查看数据资产的数据质量分数
创建数据质量规则并运行数据质量扫描后,数据资产将根据规则的结果接收数据质量分数。 本文介绍如何计算分数,以便更深入地了解数据质量结果,并帮助你开发作项以提高数据的完整性。
了解数据质量分数
数据质量规则的目标是提供数据状态的说明。 具体而言,它显示数据与规则描述的理想状态的距离。 每个规则在运行时都会生成一个分数,用于描述数据与其所需状态的接近程度。 大多数规则都非常直接:它们将已通过评估的行总数除以达到分数的行总数。
用于根据列中的数据计算规则的数据质量分数的公式是:
[(total number of passed records)/(passed records + failed records + miscast records + empty records + ignored records)]
- 分子 = 传递的记录数
- 分母 = 记录总数 (传递记录数 + 失败记录数 + 错误转换记录数 + 空记录数 + 忽略记录数)
- 传递 - 通过应用规则的记录数
- 无价值 - 评估此规则所需的列并不宝贵
- 失败 - 应用规则失败的记录数
- 错误转换 - 资产的数据类型,以及客户将其列为不匹配的类型。 无法将其转换为表示的类型。
- 空 - null 或空白记录
- 忽略 - 行未参与规则评估。 客户可以表达要忽略的行。 例如,忽略电子邮件 = “n/a” 或忽略 departmentCode = “test” 或 “internal” 的所有行
然后,Microsoft Purview 数据质量通过生成列分数来了解每个列的状态。 此分数是该列上规则的所有分数的平均值。

计算列分数后,用于计算数据产品和治理域的平均数据质量分数百分比的公式是:
[(Percentage 1 + Percentage 2) / (Sample size 1 + Sample size 2)] x 100
(分数乘以 100,使分数更易于阅读。)
示例计算
假设有一个列未定义 “空/空白字段”规则 。 这意味着此列允许 null 值。 因此,在这种情况下,某些规则(如 唯一值规则)将筛选掉 null 值。
例如:如果资产在表中有 10,000 行,但 3,000 行为 null,500 行不唯一,则分数将为: ((10000 - 3000 - 500)/(10000 - 3000) )* 100 = 93
评估数据和确定分数时,将忽略 null 行。
特定规则分数
对于 自定义规则 ,你可能会在唯一值规则中看到类似的功能,但在这种情况下,筛选器不在 null 上,而是筛选器表达式。
某些规则(如 新鲜度规则)要么通过,要么失败。 因此,他们的分数将是 0 或 100。 新鲜度规则应用于数据资产级别,而不是列级别。
规则详细信息和历史记录
可以通过选择规则来查看规则分数的详细信息和历史记录。 选择特定规则名称并导航到“规则 历史记录 ”选项卡,可看到特定规则的不同扫描运行的趋势。
规则 详细信息 提供有关特定规则的各种运行传递、失败和忽略的行数的信息。 处于 草稿状态 (OFF 状态的规则) 的分数不会影响全局分数。 在质量扫描期间根本不会运行草稿状态的规则,因此不会有分数。

列和规则具有多对多关系,同一规则可以应用于多个列,许多规则可以应用于同一列。 可以通过在“架构”窗格中查看趋势线来查看每个规则的趋势模式。
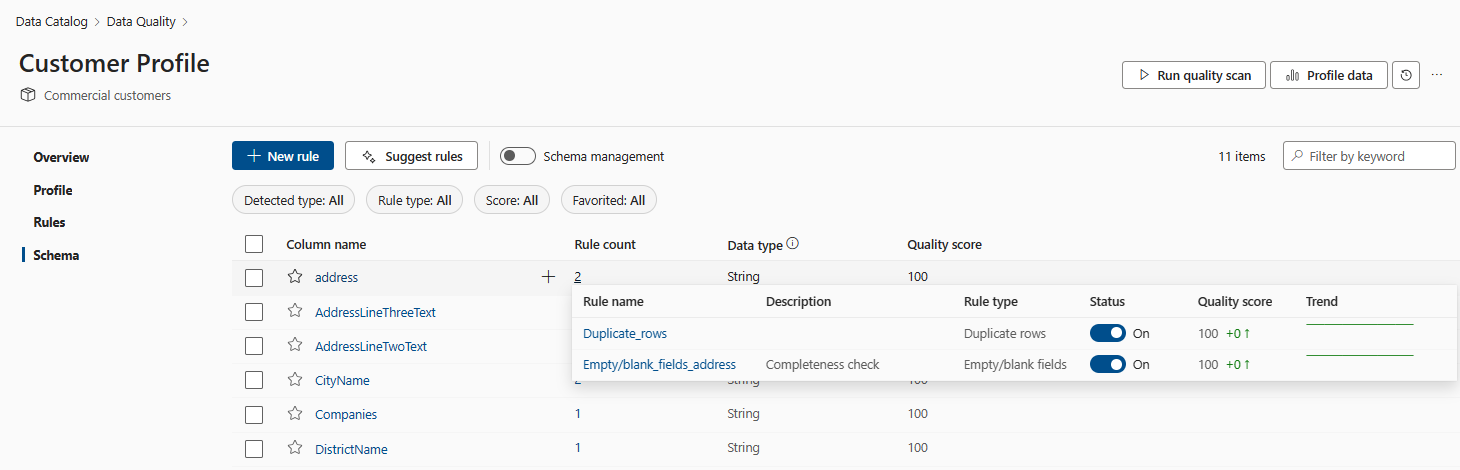
资产级别数据质量分数趋势适用于最近 50 个运行。 此质量分数趋势可帮助数据质量专员监视每月的数据质量趋势和波动。 如果质量分数不符合阈值或业务预期,数据质量还可以针对每次数据质量扫描 触发警报 。
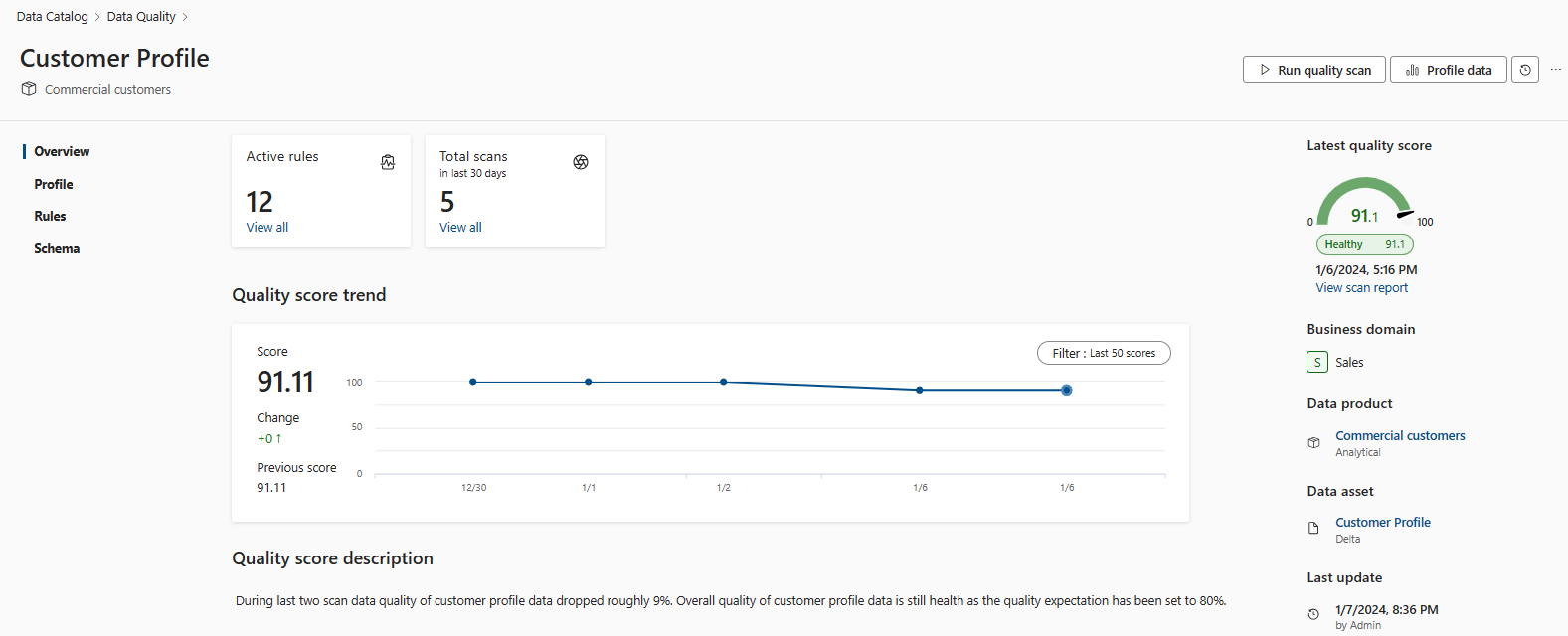
全局分数是在资产上定义的所有生产规则的平均值。 资产级别全局分数也会汇总到数据产品级别和治理域级别。 全局分数旨在作为数据质量上下文中数据资产、数据产品和治理域状态的官方定义。

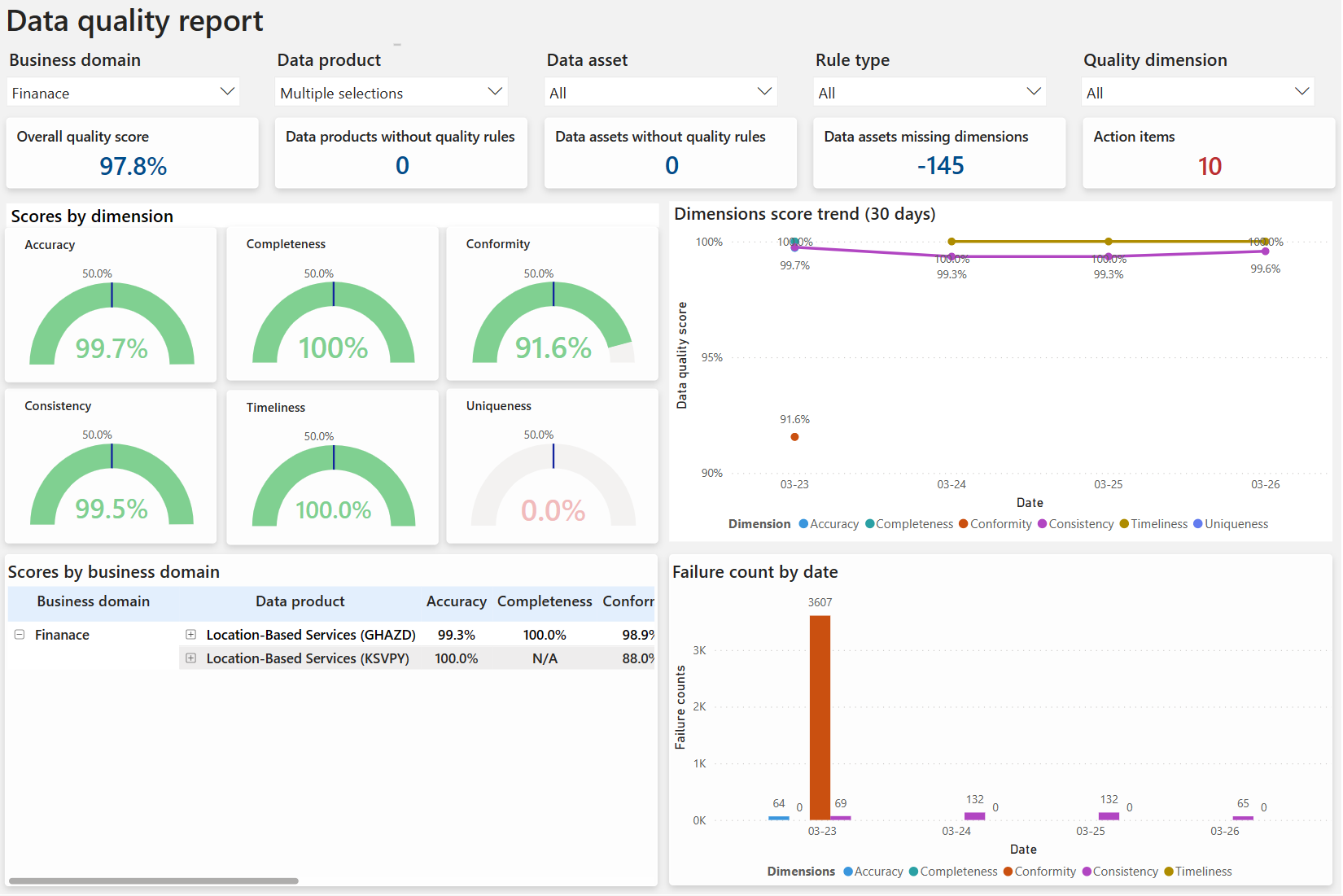
为数据质量维度创建摘要报表。 此报表包含每个数据质量维度的数据质量分数。 此报表中也发布了治理域的全局分数。 可以从此 Power BI 报表中浏览每个治理域、数据产品和数据资产的质量分数。


注意
- 数据质量维度是数据从业者识别的术语,用于描述数据的特征,这些数据可以根据定义的标准进行度量或评估,以便量化用于经营业务的数据的质量级别。
- 资产的数据质量分数是应用于其列的规则分数的算术平均值。
- 数据产品的数据质量分数是与该数据产品关联的数据资产的数据质量分数的算术平均值。
- 治理域的数据质量分数是与该域关联的数据产品的数据质量分数的算术平均值。