根据 SharePoint 中的特定性能要求重新设计企业搜索拓扑
适用于: 2013 2016 2019 Subscription Edition
2013 2016 2019 Subscription Edition  SharePoint in Microsoft 365
SharePoint in Microsoft 365
如果您的搜索环境具有特殊的性能要求且根据在 SharePoint Server 2016 中规划企业搜索体系结构中的指南操作无法满足这些要求,解决方案是扩展企业搜索体系结构的拓扑:
重新设计拓扑(本文)
实现重新设计的拓扑(在 SharePoint Server 中管理搜索拓扑)
是否熟悉 SharePoint Server 2016 中搜索系统的组件,及如何交互? 在开始之前,请阅读 SharePoint Server 中的搜索体系结构概述和 SharePoint Server 2016 搜索体系结构(或 SharePoint Server 2013 搜索体系结构),以便熟悉搜索体系结构、搜索组件、搜索数据库和搜索拓扑。
在本文中,我们将向您分步介绍如何重新设计搜索拓扑以满足特殊的性能要求:
执行这些步骤后,您将了解:
对于每种搜索组件和搜索数据库,您的拓扑需要多少。
每种搜索组件要部署在哪些应用程序服务器和数据库上。
每个应用程序服务器和数据库服务器需要多少硬件资源。
第 1 步:有哪些特殊的性能要求?
确保您了解特定性能要求背后的业务需求。 例如,新闻和财务搜索需要近实时编制索引的全新数据,而诉讼支持服务则需要引入一次性编制索引的分批数据。 使用以下一种或多种方式表示性能要求:
索引项目的数量。
搜索解决方案每秒钟必须爬网的项目数量及延迟。
搜索解决方案每秒钟必须服务的查询数量及延迟。
除了这些性能要求以外,您的环境可能还对查询结果的相关性以及应保持冗余的搜索拓扑有要求。 有时您没有特殊的性能要求,但您在体系结构中发现了一个瓶颈可能会影响性能。 我们也将介绍这一点。
第 2 步:我应该扩展哪些搜索组件?
要提供更高的性能或消除瓶颈,您可以添加更多搜索组件以执行任务,也可以向托管搜索组件的服务器添加更多资源。 添加更多搜索组件称为向外扩展,向服务器添加更多资源称为向上扩展。 哪些搜索组件向外扩展,或者哪些服务器向上扩展,这取决于要改进的性能指标或要消除的瓶颈。 下面是一些示例:
如果环境需要更高的查询速率且用于编制索引的 CPU 资源是一个瓶颈,请将另一个索引副本添加到索引的每个分区。 这样搜索即可同时服务于更多查询。
如果用于处理爬网内容的 CPU 资源是一个瓶颈,请向外扩展内容处理组件的数量。 您也可以向上扩展内容处理组件,方法是在具有更多或更快 CPU 的服务器上运行这些组件。 不管哪种扩展方式都意味着将增加用于处理内容的 CPU 资源。
如果分析组件未能以足够快的速度完成分析,请向上扩展托管分析组件的服务器的处理器资源、磁盘 IOPS 或网络带宽。
请注意,我们不支持无限制地向外扩展搜索组件或数据库的数量。 在搜索限制中查找最大限制,并保持在这些限制范围内,以确保搜索组件和数据库之间的通信及时性和稳定性。 如有必要,请减少搜索组件的数量,以减小搜索体系结构的容量。
在以下部分中,我们为您介绍了扩展哪些搜索组件或数据库以满足每个要求的指南:
如何处理索引中的更多项目
索引项目数量增加,索引项目则以与之前相同的速率变化,此时请向外扩展这些搜索组件和数据库,以增加搜索拓扑的容量:
| 搜索组件或数据库 | 准则 |
|---|---|
| 索引组件 | 每 2,000 万1个索引项使用一个索引分区。 每个分区包含分区的一个或多个副本。 所有分区必须具有相同的副本数量。 一个索引组件表示一个索引副本。 因此,如果您需要索引的两个副本,您需要具有索引分区的两倍索引组件。 例如,具有 8,000 万2个项目的冗余索引需要有四个分区。 八个索引组件表示有四个分区,每个分区使用两个副本。 |
| 爬网数据库 | 在内容集中项目中对每 2000 万个项目使用一个爬网数据库。 例如,包含一亿个项目的索引需要五个爬网数据库。 如果索引项目数量增加表示爬网速率提高,则您还需要更多 IOPS 资源来为爬网数据库服务。 如果您的爬网速率是每秒钟爬网一个文档,则爬网数据需要大约 10 个 IOPS。 |
| 链接数据库 | 在内容集中项目中对每 6000 万个项目使用一个链接数据库。 例如,包含一亿个项目的索引需要两个链接数据库。 如果内容增加表示爬网速率提高,则您可能需要更多 IOPS 资源来为链接数据库服务。 |
| 分析报告数据库 | 您需要多少分析报告数据库取决于搜索环境使用分析的方式及频率。 一般来说,在分析性能开始下降时增加分析报告数据库。 例如,当夜间更新数据库开始需要更多时间时。 当数据库大小达到 250 GB 或总数达到 2000 行时,或者当每天的视图数量达到 500,000 个唯一项目时。 |
具有SharePoint Server 2013 或 SharePoint Server 2016 的 1 1000 万个项目,其资源小于 500 GB 存储、32 GB RAM 和 8 个 CPU 核心。
具有SharePoint Server 2013 或 SharePoint Server 2016 的 2 4000 万个项目,其资源小于 500 GB 存储、32 GB RAM 和 8 个 CPU 核心运行。
如何提高结果的引入速率和新鲜度
在某些情况下,可能需要提高引入率。 例如,如果你的环境需要非常新的结果,并且内容量接近搜索体系结构的项上限,或者内容经常更改。 如果用户以前在团队网站上存档文件,内容可能会经常更改,但现在他们在处理文件时将文件存储在 OneDrive 上。 搜索索引用户对其文件所做的所有更改。
了解哪些因素会影响搜索引入项目的速度将很有帮助:
搜索可以什么速度爬网项目。 这取决于以下因素:
爬网组件和内容源之间的连接速度。
要爬网的项目的类型和平均大小。
托管爬网数据库的 SQL Server 的性能。
爬网组件具有的 CPU 和内存资源的数量。
在编制索引之前,每个项目需要进行什么程度的内容处理。
索引具有多少个分区。 更多分区允许搜索分散索引负载。
下面是您需执行的操作:
Check the freshness of the results in your farm by looking at the age distribution of the crawled items. In the SharePoint Central Administration website, go to Crawl Health Reports and select Crawl Freshness. What age distribution that's acceptable for your farm depends on your business requirements. Here's an example: If the Crawl Freshness page shows that it takes four hours to index 90% of the content, but your requirement is 30 minutes, then increase the ingestion rate.
在“爬网新鲜度页面”上,识别一天中哪些时间段的结果不够新鲜。
遵循相关准则以提高这些时间段的引入速度。
| 准则 |
|---|
| 提高特定内容源的新鲜度 |
| 增加用于爬网的处理资源 |
| 增加爬网数据库的处理资源 |
| 增加用于内容处理的处理和内存资源 |
| 增加索引分区数量 |
提高特定内容源的新鲜度
检查爬网计划,识别在新鲜度较低的时间段中搜索爬网的内容源。 如果某个特定内容源的新鲜度较低,请考虑采取以下措施:
提高托管爬网组件的服务器与该内容源之间的连接速度。 爬网速率、从内容源下载项目以及将项目传递到内容处理组件推动了对爬网组件的网络带宽的需要。
如果内容源为 SharePoint,服务器场可能需要更多专用的爬网目标。 在管理爬网负载 (SharePoint 2010) 中阅读关于爬网目标的信息。
提升内容数据库的性能。 有关具体做法,请参阅 SharePoint Server 服务器场中 SQL Server 的最佳实践。
增加用于爬网的处理资源
如果爬网组件经常占用全部处理器资源,请考虑添加其他爬网组件,或向托管爬网组件的服务器添加更多处理器资源。 爬网速率、链接发现和爬网管理决定了是否需要添加处理器资源。 通常,在经过 Microsoft 估计的中小型示例搜索体系结构等搜索体系结构中使用两个爬网组件时,爬网速度足够快。 大型和特大型示例搜索体系结构可能需要超过两个爬网组件。
增加爬网数据库的处理资源
检查托管爬网数据库的 SQL Server 是否具有足够资源。 有关具体做法,请参阅 SharePoint Server 服务器场中 SQL Server 的最佳实践。
如果所有爬网数据库均使用大量处理器资源,请考虑向托管数据库的 SQL Server 添加更多处理器资源,或者添加另一个具有与现有 SQL Server 相同数量的爬网数据库的 SQL Server 。 例如,如果您具有两个 SQL Server,每个 SQL Server 具有三个爬网数据库,请添加另一个具有三个爬网组件的 SQL Server。
If only one or a few crawl databases use a lot of processor resources, this means that the load is uneven across the crawl databases. Consider rebalancing the content across all crawl databases. Note that during rebalancing search pauses crawling, so results are less fresh while rebalancing and until crawling has caught up with the changes that took place during the pause. You trigger rebalancing with the Balance button on the Databases page. In Search Administration, go to Crawl Log and select Databases.
增加用于内容处理的处理和内存资源
如果内容处理组件使用将近 100% 的 CPU 资源,请考虑添加更多内容处理组件,或者向托管内容处理组件的服务器添加更多 CPU 资源。
如果您发现内存经常重启,请考虑增加托管内容处理组件的服务器上的内存量。 我们的经验是每个 CPU 内核具有 2 GB 工作内存。
增加索引分区数量
Check the content processing activity. You find this by going to Search Administration, selecting Crawl Health Report and then selecting Content Processing Activity. If indexing is the activity that takes most time, consider dividing the index into more partitions. More index partitions lets search spread the load of indexing.
如果您在运行的安装上添加更多分区,索引将自己重新分区。 这可能需要数小时或数天。 重新分区需要多长时间取决于重新分区开始时服务器场的状态。
如何降低查询延迟并提高查询吞吐量
搜索每秒钟可服务的查询数量称为查询吞吐量。 查询吞吐量取决于搜索用于处理查询的时间,以及由于处理资源不可用时等待的时间。 处理时间和等待时间的总和称为查询延迟。 降低查询延迟可增加查询吞吐量。 要降低查询延迟,请按照以下一个或两个准则操作:
| 准则 |
|---|
| 缩短查询的处理时间 |
| 缩短查询的等待时间 |
缩短查询的处理时间
考虑向索引添加更多分区。 分区越多意味着每个分区中的项目越少。 项目越少意味着每个分区对查询的相应速度越快。 但是分区太多也不是好事。 因为查询处理组件必须将每个分区的响应合并起来才能生成对查询的答复,索引的分区越多,合并需要的时间就越长。 所有分区必须具有相同的副本数量。
如果您在运行的安装上添加更多分区,索引将自己重新分区。 这可能需要数小时或数天。 重新分区需要多长时间取决于重新分区开始时服务器场的状态。
缩短查询的等待时间
考虑采取以下措施:
增加索引的更多副本。 当您添加更多副本时,搜索会在副本之间分发查询并同时处理查询。 一个索引组件表示一个索引副本。 所有分区必须具有相同数量的副本,因此请将一个索引组件添加到索引的每个分区。 当您将索引组件作为副本添加到运行的安装上的现有分区时,搜索会使用索引分区中的数据自动生成新的副本。 在新的副本可以运行之前,可能需要数小时。
向托管索引组件的服务器增加更多内存。
在托管索引组件的服务器上,切换到索引的更快存储,例如固态驱动器 (SSD)。
向托管索引组件的服务器增加更多处理器资源。 组件每秒钟将处理更多查询。 例如,如果服务器具有 2 GHz CPU,则一个内核可以处理的容量如下:
如果您的索引中有 100 万个项目,每秒钟可处理 5 个查询。
如果您的索引中有 500 万个项目,每秒钟可处理 2 个查询。
如果您的索引中有 1000 万个项目,每秒钟可处理 1 个查询。
向托管查询处理组件的服务器增加更多处理器资源。 组件每秒钟将处理更多查询,尤其是当查询频率较低且较复杂时。 查询速率和查询转换的数量推动了对查询处理组件的处理器资源的需要。 查询处理组件通常需要一个 CPU 内核,每秒钟处理 4 个查询。
如何缩短分析处理时间
分析处理在每天夜间进行。 分析处理组件将中间数据存储在托管组件的服务器上,将分析结果存储在分析报告数据库中。 如果发生故障而无法进行分析处理,也不会影响文档爬网或答复查询。 但查询结果将无法达到最佳相关性。
考虑采取以下措施:
如果您的环境要求查询结果达到最佳相关性,但分析处理速度不够快而无法满足此要求,请添加更多磁盘(转轴)或速度更快的磁盘。
如果分析处理所需的时间开始比平常增多,请增加一个分析报告数据库。 数据库大小可能会达到 250 GB 或总数达到 2000 行,或者每天的视图数量达到 500,000 个唯一项目。
如果分析处理需要 24 小时以上的时间才能完成,请增加更多分析处理组件,或者向托管分析处理组件的服务器增加更多处理器资源。 索引中的项目数量和网站活动推动了对处理器资源的需要。
如果分析处理一直无法完成,或者您收到针对托管分析组件的服务器上磁盘的运行状况警报,请向服务器增加更多磁盘空间。 要让分析组件更快地处理更多中间数据,请考虑增加更多分析处理组件,或者向托管分析处理组件的服务器增加更多处理器资源。
如何将搜索组件和数据库设为冗余
当您托管独立容错域上的冗余搜索组件和数据库时,您的搜索体系结构支持高可用性。 建议使用冗余搜索数据库和组件设计搜索拓扑。 Microsoft测试的所有示例搜索体系结构都具有冗余的搜索组件和数据库,你可能会发现在处理自己的拓扑时研究这些示例很有用 (请参阅 SharePoint 2016) 企业搜索体系结构 。
请按以下准则操作:
| 准则 |
|---|
| 将索引设为冗余 |
| 将爬网、内容处理、查询处理、分析处理和搜索管理组件设为冗余 |
| 将搜索数据库设为冗余 |
将索引设为冗余
如果每个索引分区中具有两个或更多副本,则您的索引为冗余。 如果托管某个索引副本的服务器出现故障,可能会降低性能,但搜索仍可以服务查询并提供索引项目。 但是,如果环境要求始终具有相同性能,搜索将需要更多冗余索引组件。 例如:您将搜索拓扑设计为每个分区具有两个副本以缩短查询等待时间,您的环境要求查询时间始终保持较短。 增加每个分区的索引副本数量。
所有分区必须具有相同的副本数量。 一个索引组件表示一个索引副本。 因此,如果需要索引的两个副本,需要具有索引分区的两倍索引组件。 例如,使用 SharePoint Server 2016 时,具有 8000 万个项目的冗余索引需要四个分区。 八个索引组件表示四个分区,每个分区使用两个副本。
当您将索引组件作为副本添加到运行的安装上的现有分区时,搜索会使用索引分区中的数据自动生成新的副本。 在新的副本可以运行之前,可能需要数小时。
将爬网、内容处理、查询处理、分析处理和搜索管理组件设为冗余
现在我们以爬网组件为例。 如果您需要使托管爬网组件的一个服务器停机以执行维护,这可能会降低结果的新鲜度,但搜索仍然可以爬网所有内容。 但是,如果环境要求结果始终保持相同的新鲜度,搜索需要更多冗余爬网组件。 例如:您将搜索拓扑设计为具有三个爬网组件,您希望即使在两个爬网组件服务器发生故障时仍可保持结果的新鲜度。 请再增加两个爬网组件。
搜索管理组件是这一原则的例外。 一个搜索管理组件具有可用于任何大小的搜索拓扑的足够容量。 因此,两个搜索管理组件足够保持冗余度。
内容处理组件可保持相互之间的负载平衡,因此冗余内容处理组件会增加用于处理项目的容量。
将搜索数据库设为冗余
若要让搜索数据库成为冗余数据库,请使用 SQL Server 提供的高可用性备选方案(请参阅为 SharePoint Server 创建具有高可用性的体系结构和策略)。
第 3 步:选择以物理方式还是虚拟方式运行服务器
当您最初规划搜索体系结构时,您决定了是使用物理服务器还是虚拟机,还是结合使用两者。 考虑当时的决定是否仍然有效。 如果您现在的搜索组件数量大大增加,您可能需要使用虚拟机简化体系结构管理。 例如,替换故障的虚拟机比替换物理计算机要容易。 另请注意,尽管虚拟环境更容易管理,但其性能级别有时可能会稍低于物理环境。 物理服务器在同一服务器上可托管的搜索组件比虚拟服务器要多。 您可以在 Overview of farm virtualization and architectures for SharePoint 2013中找到有用指导。
第 4 步:使用哪些服务器托管哪些搜索组件或数据库?
现在您已重新设计搜索拓扑,下一步是将搜索和数据库组件分配到物理或虚拟服务器。 没有一种最佳方法来将搜索组件分配到物理计算机或虚拟机,但我们为您提供了一些准则:
每个服务器一种搜索组件类型
每个物理服务器或虚拟机只能托管一种类型的一个搜索组件。 索引组件是例外。 物理服务器或虚拟机最多可以托管四个索引组件。 若要了解这些限制,可以参阅搜索限制。
批量处理组件与实时组件相互分开
避免在相同的物理服务器或虚拟机上混合批量处理和实时处理。 爬网、内容处理和分析处理组件执行批量处理。 索引和查询处理组件执行实时处理。
不将争用资源的搜索组件混合
如果搜索组件会争用相同的资源,避免将这些组件在物理服务器或计算机上混合。 下表介绍了每个组件需要的相对资源量。
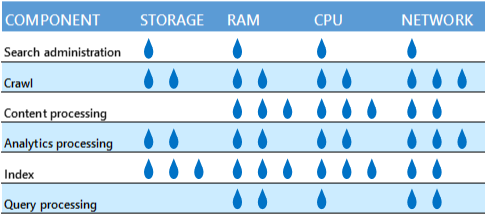
例如,将爬网组件和分析处理组件放在同一个服务器上可能不是一个好主意,因为这两个组件都会使用大量网络带宽。 但是,如果物理服务器或虚拟机具有足够的网络容量,则组件不会争用。
再例如,经过 Microsoft 估计的特大型搜索体系结构示例。 在此示例中,我们将爬网和搜索管理组件置于单独的虚拟机上。 这有利于提高爬网速度,否则这两个组件可能会争夺处理器资源。
使用故障域
将冗余搜索组件分配到单独故障域中的主机。
第 5 步:我应了解哪些硬件要求?
下一步是规划您需要的硬件:
选择主机服务器的硬件资源量
每个搜索组件和搜索数据库需要主机服务器的最少量的硬件资源即可运行良好。 但是,您拥有的硬件资源越多,您的搜索体系结构的性能越好。 因此,硬件资源数量最好多于硬件资源的最低数量。 每个搜索组件需要的资源取决于工作负荷,这主要由爬网速率、查询速率和索引项目数决定。
例如,在 Windows Server 2008 R2 Service Pack 1 (SP1) 中托管虚拟机时,每个虚拟机使用的 CPU 内核不能超过四个。 在 Windows Server 2012 或更高版本中,您在每个虚拟机上使用八个或更多 CPU 内核。 然后您可以为每个虚拟机向外扩展更多 CPU 内核,而无需向上扩展更多虚拟机。 设置使用相同硬件资源托管相同搜索组件的服务器或虚拟机。 现在我们以索引组件为例。 当您在虚拟机上托管索引分区时,性能最差的虚拟机决定了整个搜索体系结构的性能。
一般存储
确保每台主机服务器具有足够的磁盘空间进行 Windows Server 操作系统和 SharePoint Server 2016 程序文件的基本安装。 主机服务器还需要有可用的硬盘空间进行日志记录、调试、创建内存转储等诊断、日常操作和页面归档。 一般情况下,80 GB 的磁盘空间足以供 Windows Server 操作系统和 SharePoint Server 2016 程序文件使用。
增加每个数据库服务器的 SQL 日志存储空间。 如果没有将数据库服务器设置为经常备份数据库,SQL 日志则会占用大量存储空间。 若要详细了解如何规划 SQL 数据库,请参阅存储和 SQL Server 容量规划与配置 (SharePoint Server)。
分析报告数据库所需的最低存储量可能各不相同。 这是因为存储量取决于用户与 SharePoint Server 2016 的交互方式。 当用户交互频率较高时,通常要存储更多事件。 检查当前搜索体系结构用于分析数据库的存储量,并至少为您重新设计的拓扑分配此存储量。
索引组件的最低资源
这是服务器或虚拟机托管一个索引组件,或者托管一个索引组件和一个查询处理组件所需的最低资源:
| 存储 | 内存 | 处理器 | 网络带宽 |
| 500 GB 用于索引1 | 32 GB1 | 64 位,最少 8 核1、2。 | 2 GB |
1使用 SharePoint Server 2013 时,最小资源量为 500 GB 存储、16 GB RAM 和 4 个 CPU 核心。
2可以在 SharePoint Server 2016 中使用 16 GB RAM 和四个 CPU 内核,但之后每个索引组件最多可以托管 1,000 万个项目(而不是 2000 万个项目)。
分析处理组件的最低资源
这是服务器或虚拟机托管一个分析处理组件所需的最低资源:
| 存储 | 内存 | 处理器 | 网络带宽 |
| 300 GB 用于本地分析处理 | 8 GB | 64 位,最少 4 个内核,建议使用 8 个内核。 | 2 GB |
如果服务器托管一个分析处理组件和一个或多个批量处理组件,请将内存增加到 16 GB。
爬网、内容处理、查询处理和搜索管理组件的最低资源
这是服务器或虚拟机托管其中一个组件所需的最低资源:
| 存储 | 内存 | 处理器 | 网络带宽 |
| 可选 | 8 GB | 64 位,最少 4 个内核,建议使用 8 个内核。 | 2 GB |
如果服务器托管两个或更多组件,请将内存增加到 16 GB。
查询处理组件需要大量网络带宽。 索引分区数量和查询与结果大小推动了对网络带宽的需要。 例如,如果每个查询处理组件每秒钟处理 20 个查询 (20 QPS/QPC),索引具有 20 个索引分区,则托管查询处理组件的服务器或虚拟机将产生 200 MB 传入流量和 100 MB 传出流量。
搜索数据库的最低资源
下面介绍了服务器或虚拟机托管一个或多个搜索数据库至少所需的资源:
| 存储空间 | 内存 | 处理器 | 网络带宽 |
| 分析报告数据库需要的存储空间因搜索环境使用分析的方式及频率而异。 可参照分析报告数据库的当前存储空间。 | 8 GB(用于小型部署)。 16 GB(用于中型部署) |
64 位,4 个内核。 | 2 GB |
规划存储性能
存储速度影响搜索性能。 请确保您的存储速度足够快,从而能够处理来自搜索组件和数据库的流量。 磁盘速度以每秒的 I/O 操作数 (IOPS) 进行测量。
对于在存储空间内分发来自搜索组件和操作系统的数据,您所决定的方式会影响搜索性能。 比较好的做法是:
在具有普通性能的三个单独存储卷或分区之间拆分 Windows Server 操作系统文件、SharePoint Server 2016 程序文件和诊断日志。
在单独存储卷或分区上存储搜索组件数据。 对于索引组件,该存储还必须具有高性能。
注意
[!注意] 当您在主机上安装 SharePoint Server 2016 时,您可以为搜索组件数据设置一个自定义位置。 需要存储数据的主机上的任何搜索组件将数据存储在此位置。 稍后要更改此位置,必须重新安装 SharePoint Server 2016。
选择存储类型
有关存储体系结构和磁盘类型的概述,请参阅存储和 SQL Server 容量规划与配置 (SharePoint Server 2016)。 托管索引、分析处理和搜索管理组件或搜索数据库的服务器的存储空间必须能够保持低延迟,同时还能确保足够的每秒 I/O 操作数 (IOPS)。 下表展示了每个搜索组件和数据库要求的 IOPS 数。
如果您部署诸如 SAN/NAS 的共享存储,一个搜索组件的高峰磁盘负载通常与另一个搜索组件的高峰磁盘负载一致。 若要获取共享存储的 IOPS 搜索要求量,您需要将每一个这些组件的 IOPS 要求量加起来。
所示组件 IOPS 要求
| 组件名称 | 组件详细信息 | IOPS 要求 | 独立存储卷/分区的使用 |
|---|---|---|---|
| 索引组件 | 合并索引时和处理并响应查询时使用存储。 | 64 KB 随机读取时要求 300 IOPS。 256 KB 随机写入时要求 100 IOPS。 顺序读取时要求每秒 200 MB。 顺序写入时要求每秒 200 MB。 |
是 |
| 分析组件 | 以批量处理的形式本地分析数据。 | 否 | 是 |
| 爬网组件 | 在将下载的内容发送到内容处理组件之间本地存储该内容。 存储受内容带宽的限制。 | 否 | 是 |
搜索数据库 IOPS 要求
| 数据库名称 | IOPS 要求 | I/O 子系统上的典型负载。 |
|---|---|---|
| 爬网数据库 | 中等到高 IOPS | 每秒 1 个文档 (DPS) 爬网率要求 10 IOPS。 |
| 链接数据库 | 中等 IOPS | 搜索索引中每 100 万项目要求 10 IOPS。 |
| 搜索管理数据库 | 低 IOPS | 不适用。 |
| 分析报告数据库 | 中等 IOPS | 不适用。 |
选择您的搜索体系结构如何支持高可用性
如果您对高可用性策略不熟悉,下面这篇文章将能帮助您实现入门:为 SharePoint Server 创建具有高可用性的体系结构和策略。 当您在单独的故障域中托管冗余搜索组件和数据库时,服务器场某个部分停机不会使整个服务终止。 但是,搜索性能会下降,因为搜索组件无法再共享负载。 要降低失去单个服务器的可能性,最好改进本地冗余性。 对于搜索体系结构中的每个主机服务器:
在每个服务器上使用 RAID 存储。
在每个服务器上安装多个冗余网络连接。
安装多个冗余电源,每个服务器均具有独立布线或不间断电源 (UPS)。
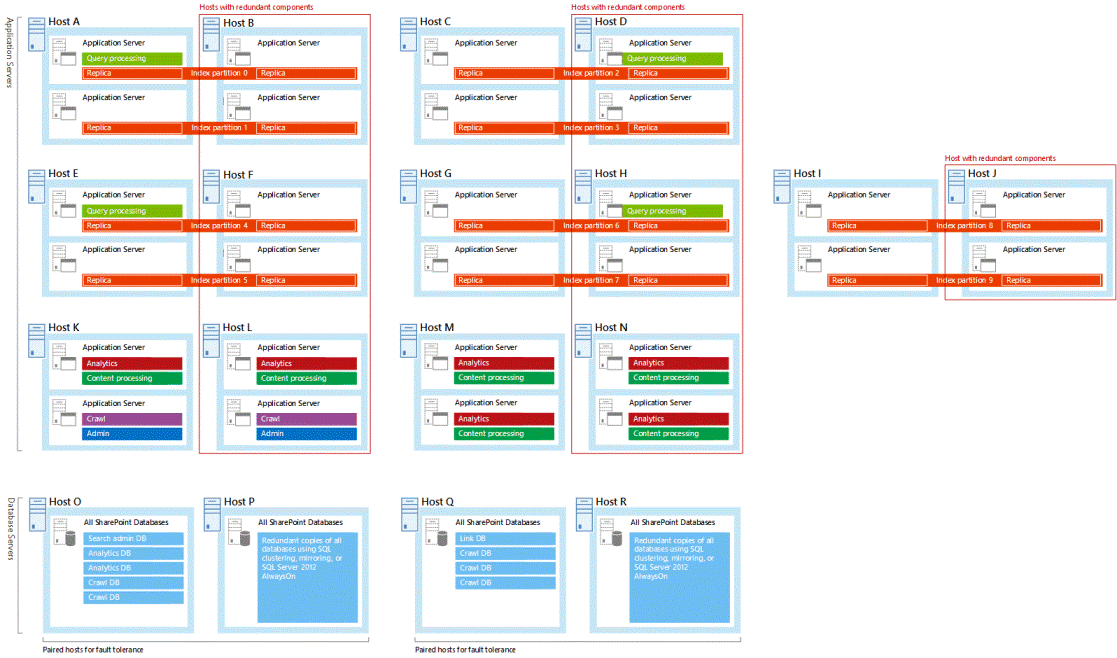
所有示例搜索体系结构在独立服务器上托管冗余搜索组件。 在示例搜索体系结构中,每个主机对中最右侧的主机为冗余主机。 下面显示了大型搜索体系结构,其中框出了冗余主机: