TripPin 第 6 部分 - 架构
本教程分为多个部分,介绍如何针对 Power Query 创建新数据源扩展。 本教程按顺序进行,每一课都建立在前几课创建的连接器的基础上,逐步为连接器添加新功能。
在本课中,你将:
- 为 REST API 定义固定架构
- 动态设置列的数据类型
- 强制实施表结构,避免因缺少列而导致转换错误
- 隐藏结果集中的列
与标准 REST API 相比,OData 服务的一大优势是其 $metadata 定义。 $metadata文档描述了此服务中的数据,包括其所有实体(表)和字段(列)的架构。 该 OData.Feed 函数使用此架构定义来自动设置数据类型信息,因此最终用户不会获取所有文本和数字字段(如从 Json.Document 中获取),而是获取日期、整数、时间等,从而提供更好的整体用户体验。
很多 REST API 无法以编程方式确定其架构。 在这些情况下,需在连接器中包含架构定义。 在本课中,你将为每个表定义一个简单的硬编码架构,并在从服务读取的数据上强制执行该架构。
注意
此处所述方法应适用于多项 REST 服务。 今后的课程将基于此方法,以递归方式对结构化列(记录、列表、表)强制实施架构,并提供可通过编程从 CSDL 或 JSON 架构文档生成架构表的示例实现。
总之,对连接器返回的数据强制应用架构有多种好处,例如:
- 设置正确的数据类型
- 删除无需向最终用户显示的列(例如内部 ID 或状态信息)
- 通过添加响应中可能缺少的任何列(REST API 表示字段为空的常用方法),确保每页数据具有相同的形状
使用 Table.Schema 查看现有架构
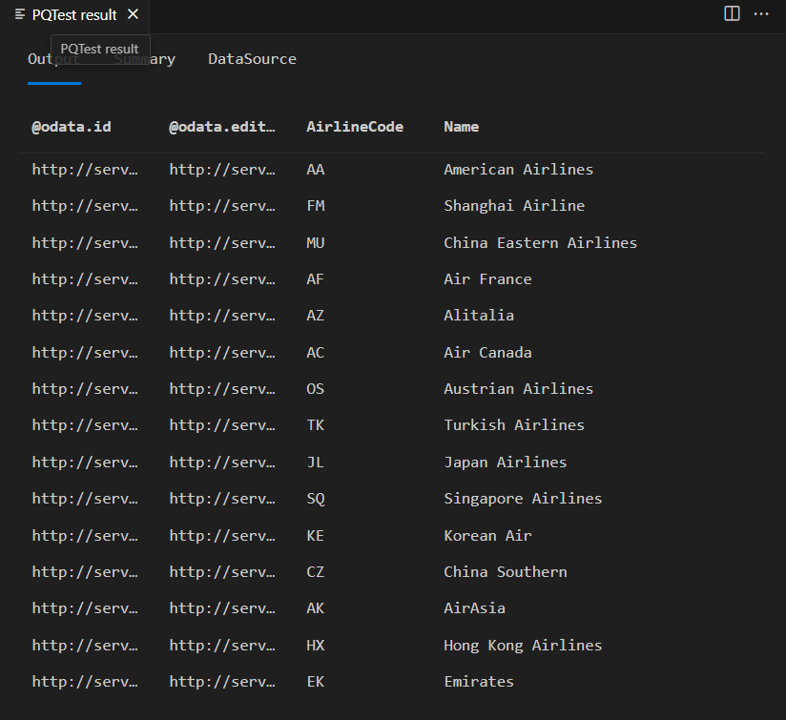
在上一课中创建的连接器显示 TripPin 服务的三个表,Airlines、Airports 以及 People。 运行以下查询查看 Airlines 表:
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
data
在结果中,你将看到返回四列:
- @odata.id
- @odata.editLink
- AirlineCode
- 名称
“@odata.*”列是 OData 协议的一部分,你不希望也不需要向连接器的最终用户显示。 AirlineCode 以及 Name 是你需要保留的两列。 如果查看表的架构(使用方便的 Table.Schema 函数),就会发现表中所有列的数据类型都是 Any.Type。
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
Table.Schema(data)
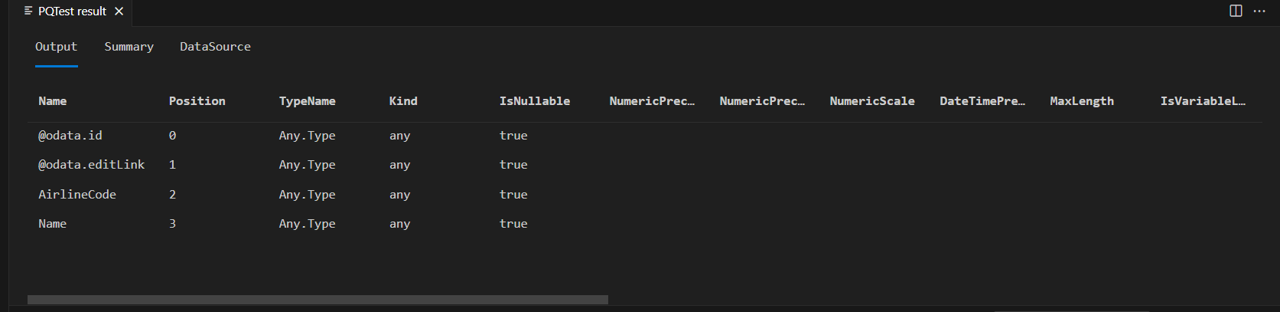
Table.Schema 返回有关表中列的许多元数据,其中包括名称、位置、类型信息和许多高级属性,例如 Precision、Scale 和 MaxLength。
今后的课程将提供设置这些高级属性的设计模式,但现在只需关注归属类型 (TypeName)、基元类型 (Kind) 以及列值是否为 null (IsNullable)。
定义简易架构表
架构表由两列组成:
| 列 | 详细信息 |
|---|---|
| 名称 | 列的名称。 它必须与服务返回结果中的名称匹配。 |
| 类型 | 要设置的 M 数据类型。 可以是基元类型(text、number、datetime等),也可以是归属类型(Int64.Type、Currency.Type等)。 |
Airlines 表的硬编码架构表会将其 AirlineCode 和 Name 列设为 text,如下所示:
Airlines = #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
});
Airports 表有四个要保留的字段(包括一个 record 类型):
Airports = #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
});
最后,该 People 表有七个字段,包括列表(Emails、AddressInfo),可为 null 的列 (Gender) 和一个具有归属类型的列 (Concurrency)。
People = #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})
SchemaTransformTable 帮助程序函数
下文介绍的 SchemaTransformTable 帮助程序函数将用于对数据强制应用架构。 它采用了以下参数:
| 参数 | 类型 | 描述 |
|---|---|---|
| 表 | 表 | 要对其强制应用架构的数据表。 |
| schema | 表 | 要读取列信息的架构表,类型如下:type table [Name = text, Type = type] |
| enforceSchema | 数字 | (可选)控制函数行为的枚举。 默认值 ( EnforceSchema.Strict = 1) 可确保输出表与通过添加所有缺失列和删除额外列而提供的架构表匹配。 EnforceSchema.IgnoreExtraColumns = 2 选项可用于保留结果中的额外列。 使用 EnforceSchema.IgnoreMissingColumns = 3 时,会忽略缺少的列和额外的列。 |
此函数的逻辑如下所示:
- 确定源表中是否存在缺失的列。
- 确定是否存在额外的列。
- 忽略结构化列(
list、record和table类型),并将列设为type any。 - 使用 Table.TransformColumnTypes 设置每个列类型。
- 根据列在架构表中显示的顺序对其重新排序。
- 使用 Value.ReplaceType 设置表本身的类型。
注意
设置表类型的最后一步将消除 Power Query UI 在查询编辑器中查看结果时推断类型信息的需要。 这就消除了在上一教程末尾看到的双重请求问题。
可以将以下帮助程序代码复制并粘贴到扩展中:
EnforceSchema.Strict = 1; // Add any missing columns, remove extra columns, set table type
EnforceSchema.IgnoreExtraColumns = 2; // Add missing columns, do not remove extra columns
EnforceSchema.IgnoreMissingColumns = 3; // Do not add or remove columns
SchemaTransformTable = (table as table, schema as table, optional enforceSchema as number) as table =>
let
// Default to EnforceSchema.Strict
_enforceSchema = if (enforceSchema <> null) then enforceSchema else EnforceSchema.Strict,
// Applies type transforms to a given table
EnforceTypes = (table as table, schema as table) as table =>
let
map = (t) => if Type.Is(t, type list) or Type.Is(t, type record) or t = type any then null else t,
mapped = Table.TransformColumns(schema, {"Type", map}),
omitted = Table.SelectRows(mapped, each [Type] <> null),
existingColumns = Table.ColumnNames(table),
removeMissing = Table.SelectRows(omitted, each List.Contains(existingColumns, [Name])),
primativeTransforms = Table.ToRows(removeMissing),
changedPrimatives = Table.TransformColumnTypes(table, primativeTransforms)
in
changedPrimatives,
// Returns the table type for a given schema
SchemaToTableType = (schema as table) as type =>
let
toList = List.Transform(schema[Type], (t) => [Type=t, Optional=false]),
toRecord = Record.FromList(toList, schema[Name]),
toType = Type.ForRecord(toRecord, false)
in
type table (toType),
// Determine if we have extra/missing columns.
// The enforceSchema parameter determines what we do about them.
schemaNames = schema[Name],
foundNames = Table.ColumnNames(table),
addNames = List.RemoveItems(schemaNames, foundNames),
extraNames = List.RemoveItems(foundNames, schemaNames),
tmp = Text.NewGuid(),
added = Table.AddColumn(table, tmp, each []),
expanded = Table.ExpandRecordColumn(added, tmp, addNames),
result = if List.IsEmpty(addNames) then table else expanded,
fullList =
if (_enforceSchema = EnforceSchema.Strict) then
schemaNames
else if (_enforceSchema = EnforceSchema.IgnoreMissingColumns) then
foundNames
else
schemaNames & extraNames,
// Select the final list of columns.
// These will be ordered according to the schema table.
reordered = Table.SelectColumns(result, fullList, MissingField.Ignore),
enforcedTypes = EnforceTypes(reordered, schema),
withType = if (_enforceSchema = EnforceSchema.Strict) then Value.ReplaceType(enforcedTypes, SchemaToTableType(schema)) else enforcedTypes
in
withType;
更新 TripPin 连接器
现在,你将对连接器进行以下更改,从而使用新的架构强制实施代码。
- 定义包含所有架构定义的主架构表 (
SchemaTable)。 - 更新
TripPin.Feed、GetPage和GetAllPagesByNextLink,以便接受参数schema。 - 在
GetPage中强制实施架构。 - 更新导航表代码,通过调用新函数 (
GetEntity) 对每个表进行封装,这样就可以提升操作表定义时的灵活性。
主架构表
现在,你会将架构定义合并到单个表中,并添加一个帮助程序函数 (GetSchemaForEntity),以便基于实体名称(例如,GetSchemaForEntity("Airlines"))查找定义。
SchemaTable = #table({"Entity", "SchemaTable"}, {
{"Airlines", #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
})},
{"Airports", #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
})},
{"People", #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})}
});
GetSchemaForEntity = (entity as text) as table => try SchemaTable{[Entity=entity]}[SchemaTable] otherwise error "Couldn't find entity: '" & entity &"'";
为数据函数添加架构支持
现在,你将为函数 TripPin.Feed、GetPage 和 GetAllPagesByNextLink添加可选参数 schema。
这样,就可以(在需要时)将架构传递到分页函数,并将其应用于从服务返回的结果中。
TripPin.Feed = (url as text, optional schema as table) as table => ...
GetPage = (url as text, optional schema as table) as table => ...
GetAllPagesByNextLink = (url as text, optional schema as table) as table => ...
你还将更新对这些函数的所有调用,从而确保正确传递架构。
强制实施架构
架构的实际强制实施将在 GetPage 函数中完成。
GetPage = (url as text, optional schema as table) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value]),
// enforce the schema
withSchema = if (schema <> null) then SchemaTransformTable(data, schema) else data
in
withSchema meta [NextLink = nextLink];
注意
此 GetPage 实现使用 Table.FromRecords 将 JSON 响应中的记录列表转换为表。
使用 Table.FromRecords 的主要缺点是,它假定列表中的所有记录都具有相同的字段集。
这适用于 TripPin 服务,因为 OData 记录可以保证包含相同的字段,但并非所有 REST API 都是如此。
更可靠的实现方式是结合使用 Table.FromList 和 Table.ExpandRecordColumn。
后面的教程将更改实现方式,从模式表中获取列列表,确保在从 JSON 到 M 的转换过程中不会丢失或遗漏任何列。
添加 GetEntity 函数
该 GetEntity 函数将封装对 TripPin.Feed 的调用。
它会根据实体名称查找模式定义,并创建完整的请求 URL。
GetEntity = (url as text, entity as text) as table =>
let
fullUrl = Uri.Combine(url, entity),
schemaTable = GetSchemaForEntity(entity),
result = TripPin.Feed(fullUrl, schemaTable)
in
result;
然后,将函数更新 TripPinNavTable 函数以调用 GetEntity,而不是内联进行所有调用。
这样做的主要好处是,你可以继续修改实体生成代码,而无需触及导航表逻辑。
TripPinNavTable = (url as text) as table =>
let
entitiesAsTable = Table.FromList(RootEntities, Splitter.SplitByNothing()),
rename = Table.RenameColumns(entitiesAsTable, {{"Column1", "Name"}}),
// Add Data as a calculated column
withData = Table.AddColumn(rename, "Data", each GetEntity(url, [Name]), type table),
// Add ItemKind and ItemName as fixed text values
withItemKind = Table.AddColumn(withData, "ItemKind", each "Table", type text),
withItemName = Table.AddColumn(withItemKind, "ItemName", each "Table", type text),
// Indicate that the node should not be expandable
withIsLeaf = Table.AddColumn(withItemName, "IsLeaf", each true, type logical),
// Generate the nav table
navTable = Table.ToNavigationTable(withIsLeaf, {"Name"}, "Name", "Data", "ItemKind", "ItemName", "IsLeaf")
in
navTable;
汇总
完成所有代码更改后,编译并重新运行调用“航空公司”表的 Table.Schema 的测试查询。
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
Table.Schema(data)
现在可以看到,“航空公司”表只有在其架构中定义的两列:
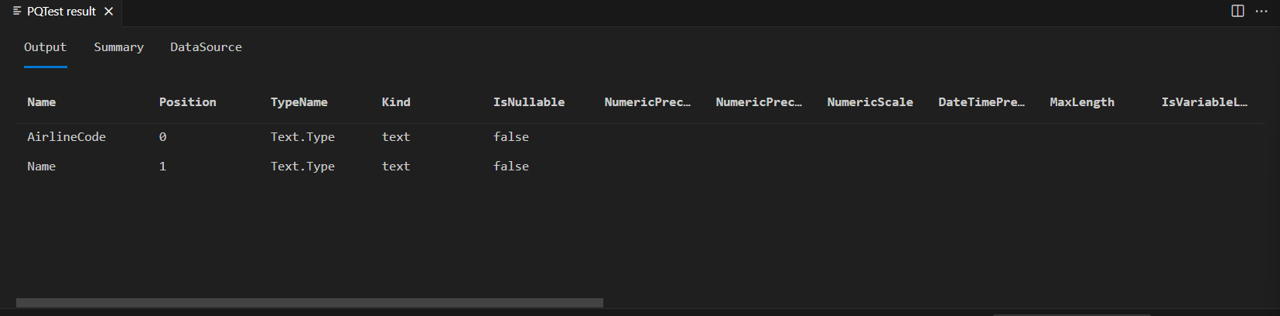
如果针对“人员”表运行相同的代码...
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data]
in
Table.Schema(data)
你会发现所使用的归属类型 (Int64.Type) 也已正确设置。
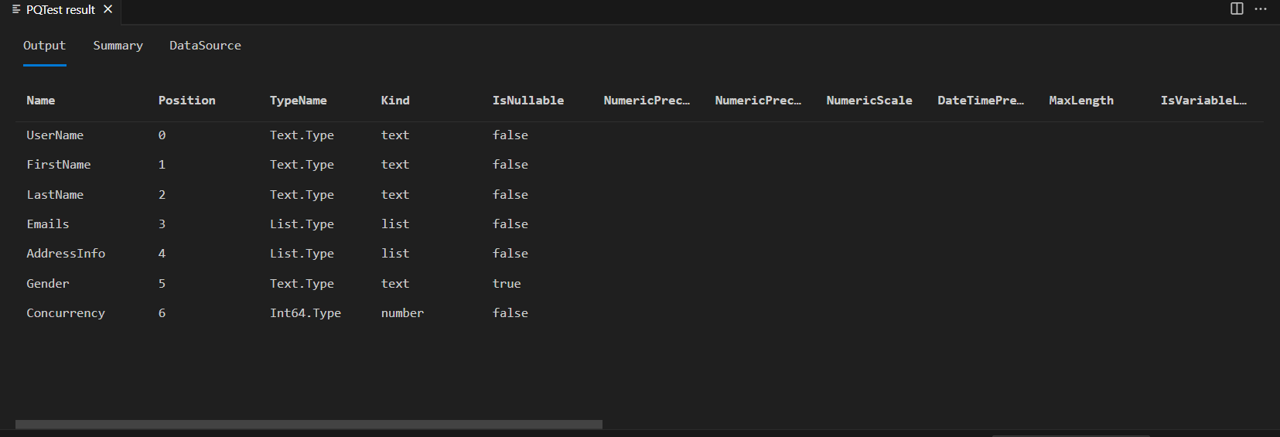
值得注意的是,SchemaTransformTable 的此实现不会修改 list 和 record 列的类型,但 Emails 和 AddressInfo 列仍键入为 list。 这是因为 Json.Document 将 JSON 数组正确映射到 M 列表,并将 JSON 对象映射到 M 记录。 如果要在 Power Query 中展开列表或记录列,就会发现所有展开的列都是“类型任意”。 之后的教程将改进实现,以便递归设置嵌套复杂类型的类型信息。
结束语
本教程提供了对 REST 服务返回的 JSON 数据强制实施架构的示例实现。 虽然此示例使用简单的硬编码架构表格式,但可以通过从其他源(例如 JSON 架构文件或数据源公开的元数据服务/终结点)动态生成架构表定义来扩展该方法。
除了修改列类型(和值),代码还设置表本身的正确类型信息。 在 Power Query 内部运行时,设置此类型信息有利于提高性能,因为用户体验始终会尝试推断类型信息,以便向最终用户显示正确的 UI 队列,推理调用最终可能会触发对基础数据 API 的其他调用。
如果使用上一课中的 TripPin 连接器查看“人员”表,就会发现所有列都有一个“类型任意”图标(即使是包含列表的列):
通过本课程中的 TripPin 连接器运行同一查询,就会发现类型信息已正确显示。