使用自定义视觉训练模型
在本教程的前一阶段中,我们讨论了创建你自己的 Windows 机器学习模型和应用的先决条件,并下载了要使用的图像集。 在此阶段,我们将了解如何使用基于 Web 自定义视觉界面将图像集转换为图像分类模型。
Azure 自定义视觉是一种图像识别服务,可用于构建、部署和改进你自己的图像标识符。 自定义视觉服务以一组原生 SDK 的形式提供,另外也在自定义视觉网站的基于 Web 的界面上提供。
创建自定义视觉资源和项目
创建自定义视觉资源
若要使用自定义视觉服务,需要在 Azure 中创建自定义视觉资源。
- 导航到 Azure 帐户的主页,然后选择
Create a resource。
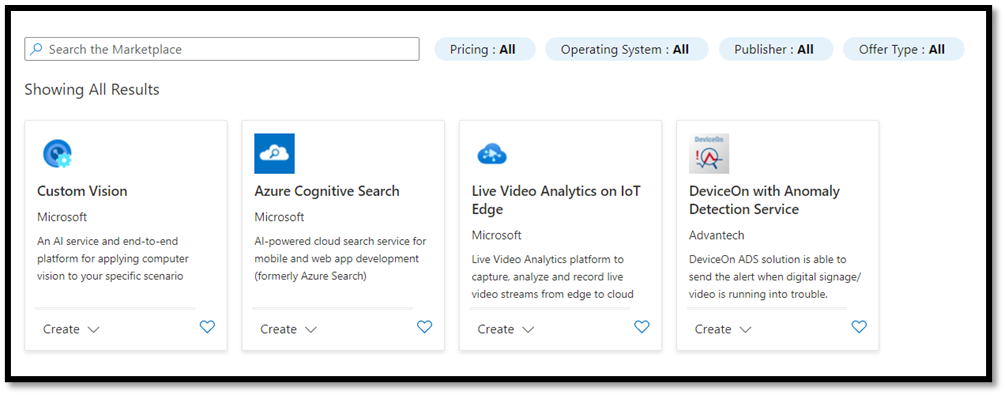
- 在搜索框中,搜索
Custom Vision,随即进入 Azure 市场。 选择Create Custom Vision以在“创建自定义视觉”页面上打开对话窗口。
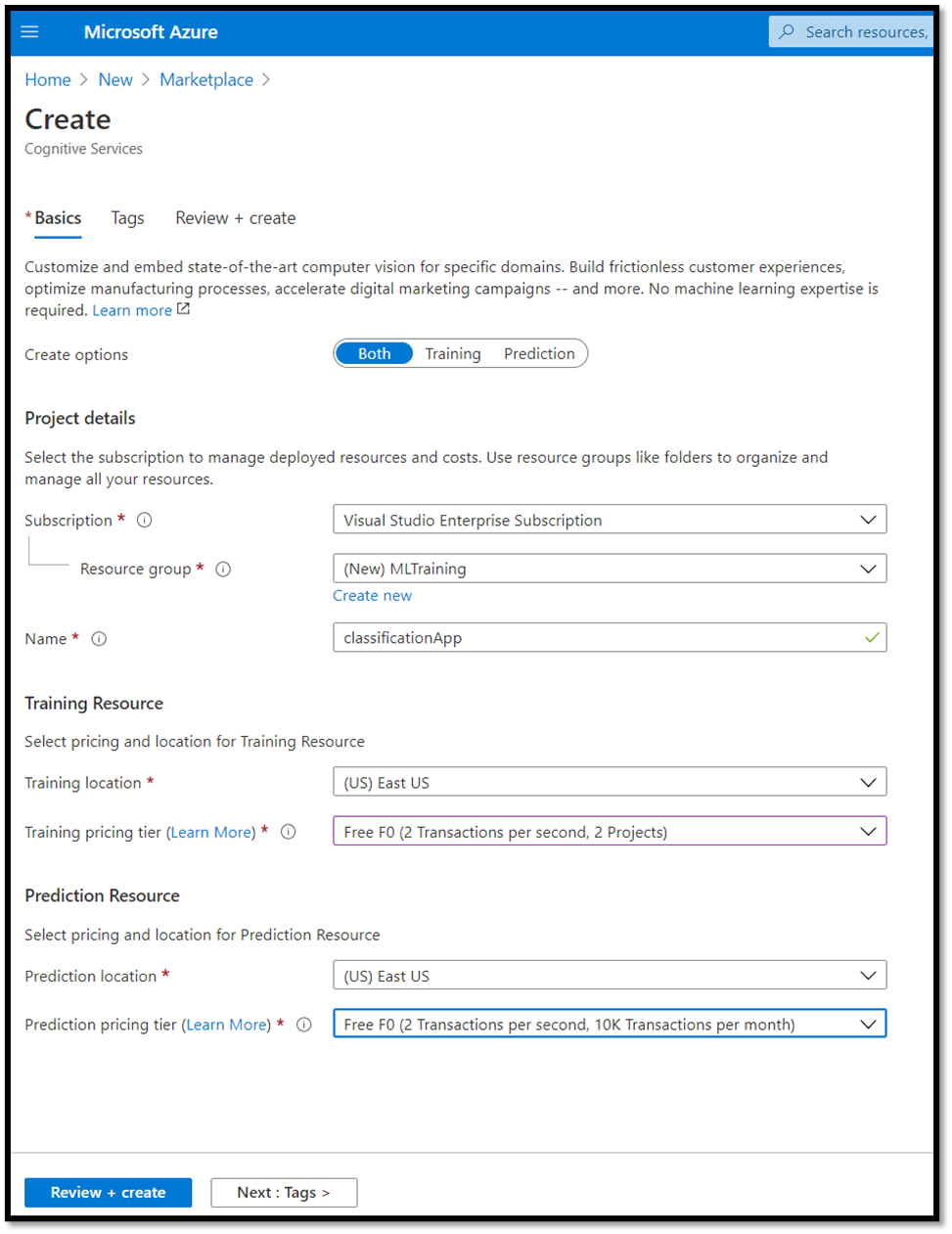
- 在自定义视觉对话框页面上,选择以下选项:
- 同时选择
Training和Prediction资源。 - 选择用于管理已部署资源的订阅。 如果在菜单中未看到 Azure 订阅,请注销并使用打开帐户时使用的相同凭据重新打开 Azure 帐户。
- 创建新的资源组,并为其指定名称。 在本教程中,我们将其命名为
MLTraining,但你可以随意选择自己的名称或使用现有资源组(如果有)。 - 为项目提供名称。 在本教程中,我们将其命名为
classificationApp,但你可以自行选择任何名称。 - 对于
Training和Prediction资源,将位置设置为“(美国)美国东部”,并将“定价层”设置为“免费 FO”。
- 按
Review + create以部署自定义视觉资源。 可能需要几分钟时间才能完成资源部署。
使用自定义视觉创建新项目
现在,你已经创建了资源,接下来便可以在自定义视觉内创建训练项目。
在 Web 浏览器中,导航到自定义视觉页面,然后选择
Sign in。 使用用于登录 Azure 门户的帐户登录。选择
New Project以打开新项目对话框。
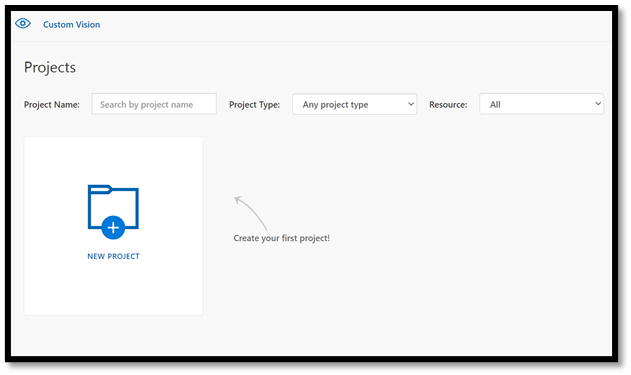
- 按如下步骤创建新项目:
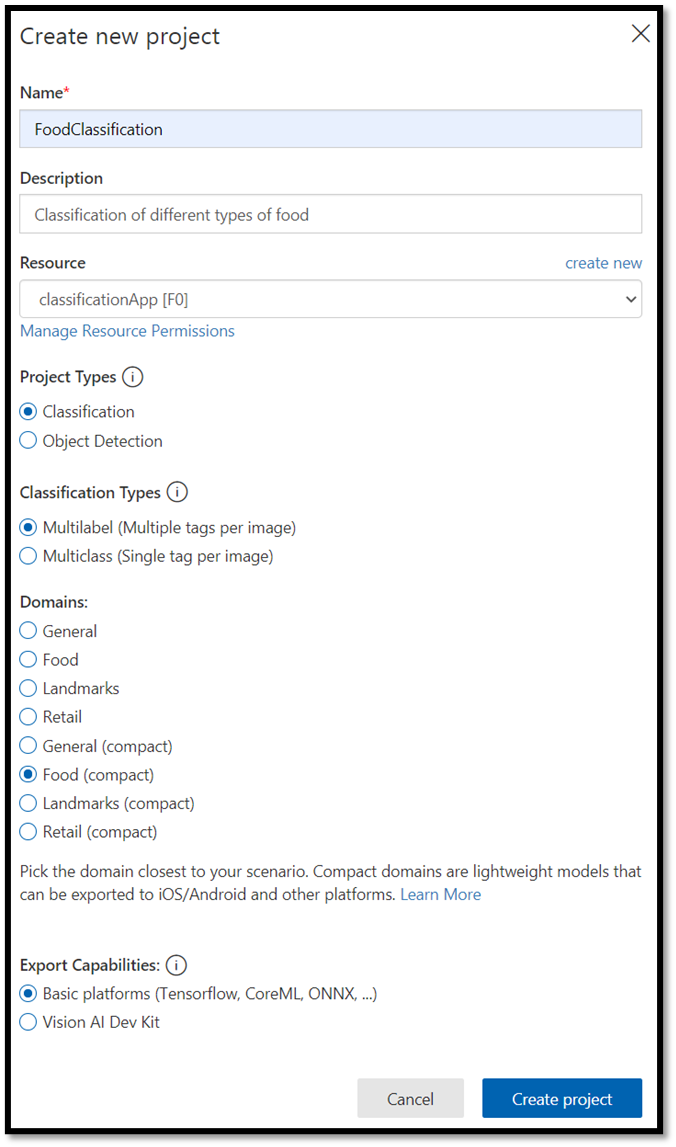
Name:FoodClassification。Description:对不同类型食物的分类。Resource:保留之前打开的相同资源ClassificationApp [F0]。Project Types:classificationClassification Types:Multilabel (Multiple tags per image)Domains:Food (compact)。Export Capabilities:Basic platforms (Tensorflow, CoreML, ONNX, ...)
注意
若要导出为 ONNX 格式,请确保选择 Food (compact) 域。 无法将非紧域导出为 ONNX。
重要
如果登录帐户与 Azure 帐户相关联,则“资源组”下拉列表将显示包含自定义影像服务资源的所有 Azure 资源组。 如果没有可用的资源组,请确认已使用登录 Azure 门户时所用的同一帐户登录 customvision.ai。
- 填充对话框后,选择
Create project。
上传训练数据集
现在你已经创建了项目,接下来你将从 Kaggle 开放数据集上传一个之前准备好的食物图像数据集。
选择
FoodClassification项目以打开自定义视觉网站的基于 Web 的界面。选择
Add images按钮并选择Browse local files。
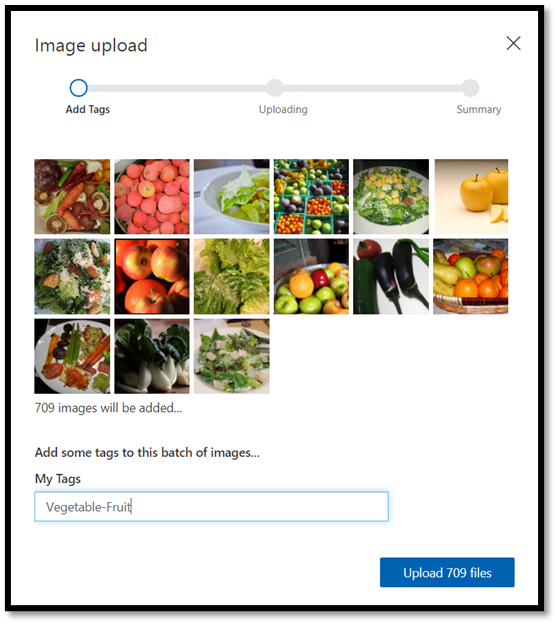
导航到图像数据集的位置,然后选择训练文件夹
vegetable-fruit。 选择文件夹中的所有图像,然后选择open。 标记选项随即打开。在
My Tags字段中输入vegetable-fruit,并按Upload。
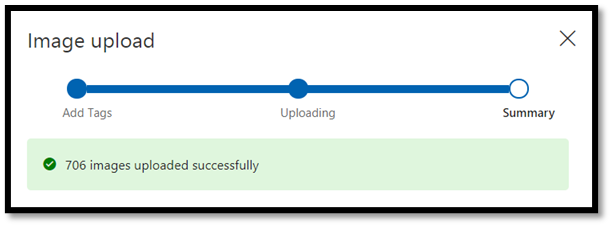
等待第一组图像上传到项目,然后按 done。 标记选择将应用于已选择上传的整组图像。 正因如此,从预构建的图像组上传图像会更容易。 始终可在上传图像后更改单个图像的标记。
- 在第一组图像上传成功后,再重复这一过程两次,上传甜点和汤的图像。 请确保你给它们贴上了相关的标记。
最后,你将有三组不同的图像可供训练。

训练模型分类器
现在,你将训练模型,以从你在上一部分下载的图像集中对蔬菜、汤和甜点进行分类。
- 若要启动训练过程,请选择右上角的
Train按钮。 分类器将使用这些图像创建一个模型,用于标识每个标记的视觉质量。

使用左上角的滑块可以更改概率阈值。 概率阈值设置了预测被视为正确所需的置信度水平。 如果概率阈值过高,分类将更准确,与此同时数量更少。 另一方面,如果概率阈值过低,你将检测到更多分类,但置信度更低或误报结果更多。
在本教程中,可以将概率阈值保持在 50%。
- 此处我们将使用
Quick Training过程。Advanced Training具有更多设置,并允许你专门设置用于训练的时间,但此处并不需要这种级别的控制。 按Train启动训练过程。

快速训练过程只需几分钟即可完成。 在此期间,有关训练过程的信息将显示在 Performance 选项卡中。
评估和测试
评估结果
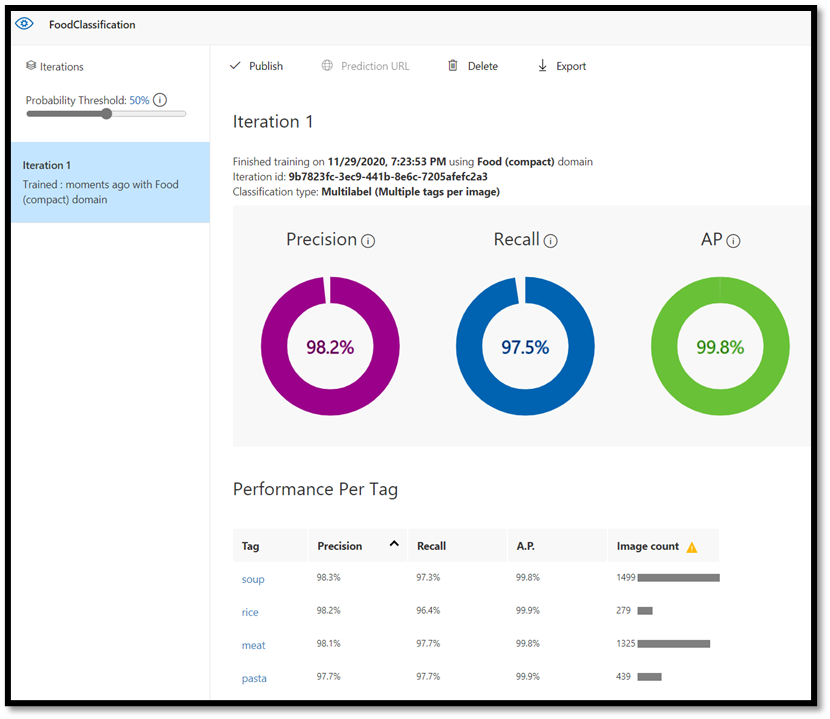
训练完成后,你将看到第一次训练迭代的摘要。 其中包括模型性能的估计 - 查准率和查全率。
- 精确度表示已识别的正确分类的分数。 在我们的模型中,查准率为 98.2%,所以如果模型对一个图像进行分类,极有可能正确预测该图像。
- 召回率表示正确识别的实际分类的分数。 在我们的模型中,查全率为 97.5%,因此模型对呈现给它的绝大多数图像进行了正确分类。
- AP 代表附加性能。 这提供了一个额外的指标,它总结了不同阈值下的查准率和查全率。
测试模型
导出模型之前,可以测试其性能。
- 选择顶部菜单栏右上角的
Quick Test,打开一个新的测试窗口。

在此窗口中,你可以提供要测试的图像的 URL,或选择 Browse local files 以使用本地存储的图像。
- 选择
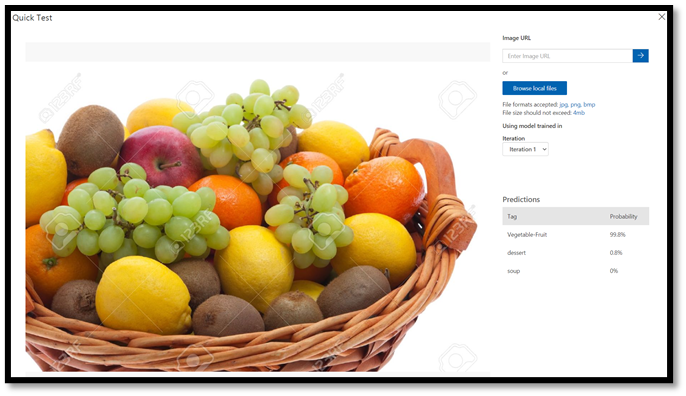
Browse local files,导航到食物数据集,然后打开验证文件夹。 从fruit-vegetable文件夹中选择任意随机图像,然后按open。
测试结果将显示在屏幕上。 在我们的测试中,该模式以 99.8% 的确定性成功地对图像进行了分类。
可以在 Predictions 选项卡中使用预测进行训练,这可以提高模型性能。 有关详细信息,请参阅如何改进分类器。
注意
想要详细了解 Azure 自定义视觉 API? 请查看自定义视觉服务文档,其中提供了有关自定义视觉 Web 门户和 SDK 的详细信息。
将模型导出为 ONNX
现在,我们已经训练了模型,接下来便可以将其导出为 ONNX。
- 选择
Performance选项卡,然后选择Export以打开导出窗口。

- 选择
ONNX以将模型导出为 ONNX 格式。

- 如果需要,可以选择
ONNX 16float 选项,但在本教程中,我们不需要更改任何设置。 选择Export and Download。
- 打开下载的 .zip 文件,并从中提取
model.onnx文件。 此文件包含你的分类器模型。
祝贺你! 你已成功构建并导出分类模型。
后续步骤
现在我们已经有了一个分类模型,下一步是构建一个 Windows 应用程序并在 Windows 设备的本地运行该应用程序。