特征哈希
重要
对机器学习工作室(经典)的支持将于 2024 年 8 月 31 日结束。 建议在该日期之前转换到 Azure 机器学习。
从 2021 年 12 月 1 日开始,你将无法创建新的机器学习工作室(经典)资源。 在 2024 年 8 月 31 日之前,可继续使用现有的机器学习工作室(经典)资源。
ML 工作室(经典)文档即将停用,将来可能不会更新。
使用 Vowpal Wabbit 库将文本数据转换为整数编码特征
类别:文本分析
模块概述
本文介绍如何在 机器学习 Studio 中使用特征哈希模块 (经典) ,将英语文本流转换为一组表示为整数的特征。 然后,可以将此哈希特征集传递给机器学习算法来训练文本分析模型。
本模块中提供的功能哈希功能基于 Vowpal Wabbit 框架。 有关详细信息,请参阅 训练 Vowpal Wabbit 7-4 模型 或 训练 Vowpal Wabbit 7-10 模型。
有关功能哈希的详细信息
特征哈希处理的工作原理是将唯一的标记转换为整数。 此功能针对作为输入提供的确切字符串运行,但不会执行任何语言分析或预处理。
例如,采用下面所示的一组简单句子,后接一个情绪评分。 假设你要使用此文本来生成模型。
| USERTEXT | SENTIMENT |
|---|---|
| I loved this book | 3 |
| I hated this book | 1 |
| This book was great | 3 |
| I love books | 2 |
在内部, 特征哈希 模块将创建 n 元语法字典。 例如,此数据集的双元语法列表如下所示:
| TERM (bigrams) | 频率 |
|---|---|
| This book | 3 |
| I loved | 1 |
| I hated | 1 |
| I love | 1 |
可以使用 N 元语法属性来控制 n 元语法的大小。 如果选择双元语法,则也会计算单元语法。 因此,字典还将包括如下单一术语:
| 字词(单元语法) | 频率 |
|---|---|
| book | 3 |
| I | 3 |
| books | 1 |
| was | 1 |
生成字典后, 特征哈希 模块会将字典术语转换为哈希值,并计算是否在每个情况下使用特征。 对于每个文本数据行,该模块将输出一组列,每列对应于哈希处理的每个特征。
例如,在哈希处理后,特征列可能如下所示:
| Rating | 哈希特征 1 | 哈希特征 2 | 哈希特征 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- 如果列中的值为 0,则行不包含哈希特征。
- 如果值为 1,则行包含该特征。
使用特征哈希的优点是,可以将可变长度的文本文档表示为相等长度的数字特征向量,并实现降维。 相比之下,如果尝试按原样使用文本列进行训练,它将被视为分类特征列,其中包含许多不同的值。
另外,使用数字形式的输出时,可以对数据使用许多不同的计算机学习方法(包括分类、聚类或信息检索)。 由于查找操作可以使用整数哈希而不是字符串比较,因此获取特征权重也快得多。
如何配置功能哈希
在 Studio (经典) 中将 功能哈希 模块添加到试验中。
连接包含要分析的文本的数据集。
对于 目标列,请选择要转换为哈希特征的文本列。
列必须是字符串数据类型,并且必须标记为 功能 列。
如果选择多个文本列作为输入,它可以对特征维度产生巨大影响。 例如,如果一个 10 位哈希用于单个文本列,则输出包含 1024 列。 如果 10 位哈希用于两个文本列,则输出包含 2048 列。
注意
默认情况下,Studio (经典) 将大多数文本列标记为功能,因此,如果选择所有文本列,可能会获得太多列,包括许多实际上不是自由文本的列。 使用“编辑元数据”中的“清除”功能选项阻止其他文本列进行哈希处理。
使用 哈希位化 指定创建哈希表时要使用的位数。
默认的位大小为 10。 对于许多问题,此值是否足够,但数据是否足够取决于训练文本中 n 元词汇的大小。 使用较大的词汇,可能需要更多空间以避免碰撞。
建议尝试对此参数使用不同的位数,并评估机器学习解决方案的性能。
对于 N 元语法,请键入一个数字,该数字定义要添加到训练字典中的 n 元语法的最大长度。 n 元语法是 n 个单词的序列,被视为唯一的单位。
N 元语法 = 1:Unigram 或单个单词。
N 元语法 = 2:Bigrams 或双字序列,加上单元语法。
N 元语法 = 3:三元语法或三个单词序列,加上大文和 unigram。
运行试验。
结果
处理完成后,模块将输出转换后的数据集,其中原始文本列已转换为多个列,每个列表示文本中的特征。 根据字典的大小,生成的数据集可能非常大:
| 列名 1 | 列类型 2 |
|---|---|
| USERTEXT | 原始数据列 |
| SENTIMENT | 原始数据列 |
| USERTEXT - 哈希特征 1 | 已哈希处理的特征列 |
| USERTEXT - 哈希特征 2 | 已哈希处理的特征列 |
| USERTEXT - 哈希特征 n | 已哈希处理的特征列 |
| USERTEXT - 哈希特征 1024 | 已哈希处理的特征列 |
创建转换后的数据集后,可以将它用作 训练模型 模块的输入,以及良好的分类模型,例如 双类支持向量机。
最佳实践
下图演示了在建模文本数据时可以使用的一些最佳做法,表示试验
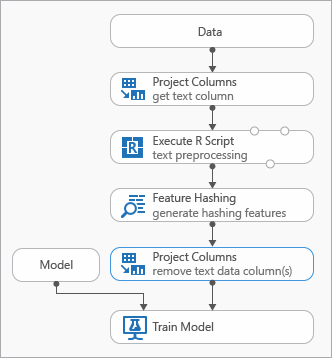
在使用“特征哈希”之前,你可能需要添加“执行 R 脚本”模块,以便预处理输入文本。 使用 R 脚本,还可以灵活地使用自定义词汇或自定义转换。
应在功能哈希模块之后在数据集中添加“选择列”模块,以从输出数据集中删除文本列。 生成哈希功能后,不需要文本列。
或者,可以使用 “编辑元数据” 模块从文本列中清除功能属性。
另请考虑使用这些文本预处理选项来简化结果并提高准确性:
- 断字
- 停止字删除
- case normalization
- 删除标点符号和特殊字符
- 堵塞。
在任何单个解决方案中应用的最佳预处理方法集取决于域、词汇和业务需求。 我们建议你尝试使用数据来查看哪些自定义文本处理方法最有效。
示例
有关功能哈希如何用于文本分析的示例,请参阅 Azure AI 库:
技术说明
本部分包含实现详情、使用技巧和常见问题解答。
提示
除了使用特征哈希之外,你可能还希望使用其他方法从文本中提取特征。 例如:
- 使用 预处理文本 模块删除拼写错误等项目,或简化文本准备哈希处理。
- 使用 提取关键短语 使用自然语言处理来提取短语。
- 使用 命名实体识别 标识重要实体。
机器学习 Studio (经典) 提供了一个文本分类模板,指导你使用特征哈希模块进行特征提取。
实现详细信息
功能哈希模块使用名为 Vowpal Wabbit 的快速机器学习框架,该框架使用名为 murmurhash3 的常用开放源代码哈希函数将特征词哈希转换为内存中索引。 此哈希函数是一种非加密的哈希算法,将映射为整数,文本输入并之所以流行是因为它采用键将随机分布很好地执行。 与加密哈希函数不同,攻击者可以轻松反转它,以便它不适合加密目的。
哈希算法的目的是将可变长度文本文档转换为相等长度数字特征向量,以支持维数缩减,并使特征权重更快的查找。
每个哈希特征表示一个或多个 n 元语法文本特征, (unigram 或单个单词、双克、三元语法等) ,具体取决于表示为 k) 的 (位数以及指定为参数的 n 元克数。 它使用 murmurhash v3 (32 位仅) 算法将功能名称投影到计算机体系结构无符号单词,然后用 2^k) -1 (2^k) -1 进行 AND 处理。 也就是说,哈希值投影到第一 k 个低阶位,其余位则为零。如果指定的位数为 14,则哈希表可以包含 2个 14-1 (或 16,383 个) 项。
对于许多问题,默认哈希表 (位大小 = 10) 已足够:但是,根据训练文本中 n 元语法词汇的大小,可能需要更多空间以避免碰撞。 建议尝试对 哈希位化 参数使用不同的位数,并评估机器学习解决方案的性能。
预期输入
| 名称 | 类型 | 说明 |
|---|---|---|
| 数据集 | 数据表 | 输入数据集 |
模块参数
| 名称 | 范围 | 类型 | 默认 | 说明 |
|---|---|---|---|---|
| 目标列 | Any | ColumnSelection | StringFeature | 选择要应用哈希的列。 |
| 哈希位大小 | [1;31] | Integer | 10 | 键入哈希处理选定列时要使用的位数 |
| N 元语法 | [0;10] | Integer | 2 | 指定哈希过程中生成的 N 元语法数。 默认情况下,将提取单元语法和双元语法 |
Outputs
| 名称 | 类型 | 说明 |
|---|---|---|
| 转换后的数据集 | 数据表 | 包含已哈希处理列的输出数据集 |
例外
| 异常 | 描述 |
|---|---|
| 错误 0001 | 如果找不到数据集的一个或多个指定列,将出现异常。 |
| 错误 0003 | 如果一个或多个输入为 NULL 或为空,将出现异常。 |
| 错误 0004 | 如果参数小于或等于特定值,将出现异常。 |
| 错误 0017 | 如果一个或多个指定列具有当前模块不支持的类型,则会发生异常。 |
有关特定于 Studio (经典) 模块的错误列表,请参阅机器学习错误代码。
有关 API 异常的列表,请参阅机器学习 REST API 错误代码。