浏览、学习、创建和使用数据质量规则
数据质量是衡量组织中数据完整性的度量,使用数据质量分数进行评估。 根据Microsoft Purview 统一目录中定义的规则对数据的评估生成的分数。
数据质量规则是组织为确保数据的准确性、一致性和完整性而建立的基本准则。 这些规则有助于维护数据完整性和可靠性。
下面是数据质量规则的一些关键方面:
准确性 - 数据应准确表示真实实体。 上下文很重要! 例如,如果要存储客户地址,请确保它们与实际位置匹配。
完整性 - 此规则的目的是标识空数据、null 数据或缺失数据。 此规则验证所有值都存在 (但不一定正确) 。
符合性 - 此规则确保数据遵循数据格式设置标准,例如日期、地址和允许的值的表示形式。
一致性 - 此规则检查同一记录的不同值是否与给定规则一致,并且没有矛盾。 数据一致性可确保在不同记录中统一表示相同的信息。 例如,如果你有产品目录,则一致的产品名称和说明至关重要。
时间线 - 此规则旨在确保在尽可能短的时间内访问数据。 它可确保数据是最新的。
唯一性 - 此规则检查值是否不重复,例如,如果每个客户应该只有一条记录,则同一客户没有多个记录。 每个客户、产品或交易都应具有唯一标识符。
数据质量生命周期
创建数据质量规则是数据质量生命周期中的 第六 步。 前面的步骤包括:
- 在 统一目录 中分配用户 () 数据质量专员权限,以使用所有数据质量功能。
- 在Microsoft Purview 数据映射中注册和扫描数据源。
- 将数据资产添加到数据产品
- 设置数据源连接,以便为数据质量评估准备源。
- 为数据源中的资产配置和运行数据分析。
所需角色
查看现有数据质量规则
从Microsoft Purview 统一目录,选择“运行状况管理”菜单和数据质量子菜单。
在数据质量子菜单中选择 治理域。
选择数据产品。
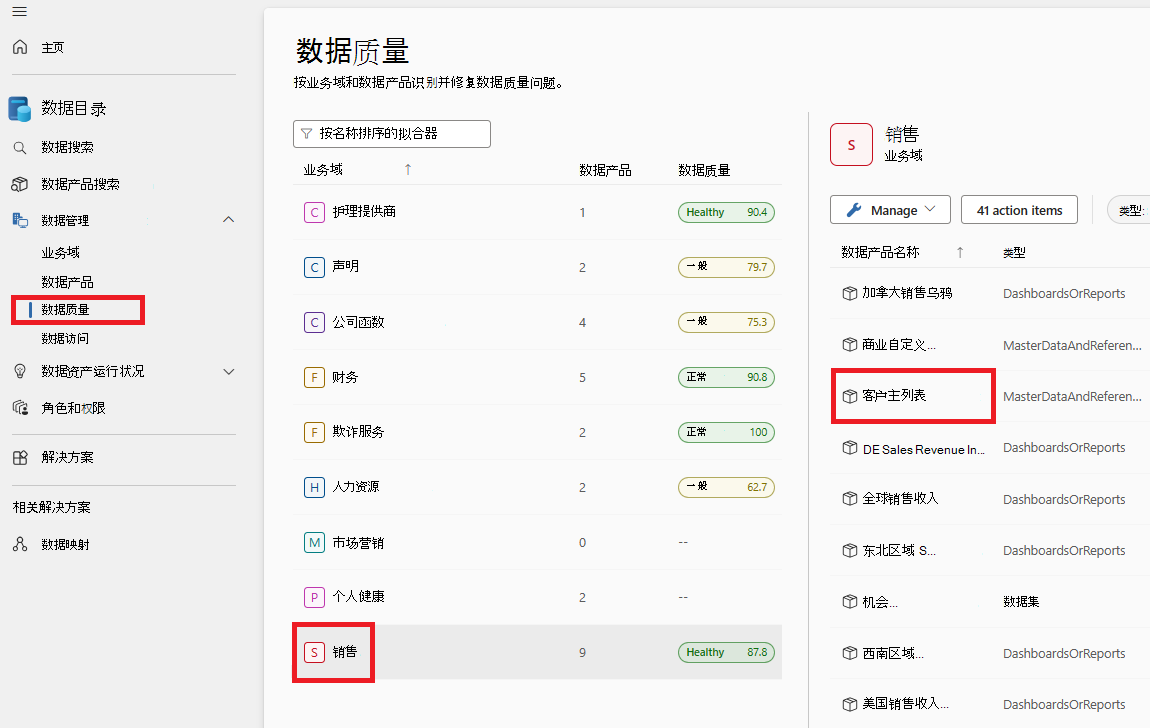
从所选 数据产品 的资产列表中选择数据资产。
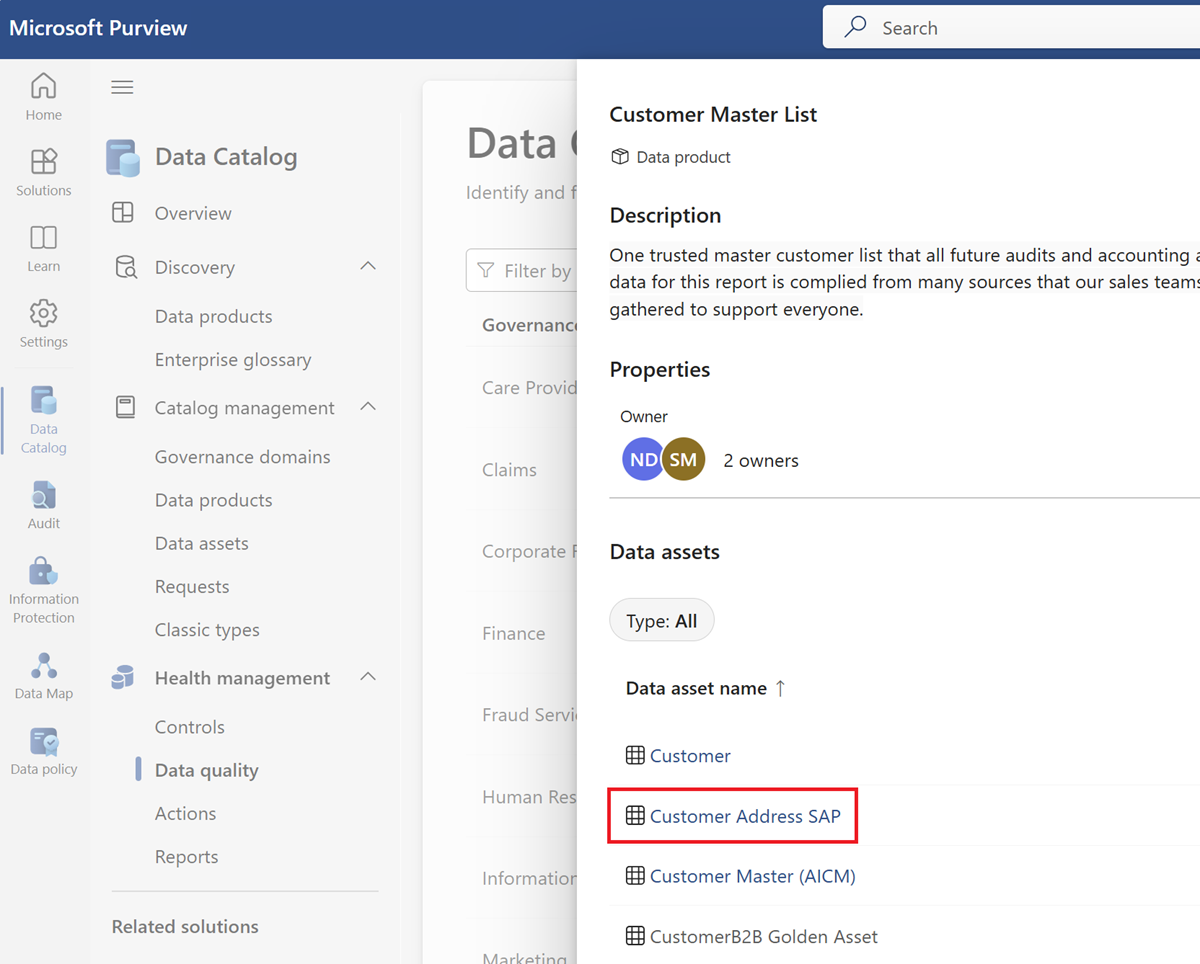
选择“ 规则 ”菜单选项卡,查看应用于资产的现有规则。
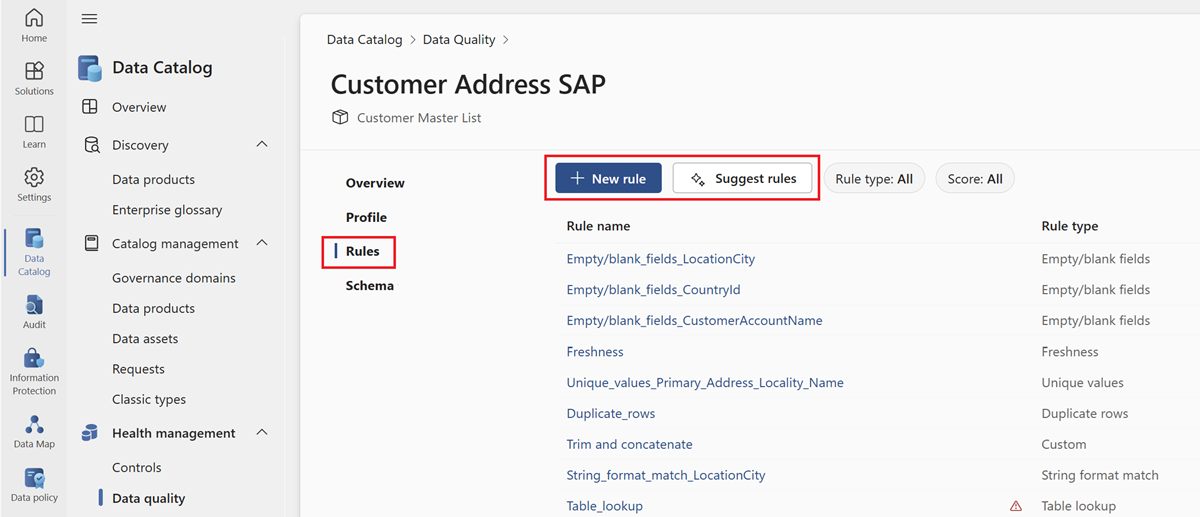
选择一个规则,将应用的规则的性能历史记录浏览到所选数据资产。





可用的数据质量规则
Microsoft Purview 数据质量启用以下规则的配置,这些规则提供低代码到无代码方式来衡量数据质量的现用规则。
| Rule | 定义 |
|---|---|
| 新鲜度 | 确认所有值都是最新的。 |
| 唯一值 | 确认列中的值是唯一的。 |
| 字符串格式匹配 | 确认列中的值是否与特定格式或其他条件匹配。 |
| 数据类型匹配 | 确认列中的值符合其数据类型要求。 |
| 重复行 | 检查在两列或更多列中具有相同值的重复行。 |
| 空/空白字段 | 在应存在值的列中查找空白和空字段。 |
| 表查找 | 确认可以在另一个表的特定列中找到一个表中的值。 |
| 自定义 | 使用视觉表达式生成器创建自定义规则。 |
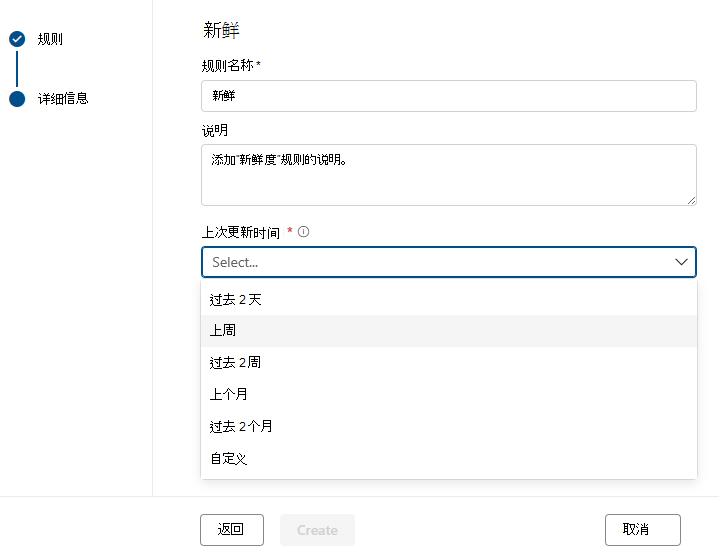
新鲜度
新鲜度规则的目的是确定资产是否已在预期时间内更新。 Microsoft Purview 当前支持通过查看 上次修改日期来检查新鲜度。
注意
新鲜度规则的分数为 100, (它通过) 或 0 (失败) 。
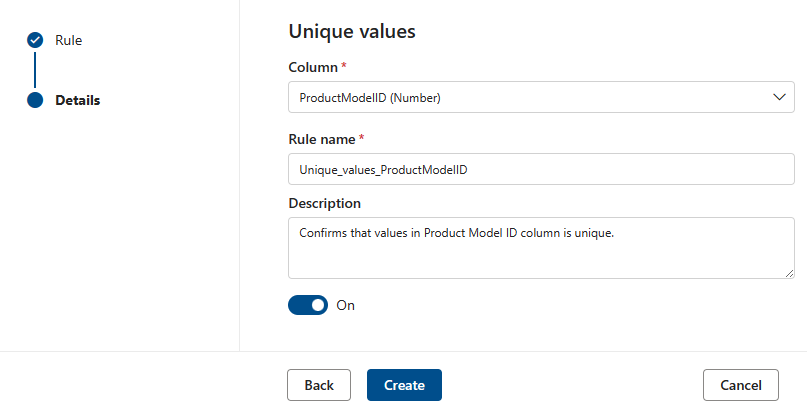
唯一值
“唯一值”规则指出指定列中的所有值都必须是唯一的。 唯一“传递”的所有值和不被视为失败的值。 如果未对列定义空/空字段规则,则出于此规则的目的,将忽略 null/空值。
字符串格式匹配
格式匹配规则检查列中的所有值是否有效。 如果未对列定义空/空字段规则,则出于此规则的目的,将忽略 null/空值。
此规则可以使用三种不同的方法验证列中的每个值:
枚举 – 这是以逗号分隔的值列表。 如果计算的值无法与列出的值之一进行比较,则无法检查。 可以使用反斜杠对逗号和反斜杠进行转义:
\。 因此a \, b, c,包含两个值,第一个是a , b,第二个是c。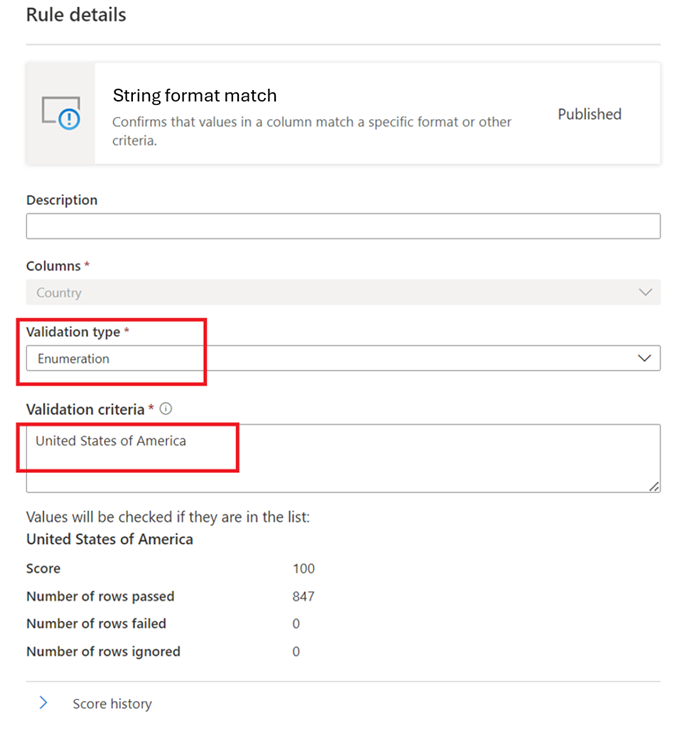
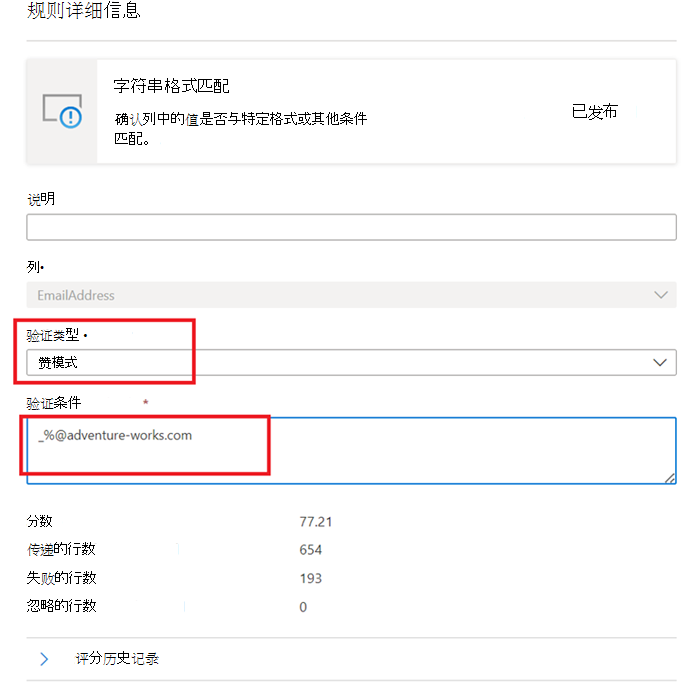
赞模式 -
like(<string> : string, <pattern match> : string) => boolean
模式是按字面意思匹配的字符串。 以下特殊符号除外:_ 匹配输入 (中的任何一个字符,类似于 。中的posix正则表达式) % 匹配输入 (中的零个或多个字符,类似于正则表达式) 中的posix.*。 转义字符为“”。 如果转义字符位于特殊符号或其他转义字符之前,则以下字符按字面意思进行匹配。 转义任何其他字符都无效。like('icecream', 'ice%') -> true
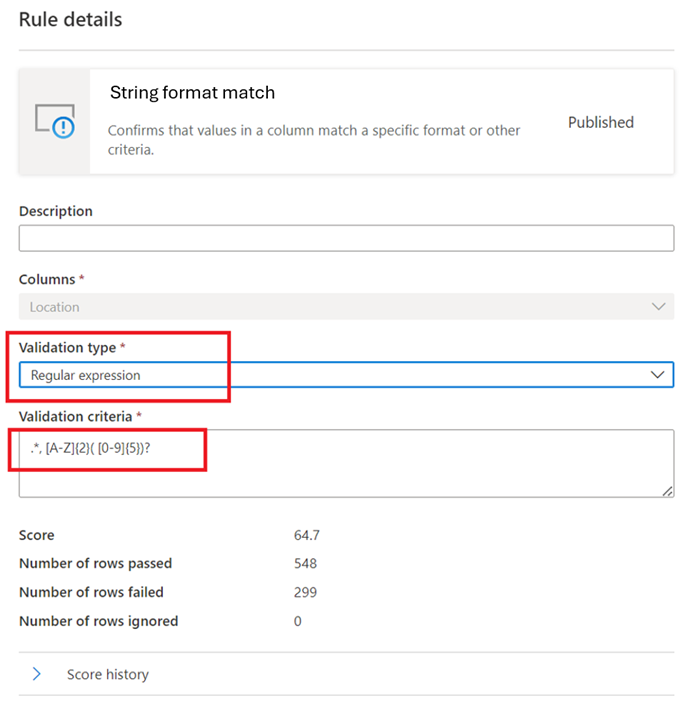
正则表达式 –
regexMatch(<string> : string, <regex to match> : string) => boolean
检查字符串是否与给定正则表达式模式匹配。 使用<regex>(后引号) 匹配字符串而不转义。regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true
数据类型匹配
数据类型匹配规则指定关联列应包含的数据类型。 由于规则引擎必须跨许多不同的数据源运行,因此它无法使用 BIGINT 或 VARCHAR 等本机类型。 相反,它有自己的类型系统,它将本机类型转换为 。 此规则告知质量扫描引擎本机类型应转换为的内置类型。 数据类型系统取自 Azure 数据工厂 中使用的 Azure 数据流 类型系统。
在质量扫描期间,将针对数据类型匹配类型测试本机类型,如果无法将本机类型转换为数据类型匹配类型,则将该行视为错误。
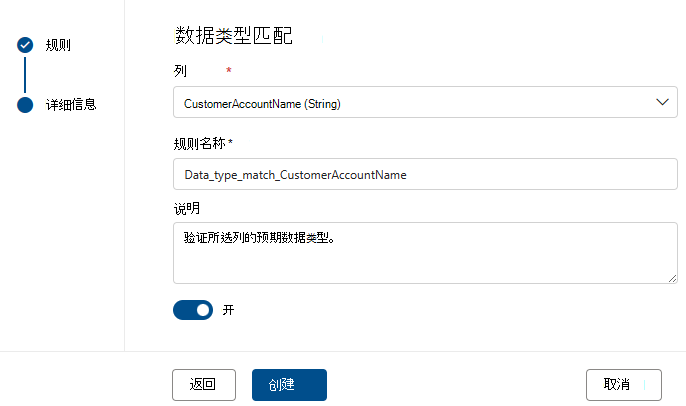
重复行
“重复行”规则检查列中值的组合对于表中的每一行是否唯一。
在下面的示例中,预期_CompanyName、CustomerID、EmailAddress、FirstName 和 LastName 的串联将生成对表中所有行唯一的值。
每个资产可以具有此规则的零个或一个实例。
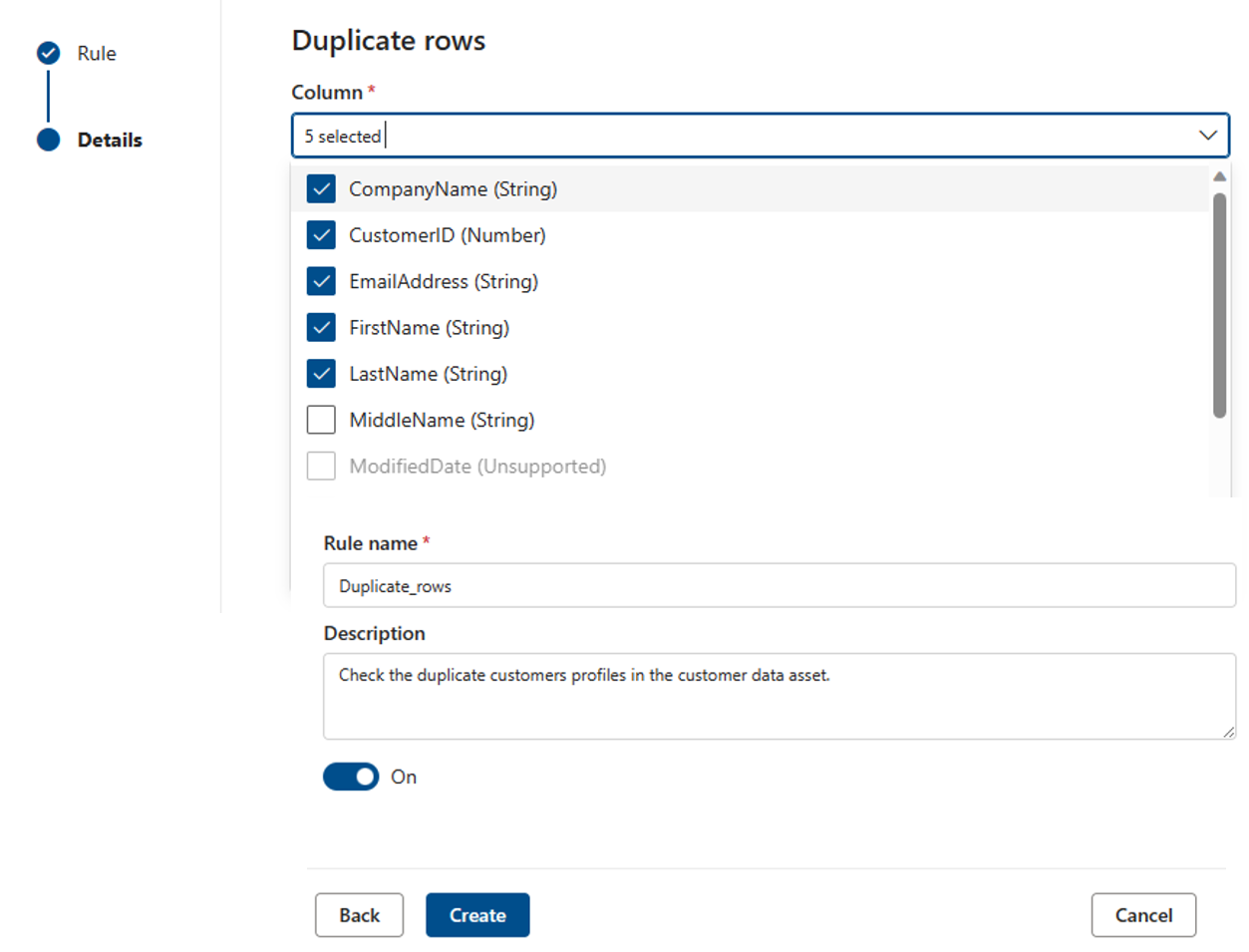
空/空白字段
空/空字段规则断言,标识的列不应包含任何 null 值,在字符串的特定情况下,也不应包含空值或仅空格值。 在质量扫描期间,此列中不为 null 的任何值都将被视为正确。 此规则会影响其他规则,例如 “唯一值” 或 “格式”匹配 规则。 如果未在列上定义此规则,则在该列上运行时,这些规则将自动忽略任何 null 值。 如果此规则是在列上定义的,则这些规则将检查该列的 null/空值,并考虑它们进行评分。
表查找
表查找规则将检查定义规则的列中的每个值,并将其与引用表进行比较。 例如,主表有一个名为“location”的列,其中包含“city, state zip”形式的城市、州和邮政编码。 有一个名为 citystate 的引用表,其中包含美国支持的城市、州和邮政编码的所有法定组合。 目标是将当前列中的所有位置与该引用列表进行比较,以确保仅使用合法组合。
为此,我们首先在搜索资产对话框中键入“citystatezip 的名称”。 然后,选择所需的资产,然后选择要与之进行比较的列。
自定义规则
自定义规则允许指定尝试基于该行中的一个或多个值验证行的规则。 自定义规则包含两个部分:
- 第一部分是筛选器表达式,它是可选的,通过选择“使用筛选器表达式”来激活检查框。 这是一个返回布尔值的表达式。 筛选器表达式将应用于一行,如果返回 true,则将该行视为规则。 如果筛选表达式为该行返回 false,则表示将出于此规则的目的忽略该行。 筛选器表达式的默认行为是传递所有行 , 因此如果未指定筛选器表达式,并且不需要一个,则将考虑所有行。
- 第二部分是 行表达式。 这是应用于每个行的布尔表达式,该行得到筛选器表达式的批准。 如果此表达式返回 true,则行传递;如果为 false,则将其标记为失败。

自定义规则示例
| 应用场景 | 行表达式 |
|---|---|
| 验证 state_id 是否等于加州,以及 aba_Routing_Number 是否与特定正则表达式模式匹配,并且出生日期是否位于特定范围内 | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| 验证 VendorID 是否等于 124 | {VendorID}=='124' |
| 检查 fare_amount 是否等于或大于 100 | {fare_amount} >= "100" |
| 验证 fare_amount 是否大于 100 且 tolls_amount 是否不等于 100 | {fare_amount} >= "100" || {tolls_amount} != "400" |
| 检查 评分 是否小于 5 | Rating < 5 |
| 验证 一年中 的数字数是否为 4 | length(toString(year)) == 4 |
| 如果两列 bbToLoanRatio 和 bankBalance 的值相等,则将其与检查进行比较 | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| 检查 firstName、 lastName、 LoanID、 uuid 中剪裁和串联的字符数是否大于 20 | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| 验证aba_Routing_Number是否与特定的正则表达式模式匹配,并且初始交易日期是否大于 2022-11-12,Disallow-Listed 为 false,以及平均 bankBalance 大于 50000,并且state_id等于“Massachuse”、“田纳西”、“北达科他州”或“Albama” | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachuse' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Albama') |
| 验证 aba_Routing_Number 是否与某些正则表达式模式匹配,并且 dateOfBirth 是否介于 1968-12-13 和 2020-12-13 之间 | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| 检查 aba_Routing_Number 中的唯一值数是否等于 1,000,000, 并且EMAIL_ADDR 中的唯一值数是否等于 1,000,000 | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
筛选器表达式和行表达式都是使用此处介绍的Azure 数据工厂表达式语言和此处定义的语言定义的。 但请注意,并非所有为通用 ADF 表达式语言定义的函数都可用。 可用函数的完整列表位于表达式对话框中提供的“函数”列表中。 不支持 此处 定义的以下函数:isDelete、isError、isIgnore、isInsert、isMatch、isUpdate、isUpsert、partitionId、cached lookup 和 Window 函数。
AI 辅助自动生成的规则
用于数据质量测量的 AI 辅助自动规则生成涉及使用人工智能 (AI) 技术自动创建规则来评估和提高数据质量。 自动生成的规则特定于内容。 大多数常见规则将自动生成,因此用户无需花费太多精力来创建自定义规则。
浏览并应用自动生成的规则:
- 在 “规则 ”页上选择“建议规则”。
- 浏览建议的规则列表。

- 从建议的规则列表中选择要应用于数据资产的规则。

后续步骤
- 在数据产品上配置并运行数据质量扫描 ,以评估数据产品中所有受支持资产的质量。
- 查看扫描结果 以评估数据产品的当前数据质量。