Microsoft SQL Server 平台上的大数据选项
适用范围:![]() SQL Server 2019 (15.x) 及更高版本
SQL Server 2019 (15.x) 及更高版本
Microsoft SQL Server 2019 Big Clusters 是 SQL Server 平台的加载项,可以部署在 Kubernetes 上运行的 SQL Server、Spark 和 HDFS 容器的可缩放群集。 这些组件并行运行以确保可使用 Transact-SQL 或 Spark 库读取、写入和处理大数据,这样你就可以借助大量非关系大数据轻松合并并分析高价值关系数据。 大数据群集还允许你使用 PolyBase 虚拟化数据,以便可以使用外部表查询来自外部 SQL Server、Oracle、Teradata、MongoDB 和其他数据源的数据。 Microsoft SQL Server 2019 Big Clusters 加载项使用 AlwaysOn 可用性组技术为 SQL Server 主实例和所有数据库提供高可用性。
SQL Server 2019 大数据群集 加载项使用 Kubernetes 平台在本地和云中运行,以进行 Kubernetes 的任何标准部署。 此外,SQL Server 2019 大数据群集 加载项与 Active Directory 集成并包括基于角色的访问控制,以满足企业的安全性和合规性需求。
SQL Server 2019 大数据群集 加载项的停用
2025 年 2 月 28 日,我们将停用 SQL Server 2019 大数据群集。 带软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,并且软件将继续通过在此之前的 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章。
对 SQL Server 中的 PolyBase 支持的更改
与 SQL Server 2019 大数据群集 停用相关的一些功能与横向扩展查询相关。
Microsoft SQL Server 的 PolyBase 横向扩展组功能已停用。 横向扩展组功能已从 SQL Server 2022 (16.x) 的产品中移除。 市场内的 SQL Server 2019、SQL Server 2017 和 SQL Server 2016 版本将继续支持这些功能,直到这些产品的生命周期结束。 PolyBase 数据虚拟化在 SQL Server 中作为纵向扩展功能继续收到完全支持。
Cloudera (CDP) 和 Hortonworks (HDP) Hadoop 外部数据源也将针对 SQL Server 的所有市场内版本停用,并且不包含在 SQL Server 2022 中。 对外部数据源的支持仅限于相关供应商提供的主要支持中的产品版本。 建议你使用 SQL Server 2022 (16.x) 中可用的新对象存储集成。
在 SQL Server 2022 (16.x) 及更高版本中,用户必须将其外部数据源配置为在连接到 Azure 存储时使用新连接器。 下表概述了这些更改:
| 外部数据源 | 源 | 功能 |
|---|---|---|
| Azure Blob 存储 | wasb[s] |
abs |
| ADLS Gen 2 | abfs[s] |
adls |
注意
Azure Blob 存储 (abs) 将需要在数据库范围的凭据中使用 SECRET 的共享访问签名 (SAS)。 在 SQL Server 2019 及更低版本中,wasb[s] 连接器在对 Azure 存储帐户进行身份验证时使用存储帐户密钥和数据库范围的凭据。
了解替换和迁移选项的大数据群集体系结构
若要为大数据存储和处理系统创建替换解决方案,务必了解 SQL Server 2019 大数据群集 提供哪些功能,且其体系结构有助于告知你的选择。 大数据群集的体系结构如下所示:

此体系结构提供以下功能映射:
| 组件 | 优势 |
|---|---|
| Kubernetes | 用于大规模部署和管理基于容器的应用程序的开放源代码业务流程协调程序。 提供一种声明性方法,用于创建和控制具有弹性缩放的整个环境的复原能力、冗余和可移植性。 |
| 大数据群集控制器 | 为群集提供管理和安全性。 它包含控制服务、配置存储和其他群集级服务,例如 Kibana、Grafana 和 Elastic Search。 |
| 计算池 | 为群集提供计算资源。 它包含在 Linux 上的 SQL Server Pod 上运行的节点。 计算池中的 Pod 分为用于特定处理任务的 SQL Compute实例。 此组件还使用 PolyBase 提供数据虚拟化来查询外部数据源,而无需移动或复制数据。 |
| 数据池 | 为群集提供数据持久性。 数据池由一个或多个运行 Linux 上的 SQL Server 的 Pod 组成。 它用于从 SQL 查询或 Spark 作业中提取数据。 |
| 存储池 | 存储池由 Linux 上的 SQL Server、Spark 和 HDFS 组成的存储池 Pod 组成。 大数据群集中的所有存储节点均为 HDFS 群集的成员。 |
| 应用池 | 通过提供用于创建、管理和运行应用程序的界面,允许在大数据群集上部署应用程序。 |
有关这些函数的详细信息,请参阅 SQL Server 大数据群集 简介。
大数据和 SQL Server 的功能替换选项
可以在混合配置中或使用 Microsoft Azure 平台将大数据群集内 SQL Server 提供的操作数据函数替换为本地 SQL Server。 Microsoft Azure 可以选择完全托管的关系数据库、NoSQL 数据库和内存中数据库(跨专有引擎和开源引擎),以满足现代应用开发人员的需求。 基础结构管理(包括可伸缩性、可用性和安全性)是自动的,可节省时间和资金,并在 Azure 托管的数据库通过嵌入式智能提供性能见解、无限制缩放和管理安全威胁来简化作业的同时允许你专注于构建应用程序。 有关详细信息,请参阅 Azure 数据库。
下一个决策点是用于分析的计算和数据存储的位置。 两种体系结构选择是云中部署和混合部署。 大多数分析工作负载可以迁移到 Microsoft Azure 平台。 “基于云”的数据(源自基于云的应用程序)是这些技术的主要候选项,数据移动服务可以安全快速地迁移大规模本地数据。 有关数据移动选项的详细信息,请参阅数据传输解决方案。
Microsoft Azure 具有系统和认证,允许使用各种工具来保护数据和处理数据。 有关这些认证的详细信息,请参阅信任中心。
注意
Microsoft Azure 平台提供了非常高的安全级别、适用于各种行业的多个认证,并支持符合政府要求的数据主权。 Microsoft Azure 还有一个适用于政府工作负载的专用云平台。 安全本身不应是本地系统的主要决策点。 决定在本地保留大数据解决方案之前,应仔细评估由 Microsoft Azure 提供的安全级别。
在“云中体系结构”选项中,所有组件都驻留在 Microsoft Azure 中。 你的责任在于为存储和处理工作负载而创建的数据和代码。 本文将更详细地介绍这些选项。
- 此选项最适用于利用各种组件来存储和处理数据,以及想要专注于数据和处理构造而不是基础结构的情况。
在“混合体系结构”选项中,某些组件保留在本地,而其他组件放置在云提供商中。 这两者之间的连接旨在以最佳方式放置处理数据。
- 如果对本地技术和体系结构进行了大量投资,但希望使用 Microsoft Azure 的产品/服务,或者如果拥有驻留在本地或面向全球受众的处理和应用程序目标,则此选项效果最佳。
有关构建可缩放体系结构的信息,请参阅为大数据构建可缩放的系统。
在云中
带 Synapse 的 Azure SQL
可以使用操作数据的一个或多个 Azure SQL 数据库选项和用于分析工作负载的 Microsoft Azure Synapse 替换 SQL Server 大数据群集的功能。
Microsoft Azure Synapse 是一项企业分析服务,可以使用分布式处理和数据构造缩短在数据仓库和大数据系统中进行见解提取所需的时间。 Azure Synapse 汇集了企业数据仓库中所用的 SQL 技术、用于大数据的 Spark 技术、用于数据集成和 ETL/ELT 的 Pipelines,以及与其他 Azure 服务(如 Power BI、Cosmos DB 和 Azure 机器学习)的深度集成。
有以下需要时,请使用 Microsoft Azure Synapse 代替 SQL Server 2019 大数据群集:
- 同时使用无服务器资源模型和专用资源模型。 若要使性能和成本可预测,可以创建专用 SQL 池,以保留对 SQL 表中存储的数据进行处理的能力。
- 处理计划外或“突发性”的工作负载,访问始终可用的无服务器 SQL 终结点。
- 使用内置的流式处理功能可将数据从云数据源载入到 SQL 表中。
- 通过使用机器学习模型并使用 T-SQL PREDICT 函数对数据进行评分,将 AI 与 SQL 集成。
- 将 ML 模型与 Linux Foundation Delta Lake 支持的 Apache Spark 2.4 的 SparkML 算法和 Azure 机器学习集成配合使用。
- 使用简化的资源模型使你无需担心群集的管理。
- 处理需要 Spark 快速启动并主动自动缩放的数据。
- 使用 .NET for Spark 处理数据,使你能够在 Spark 应用程序中重复利用自己的 C# 专业知识和现有的 .Net 代码。
- 使用 Spark 或 Hive 无缝使用的基于 Data Lake 中文件定义的表。
- 将 SQL 与 Spark 配合使用来直接浏览和分析 Data Lake 中存储的 Parquet、CSV、TSV 和 JSON 文件。
- 在 SQL 与 Spark 数据库之间以可缩放的方式快速加载数据。
- 从 90 多个数据源引入数据。
- 使用数据流活动启用“无代码”ETL。
- 协调笔记本、Spark 作业、存储过程、SQL 脚本等。
- 监视 SQL 与 Spark 中的资源、使用情况和用户。
- 使用基于角色的访问控制来简化对分析资源的访问。
- 编写 SQL 或 Spark 代码,并与企业 CI/CD 过程集成。
Microsoft Azure Synapse 的体系结构如下所示:

有关 Microsoft Azure Synapse 的详细信息,请参阅什么是 Azure Synapse Analytics?
Azure SQL 和 Azure 机器学习
可以使用操作数据的一个或多个 Azure SQL 数据库选项和用于预测工作负载的 Microsoft Azure 机器学习替换 SQL Server 大数据群集的功能。
Azure 机器学习是一项基于云的服务,可用于任何类型的机器学习,涵盖范围从传统 ML 到深度学习、监督式和非监督式学习。 无论你是希望使用 SDK 编写 Python 或 R 代码,还是在工作室中使用无代码/低代码选项,你都可以在 Azure 机器学习工作区中构建、训练和跟踪机器学习和深度学习模型。 使用 Azure 机器学习可以先在本地计算机上开始训练,然后扩展到云中。 此服务还与常用的深度学习和强化学习开放源代码工具(如 PyTorch、TensorFlow、scikit-learn 和 Ray RLlib)进行互操作。
有以下需要时,请使用 Microsoft Azure 机器学习代替 SQL Server 2019 大数据群集:
- 用于机器学习的基于设计器的 Web 环境:拖放模块以生成试验,然后在低代码环境中部署管道。
- Jupyter 笔记本:使用我们的示例笔记本或创建自己的笔记本,以利用适用于 Python 的 SDK 示例进行机器学习。
- R 脚本或笔记本,其中你使用适用于 R 的 SDK 编写自己的代码,或使用设计器中的 R 模块。
- 多模型解决方案加速器是在 Azure 机器学习的基础之上构建而成,可便于你训练、操作和管理成百上千的机器学习模型。
- 用于 Visual Studio Code 的机器学习扩展(预览版)提供了一个功能完备的开发环境,用于构建和管理机器学习项目。
- 机器学习命令行界面 (CLI)(即 Azure 机器学习)包括提供从命令行管理 Azure 机器学习资源的命令的 Azure CLI 扩展。
- 与开源框架集成,这些框架包括 PyTorch、TensorFlow 和 Scikit-learn,以及其他许多用于训练、部署和管理端到端机器学习过程的框架。
- 与 Ray RLlib 互操作的强化学习。
- 使用 MLflow 跟踪指标并部署模型或使用 Kubeflow 生成端到端工作流管道。
Microsoft Azure 机器学习部署的体系结构如下所示:

有关 Microsoft Azure 机器学习的详细信息,请参阅 Azure 机器学习的工作原理。
Databricks 中的 Azure SQL
可以使用操作数据的一个或多个 Azure SQL 数据库选项和用于分析工作负载的 Microsoft Azure Databricks 替换 SQL Server 大数据群集的功能。
Azure Databricks 是一个已针对 Microsoft Azure 云服务平台进行优化的数据分析平台。 Azure Databricks 提供了两种用于开发数据密集型应用程序的环境:Azure Databricks SQL Analytics 和 Azure Databricks 工作区。
Azure Databricks SQL Analytics 为想要针对数据湖运行 SQL 查询、创建多种可视化类型以从不同角度探索查询结果,以及生成和共享仪表板的分析员提供了一个易于使用的平台。
Azure Databricks 工作区提供了一个交互工作区,支持数据工程师、数据科学家和机器学习工程师之间的协作。 使用大数据管道时,原始或结构化的数据将通过 Azure 数据工厂以批的形式引入 Azure,或者通过 Apache Kafka、事件中心或 IoT 中心进行准实时的流式传输。 此数据将驻留在 Data Lake(长久存储)、Azure Blob 存储或 Azure Data Lake Storage 中。 在分析工作流中,使用 Azure Databricks 从多个数据源读取数据,并使用 Spark 将数据转换为突破性见解。
有以下需要时,请使用 Microsoft Azure Databricks 代替 SQL Server 2019 大数据群集:
- 具有 Spark SQL 和数据帧的完全托管的 Spark 群集。
- 流式处理以进行针对分析与交互式应用程序的实时数据处理和分析,与 HDFS、Flume 和 Kafka 集成。
- 访问由常见学习算法和实用工具(包括分类、回归、群集、协作筛选、维数约简以及底层优化基元)组成的 MLlib 库。
- 在以 R、Python、Scala 或 SQL 编写的笔记本中记录进度。
- 几步内即可实现数据可视化,可使用熟悉的工具,例如 Matplotlib、ggplot 或 d3。
- 使用交互式仪表板创建动态报表。
- GraphX,针对从认知分析到数据浏览的广泛范围显示图形和执行图形计算。
- 创建群集(以秒为单位),动态自动缩放群集,跨团队共享群集。
- 使用 REST API 以编程方式访问群集。
- 即时获得每个版本中的最新 Apache Spark 功能。
- Spark Core API:包含对 R、SQL、Python、Scala 和 Java 的支持。
- 可浏览和可视化数据的交互式工作区。
- 云中完全托管的 SQL 终结点。
- SQL 查询在完全托管的 SQL 终结点上运行,这些终结点的大小根据查询延迟需求和并发用户数进行了调整。
- 与 Microsoft Entra ID(旧称 Azure Active Directory)集成。
- 使用基于角色的访问可以精细地向用户授予对笔记本、群集、作业和数据的权限。
- 企业级 SLA。
- 仪表板支持共享见解,合并可视化效果和文本,用于共享通过查询获取的见解。
- 警报有助于监视和集成,并在查询返回的字段达到阈值时发出通知。 使用警报来监视业务或将其与工具集成,以启动用户加入或支持工单等工作流。
- 企业安全性,包括 Microsoft Entra ID 集成、基于角色的控制,以及可保护数据和业务的 SLA。
- 与 Azure 服务以及 Azure 数据库和存储集成,包括 Synapse Analytics、Cosmos DB、Data Lake Store 和 Blob 存储。
- 与 Power BI 和其他 BI 工具(如 Tableau Software)集成。
Microsoft Azure Databricks 部署的体系结构如下所示:
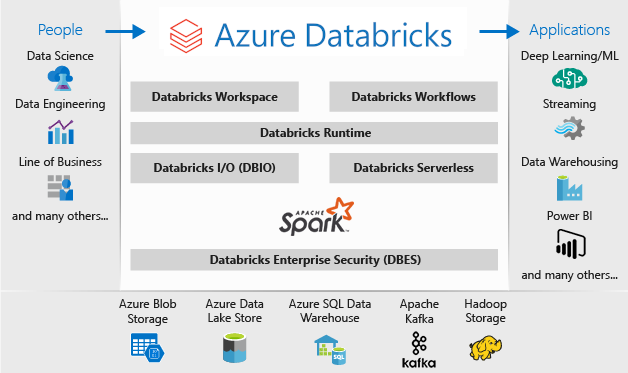
有关 Microsoft Azure Databricks 的详细信息,请参阅什么是 Databricks 数据科学与工程?
Hybrid
Fabric 镜像数据库
作为数据复制体验,Fabric 中的数据库镜像是一种低成本、低延迟的解决方案,用于将数据从各种系统组合到单个分析平台中。 可以将现有数据资产持续复制到 Fabric 的 OneLake 中,包括 Azure SQL 数据库、Snowflake 和 Cosmos DB 中的数据。
借助 OneLake 以可查询格式提供的最新数据,现在可以使用 Fabric 中的各种服务,例如使用 Spark 运行分析、执行笔记本、数据工程、通过 Power BI 报表进行可视化等。
通过 Fabric 镜像可以轻松加速获取见解和决策,打破不同技术解决方案之间的数据孤岛,同时无需开发昂贵的提取、转换和加载 (ETL) 进程来移动数据。
使用 Fabric 镜像功能时,无需将来自多个供应商的不同服务拼凑在一起。 而是可以享受高度集成且易于使用的端到端产品,不仅可以简化分析需求,而且专为确保不同技术解决方案之间的开放性和协作而构建,可读取开源 Delta Lake 表格式。
有关详细信息,请参阅:
- Microsoft Fabric 镜像数据库
- Microsoft Fabric 镜像数据库监视
- 使用 Microsoft Fabric 浏览镜像数据库中的数据
- 什么是 Microsoft Fabric?
- 在 Microsoft Fabric 中的默认 Power BI 语义模型中为数据建模
- 什么是湖屋的 SQL 分析终结点?
- Direct Lake
将 SQL Server 2022 与 Azure Synapse Link for SQL 结合使用
SQL Server 2022 (16.x) 包含一项新功能,支持 SQL Server 表与 Microsoft Azure Synapse 平台 (Azure Synapse Link for SQL) 之间的连接。 Azure Synapse Link for SQL Server 2022 (16.x) 提供自动更改源,用于捕获 SQL Server 中的更改,并将其加载到 Azure Synapse Analytics 中。 它提供近实时分析、混合事务和分析处理,并且对操作系统的影响最小。 数据位于 Synapse 中后,就可以将其与许多不同的数据源合并(无论它们的大小、规模或格式如何),并使用你选择的 Azure 机器学习、Spark 或 Power BI 对所有数据运行强大的分析。 由于自动更改源仅推送新增功能或不同内容,因此数据传输速度要快得多,现在可实现近实时见解,并且对 SQL Server 2022 (16.x) 中的源数据库的性能影响最小。
对于操作工作负载,甚至大多数分析工作负载,SQL Server 可以处理大量数据库大小。有关 SQL Server 的最大容量规范的详细信息,请参阅按 SQL Server 版本划分的计算能力限制。 在具有已分区的 T-SQL 请求的单独计算机上使用多个 SQL Server 实例为应用程序提供横向扩展环境。
使用 PolyBase,SQL Server 实例可以直接从 SQL Server、Oracle、Teradata、MongoDB 和 Cosmos DB 使用 T-SQL 查询数据,而无需单独安装客户端连接软件。 还可以在基于 Microsoft Windows 的实例上使用泛型 ODBC 连接器,通过第三方 ODBC 驱动程序连接到其他提供程序。 借助 PolyBase,T-SQL 查询可以将外部源中的数据连接到 SQL Server 实例中的关系表。 此过程允许将数据保留在其原始位置和格式。 可以通过 SQL Server 实例虚拟化外部数据,以便可以对这些数据进行查询,如同 SQL Server 中的任何其他表一样。 使用 SQL Server 2022 (16.x) 还可通过对象存储(使用 S3-API)硬件或软件存储选项进行即席查询和备份/还原。
两种常规参考体系结构是在独立服务器上使用 SQL Server 进行结构化数据查询的,并单独安装横向扩展非关系系统(如 Apache Hadoop 或 Apache Spark)以便本地链接到 Synapse;另一个选项是在具有解决方案的所有组件的 Kubernetes 群集中使用一组容器。
Windows、Apache Spark 和本地对象存储上的 Microsoft SQL Server
可以在 Windows 或 Linux 上安装 SQL Server,并纵向扩展硬件体系结构,从而使用 SQL Server 2022 (16.x) 对象存储查询功能和 PolyBase 功能来跨系统中的所有数据启用查询。
安装和配置横向扩展平台(如 Apache Hadoop 或 Apache Spark)允许大规模查询非关系数据。 使用一组支持 S3-API 的对象存储系统,SQL Server 2022 (16.x) 和 Spark 可以跨所有系统访问同一组数据。
适用于 SQL Server 和 Azure SQL 的 Microsoft Apache Spark 连接器还允许使用 Spark 作业直接从 SQL Server 查询数据。 有关适用于 SQL Server 和 Azure SQL 的 Apache Spark 连接器的详细信息,请参阅 Apache Spark 连接器:SQL Server 和 Azure SQL。
还可以将 Kubernetes 容器业务流程系统用于部署。 这允许在本地或支持 Kubernetes 或 Red Hat OpenShift 平台的任何云中运行的声明性体系结构。 若要详细了解如何将 SQL Server 部署到 Kubernetes 环境中,请参阅在 Azure 上部署 SQL Server 容器群集,或观看在 Kubernetes 中部署 SQL Server 2019。
有以下需要时,请使用本地 SQL Server 和 Hadoop/Spark 代替 SQL Server 2019 大数据群集:
- 在本地保留整个解决方案
- 对解决方案的所有部分使用专用硬件
- 沿两个方向访问同一体系结构中的关系数据和非关系数据
- 在 SQL Server 与横向扩展非关系系统之间共享一组非关系数据
执行迁移
为迁移选择位置(在云中或混合)后,应权衡停机时间和成本向量,以确定是运行新系统并将数据从以前的系统实时移动到新系统(并行迁移)或备份和还原,还是从现有数据源中重新启动系统(就地迁移)。
下一个决策是使用新的体系结构选项重写系统中的当前功能,或将尽可能多的代码移动到新系统。 虽然前一个选择可能需要更长时间,但它允许使用新体系结构提供的新方法、概念和优势。 在这种情况下,数据访问和功能映射是应重点关注的主要规划工作。
如果计划通过尽可能少的代码更改来迁移当前系统,则语言兼容性是规划的主要重点。
代码迁移
下一步是审核当前系统使用的代码,以及针对新环境运行所需的更改。
需要考虑代码迁移的两个主要途径:
- 源和接收器
- 功能迁移
源和接收器
代码迁移的第一项任务是标识代码用来访问导入的数据、其路径及其最终目标的数据源连接方法、字符串或 API。 记录这些源,并创建到新体系结构位置的映射。
- 如果当前解决方案使用管道系统来通过系统移动数据,则将新的体系结构源、步骤和接收器映射到管道的组件。
- 如果新解决方案还替换管道体系结构,则出于规划目的将系统视为新安装,即使将硬件或云平台重用作替换项也是如此。
功能迁移
迁移所需的最复杂工作是引用、更新或创建当前系统的功能的文档。 如果计划就地升级并尝试尽可能减少代码重写量,则此步骤需要最多时间。
但是,从以前的技术进行迁移通常是更新技术中的最新改进和充分利用它提供的构造的最佳时间。 通常,通过重写当前系统,可以获得更多安全性、性能、功能选择,甚至成本优化。
无论哪种情况,迁移都涉及两个主要因素:新系统支持的代码和语言,以及围绕数据移动的选择。 通常,你应该能够将连接字符串从当前大数据群集更改为 SQL Server 实例和 Spark 环境。 任何数据连接信息和代码转换应该很小。
如果构想当前功能的重写,请将新库、包和 DLL 映射到为迁移选择的体系结构。 可在之前的部分中显示的文档参考中找到每个解决方案提供的每个库、语言和函数的列表。 映射出任何可疑或不支持的语言,并计划使用所选体系结构进行替换。
数据迁移选项
在大规模分析系统中,有两种常见的数据移动方法。 第一种是创建“直接转换”过程,在该过程中原始系统继续处理数据,数据将汇总到一组较小的聚合报表数据源中。 然后,新系统从新数据开始,并从迁移日期开始使用。
在某些情况下,所有数据都需要从旧系统移动到新系统。 在这种情况下,可以从 SQL Server 大数据群集装载原始文件存储(如果新系统支持它),然后将数据分段复制到新系统,也可以创建物理移动。
将当前数据从 SQL Server 2019 大数据群集 迁移到另一个系统高度依赖于两个因素:当前数据的位置和目标(本地或在云中)。
本地数据迁移
对于本地到本地的迁移,可以使用备份和还原策略迁移 SQL Server 数据,也可以设置复制以移动部分或所有关系数据。 SQL Server Integration Services 还可用于将数据从 SQL Server 复制到另一个位置。 有关使用 SSIS 移动数据的信息,请参阅 SQL Server Integration Services。
对于当前 SQL Server 大数据群集环境中的 HDFS 数据,标准方法是将数据装载到独立的 Spark 群集,并使用对象存储过程移动数据,以便 SQL Server 2022 (16.x) 实例可以访问它,或将其保持原样并继续使用 Spark 作业处理数据。
云中数据迁移
对于位于云存储或本地的数据,可以使用具有 90 多个连接器的 Azure 数据工厂,通过计划、监视、警报和其他服务进行完整管道传输。 有关 Azure 数据工厂的详细信息,请参阅什么是 Azure 数据工厂?
如果想要安全快速地将大量数据从本地数据资产移动到 Microsoft Azure,则可以使用 Azure 导入/导出服务。 使用 Azure 导入/导出服务,可将磁盘驱动器寄送到 Azure 数据中心,从而安全地将大量数据导出到 Azure Blob 存储和 Azure 文件存储。 此外,还可以使用此服务将数据从 Azure Blob 存储传输到磁盘驱动器,然后再寄送到本地站点。 可将单个或多个磁盘驱动器中的数据导入到 Azure Blob 存储或 Azure 文件。 对大量数据,使用此服务可能是最快的途径。
如果要使用由 Microsoft 提供的磁盘驱动器来传输数据,可以使用 Azure Data Box 磁盘将数据导入 Azure。 有关详细信息,请参阅什么是 Azure 导入/导出服务?
有关这些选项及其附带决策的信息,请参阅使用 Azure Data Lake Storage Gen1 满足大数据要求。