流程參數 mycolumn,您可以建立規則來比對任何等於 mycolumn 的資料行名稱。 您可以將相符的資料行重新命名為硬式編碼字串 (例如 'business key'),並明確加以參考。 在此範例中,比對條件為 name == $mycolumn,而名稱條件為 'business key'。
自動對應
新增選取轉換時,可透過切換 [自動對應] 滑桿來啟用自動對應。 透過自動對應,選取轉換會對應所有傳入資料行,但不包括名稱與其輸入相同的重複項目。 這將包括漂移資料行,其表示輸出資料可能包含結構描述中未定義的資料行。 如需漂移資料行的詳細資訊,請參閱結構描述漂移。
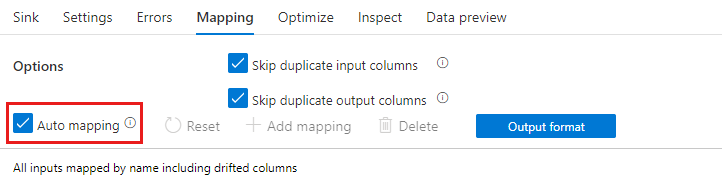
透過自動對應,選取轉換將接受略過重複項目設定,並為現有的資料行提供新別名。 在相同資料流上和自我聯結案例中執行多個聯結或查閱時,別名非常有用。
重複的資料行
根據預設,選取轉換會在輸入和輸出投影中卸除重複的資料行。 重複的輸入資料行通常來自聯結和查閱轉換,其中資料行名稱會在聯結的兩側重複。 如果您將兩個不同的輸入資料行對應至相同名稱,可能會發生重複的輸出資料行。 透過切換核取方塊,選擇要卸除或傳遞重複的資料行。
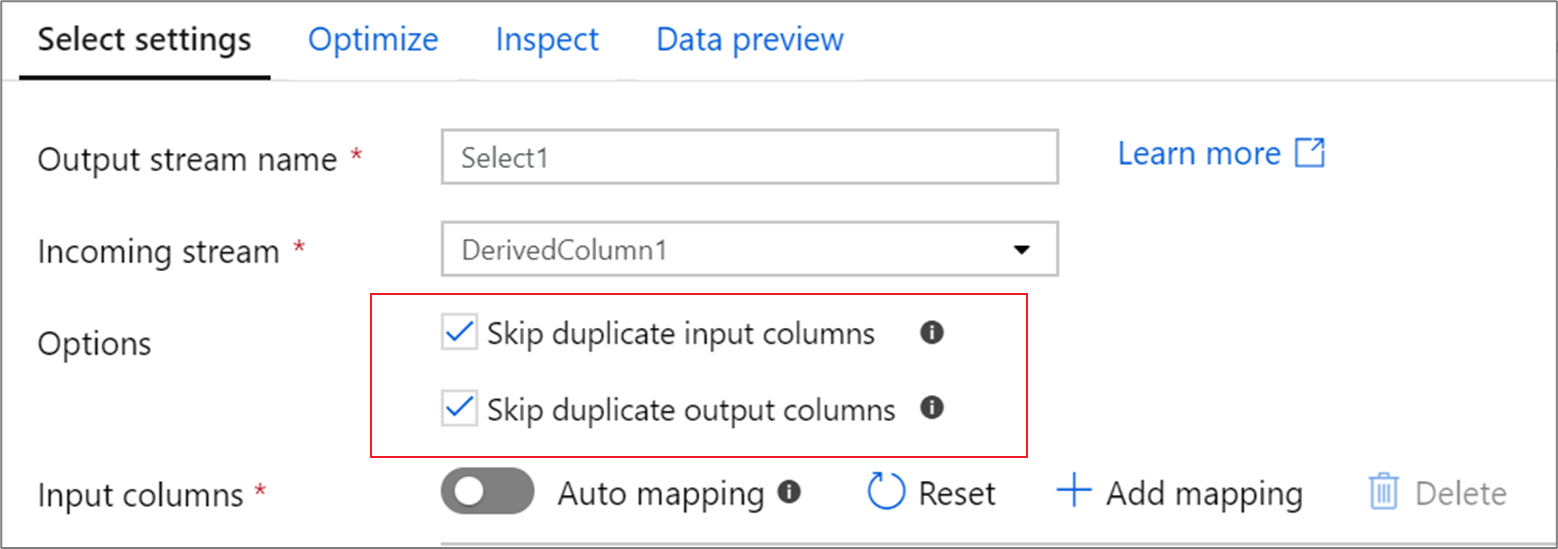
資料行的順序
對應的順序會決定輸出資料行的順序。 如果多次對應某個輸入資料行,將只會接受第一個對應。 針對任何重複的資料行卸除,將保留第一個相符項目。
資料流程指令碼
語法
<incomingStream>
select(mapColumn(
each(<hierarchicalColumn>, match(<matchCondition>), <nameCondition> = $$), ## hierarchical rule-based matching
<fixedColumn>, ## fixed mapping, no rename
<renamedFixedColumn> = <fixedColumn>, ## fixed mapping, rename
each(match(<matchCondition>), <nameCondition> = $$), ## rule-based mapping
each(patternMatch(<regexMatching>), <nameCondition> = $$) ## regex mapping
),
skipDuplicateMapInputs: { true | false },
skipDuplicateMapOutputs: { true | false }) ~> <selectTransformationName>
範例
以下是選取對應及其資料流程指令碼的範例:
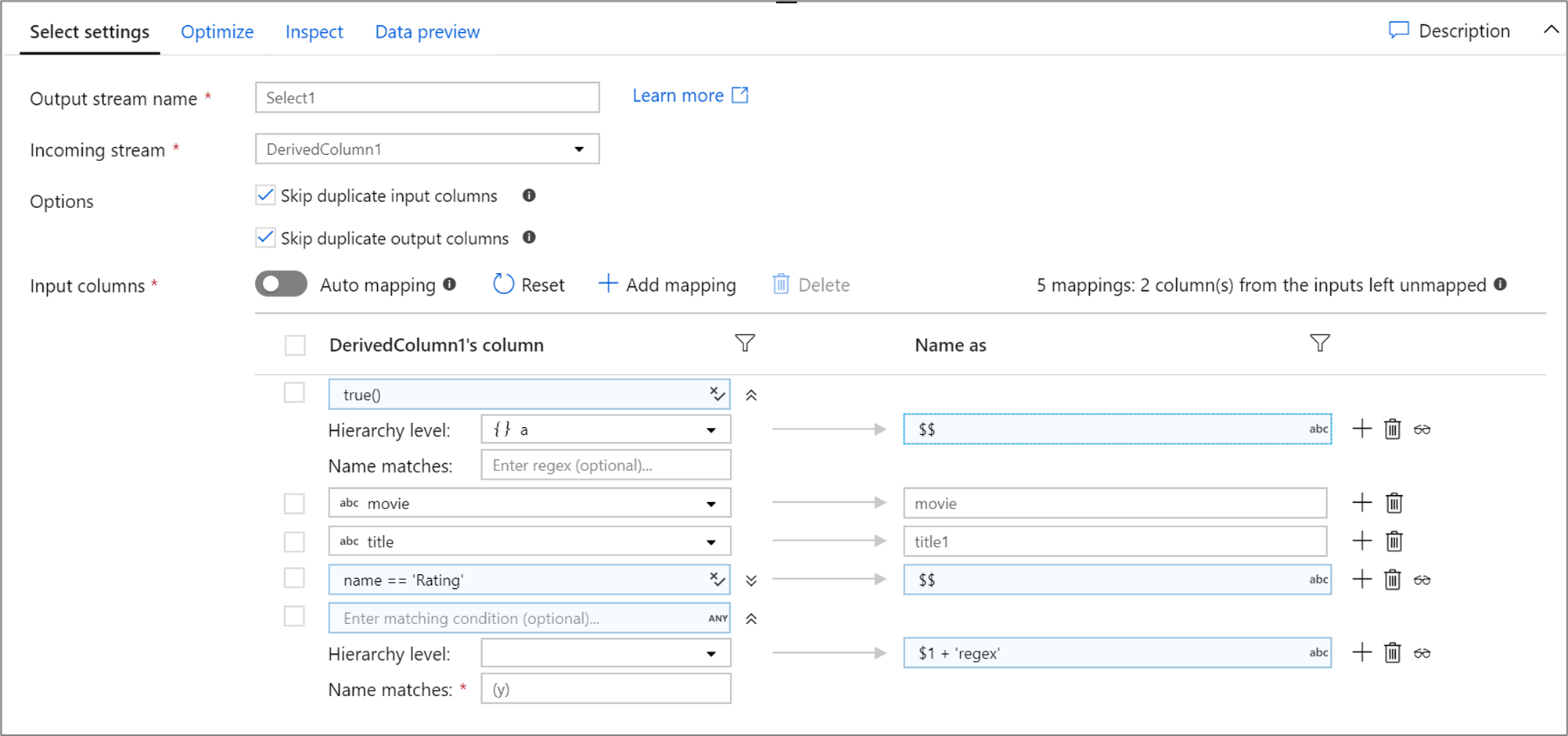
DerivedColumn1 select(mapColumn(
each(a, match(true())),
movie,
title1 = title,
each(match(name == 'Rating')),
each(patternMatch(`(y)`),
$1 + 'regex' = $$)
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
相關內容
- 使用 [選取] 將資料行重新命名、重新排序及設定別名之後,請使用接收轉換來將資料登陸至資料存放區。