Windows 显示驱动程序模型 (WDDM) 操作流
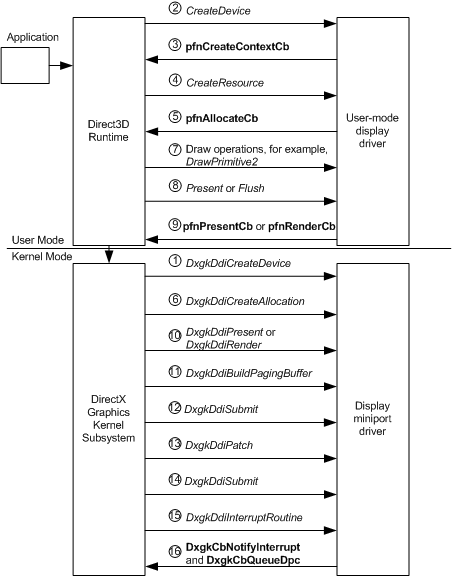
下图显示了从创建呈现设备到显示内容时发生的 WDDM 操作流。 下图后面的信息更详细地描述了操作流的有序顺序。
创建渲染设备
应用程序请求创建呈现设备后:
1:DirectX 图形内核子系统 (Dxgkrnl) 调用内核模式显示微型端口驱动程序的 (KMD) DxgkDdiCreateDevice 函数。
KMD 通过返回指向DXGKARG_CREATEDEVICE结构的 pInfo 成员中填充DXGK_DEVICEINFO结构的指针来初始化直接内存访问(DMA)。
2:如果对 DxgkDdiCreateDevice 的调用成功,Direct3D 运行时将调用用户模式显示驱动程序 (UMD) CreateDevice 函数。
3:在 CreateDevice 调用中,UMD 必须显式调用运行时的 pfnCreateContextCb 函数来创建一个或多个 GPU 上下文,这些上下文是新创建的设备上的 GPU 执行线程。 运行时将信息返回到 pCommandBuffer 和 CommandBufferSize D3DDDICB_CREATECONTEXT 结构中的 UMD,以初始化命令缓冲区。
为设备创建 Surface
应用程序请求为呈现设备创建图面后:
4:Direct3D 运行时调用 UMD 的 CreateResource 函数。
5:CreateResource 调用运行时提供的 pfnAllocateCb 函数。
6:运行时调用 KMD 的 DxgkDdiCreateAllocation 函数,指定要创建的分配的数量和类型。 DxgkDdiCreateAllocation 返回有关DXGKARG_CREATEALLOCATION结构的 pAllocationInfo 成员中DXGK_ALLOCATIONINFO结构数组中分配的信息。
将命令缓冲区提交到内核模式
在应用程序请求绘制到图面之后:
7:Direct3D 运行时调用与绘图操作相关的 UMD 函数, 例如 DrawPrimitive2。
8:Direct3D 运行时调用 UMD 的 Present 或 Flush 函数,使命令缓冲区提交到内核模式。 注意:UMD 还会在命令缓冲区已满时提交命令缓冲区。
9:响应步骤 8,UMD 调用以下运行时提供的函数之一:
- 如果调用 Present,则运行时的 pfnPresentCb 函数。
- 如果调用 Flush 或命令缓冲区已满,则运行时的 pfnRenderCb 函数。
10:调用 pfnPresentCb 时调用 KMD 的 DxgkDdiPresent 函数;如果调用 pfnRenderCb,则调用 DxgkDdiRender 或 DxgkDdiRenderKm 函数。 KMD 会验证命令缓冲区,以硬件格式写入 DMA 缓冲区,并生成描述所用图面的分配列表。
将 DMA 缓冲区提交到硬件
11:Dxgkrnl 调用 KMD 的 DxgkDdiBuildPagingBuffer 函数,以创建专用 DMA 缓冲区,用于将分配列表中指定的分配移入和移出 GPU 可访问内存。 这些特殊的 DMA 缓冲区称为分页缓冲区。 不为每个帧调用 DxgkDdiBuildPagingBuffer 。
12:Dxgkrnl 调用 KMD 的 DxgkDdiSubmitCommand 函数,将分页缓冲区排队到 GPU 执行单元。
13:Dxgkrnl 调用 KMD 的 DxgkDdiPatch 函数,以将物理地址分配给 DMA 缓冲区中的资源。
14:Dxgkrnl 调用 KMD 的 DxgkDdiSubmitCommand 函数,将 DMA 缓冲区排队到 GPU 执行单元。 提交到 GPU 的每个 DMA 缓冲区都包含一个围栏标识符,该标识符是一个数字。 GPU 处理完 DMA 缓冲区后,GPU 将生成中断。
15:KMD 在其 DxgkDdiInterruptRoutine 函数中收到中断的通知。 KMD 应从 GPU 读取刚刚完成的 DMA 缓冲区的围栏标识符。
16:KMD 应调用 DxgkCbNotifyInterrupt ,通知 DXGK DMA 缓冲区已完成。 KMD 还应调用 DxgkCbQueueDpc 来排队延迟的过程调用(DPC)。