TripPin 第 5 部分 - 分页
本教程分为多个部分,介绍如何针对 Power Query 创建新数据源扩展。 本教程按顺序进行,每一课都建立在前几课创建的连接器的基础上,逐步为连接器添加新功能。
在本课中,你将:
- 向连接器添加分页支持
许多 Rest API 以“页面”形式返回数据,这就要求客户端发出多个请求以便将结果拼接在一起。 尽管分页(如 RFC 5988)存在一些常见约定,但通常会因 API 而异。 值得庆幸的是,TripPin 是 OData 服务,而 OData 标准定义了使用响应正文中返回的 odata.nextLink 值执行分页的方法。
为了简化连接器先前的迭代,TripPin.Feed 函数无法感知页面。 它只是简单地解析从请求返回的任何 JSON,并将其格式化为表。 熟悉 OData 协议的人可能注意到,我们对响应格式做出了许多不正确的假设(例如,假设有一个包含记录数组的 value 字段)。
在本课中,将通过页面感知来改进响应处理逻辑。 今后的教程使页面处理逻辑更加可靠,并且能够处理多种响应格式(包括来自服务的错误)。
注意
使用基于 OData.Feed 的连接器时,无需实现自己的分页逻辑,因为它会自动为你处理这一切。
分页清单
实现分页支持时,你需要了解有关 API 的以下事项:
- 如何请求下一页数据?
- 分页机制是否涉及计算值,还是从响应中提取下一页的 URL?
- 如何知道何时停止分页?
- 是否有与分页相关的参数需要注意? (例如“页面大小”)
这些问题的回答影响你实现分页逻辑的方式。 虽然不同的分页实现中存在一些代码重用(如使用 Table.GenerateByPage),但大多数连接器最终都需要自定义逻辑。
注意
本课程包含 OData 服务的分页逻辑,该逻辑遵循特定格式。 请查阅你的 API 文档,确定连接器中需要进行哪些更改来支持其分页格式。
OData 分页概述
OData 分页由响应有效负载中包含的 nextLink 注释 驱动。 nextLink 值包含指向下一页数据的 URL。 通过查找响应最外层对象的 odata.nextLink 字段,可以知道是否有下一页数据。 如果没有 odata.nextLink 字段,则表示已读取所有数据。
{
"odata.context": "...",
"odata.count": 37,
"value": [
{ },
{ },
{ }
],
"odata.nextLink": "...?$skiptoken=342r89"
}
有些 OData 服务允许客户端提供最大页面大小首选项,但是否遵守该首选项取决于服务。 Power Query 应该能够处理任何大小的响应,因此你无需担心指定页面大小首选项,你可以支持服务引发的任何内容。
有关服务器驱动分页的详细信息,请参阅 OData 规范。
测试 TripPin
在修复分页实现之前,请确认上一教程中扩展的当前行为。 以下测试查询检索“人员”表并添加索引列以显示当前行数。
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data],
withRowCount = Table.AddIndexColumn(data, "Index")
in
withRowCount
打开 Fiddler,然后在 Power Query SDK 中运行查询。 请注意,查询会返回一个包含八行的表(索引 0 到 7)。
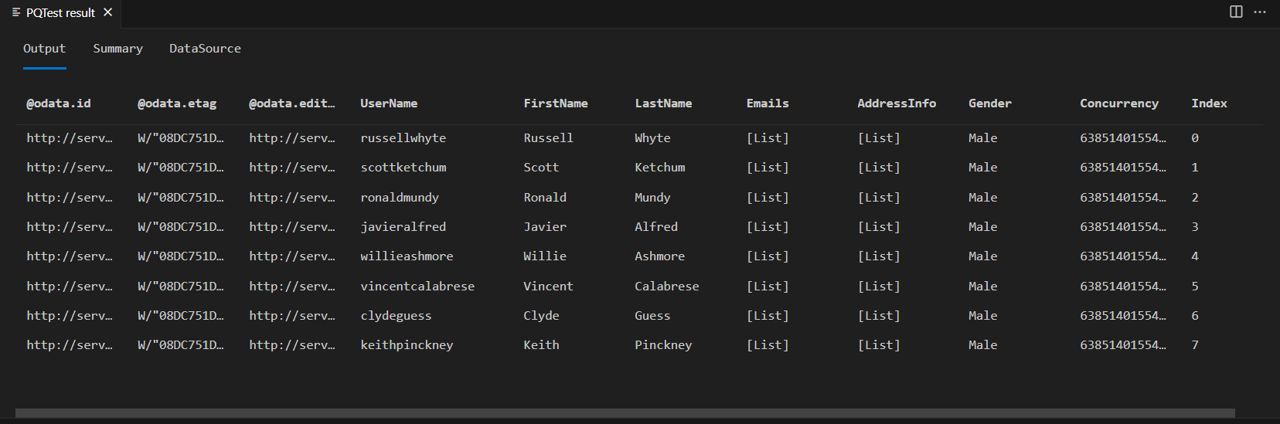
如果查看 Fiddler 的响应正文,就会发现其中确实包含 @odata.nextLink 字段,表明还有更多页的数据可用。
{
"@odata.context": "https://services.odata.org/V4/TripPinService/$metadata#People",
"@odata.nextLink": "https://services.odata.org/v4/TripPinService/People?%24skiptoken=8",
"value": [
{ },
{ },
{ }
]
}
为 TripPin 实现分页
现在,你将对扩展进行如下更改:
- 导入通用函数
Table.GenerateByPage - 添加使用
Table.GenerateByPage将所有页面粘附在一起的GetAllPagesByNextLink函数 - 添加可读取单个数据页的
GetPage函数 - 添加
GetNextLink函数以从响应中提取下一个 URL - 更新
TripPin.Feed以使用新的页面阅读器函数
注意
如本教程前面所述,不同数据源的分页逻辑会有所不同。 此处的实现尝试将逻辑分解为多个函数,这些函数对于使用响应中返回的后续链接的源来说应可重复使用。
Table.GenerateByPage
若要将源返回的(可能)多个页面合并到单个表中,我们将使用 Table.GenerateByPage。 此函数采用 getNextPage 函数作为其参数,该函数应只执行其名称建议的内容:提取下一页的数据。 Table.GenerateByPage 将反复调用 getNextPage 该函数,每次传都会将上次调用使产生的结果传递给它,直到它返回 null 信号,表明没有更多页面可用。
由于此函数不是 Power Query 标准库的一部分,因此需要将其源代码复制到 .pq 文件中。
实现 GetAllPagesByNextLink
GetAllPagesByNextLink 函数的主体实现 Table.GenerateByPage 的函数参数 getNextPage。 它将调用函数 GetPage,并从上一次调用的 meta 记录 NextLink 字段中检索下一页数据 URL。
// Read all pages of data.
// After every page, we check the "NextLink" record on the metadata of the previous request.
// Table.GenerateByPage will keep asking for more pages until we return null.
GetAllPagesByNextLink = (url as text) as table =>
Table.GenerateByPage((previous) =>
let
// if previous is null, then this is our first page of data
nextLink = if (previous = null) then url else Value.Metadata(previous)[NextLink]?,
// if NextLink was set to null by the previous call, we know we have no more data
page = if (nextLink <> null) then GetPage(nextLink) else null
in
page
);
实现 GetPage
函数 GetPage 将使用 Web.Contents 从 TripPin 服务检索单页数据,并将响应转换为表。 它将来自 Web.Contents 的响应传递给 GetNextLink 函数以提取下一页的 URL,并将其设置在返回表(数据页)的 meta 记录上。
该实现是对之前教程中的 TripPin.Feed 调用稍作修改后的版本。
GetPage = (url as text) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value])
in
data meta [NextLink = nextLink];
实现 GetNextLink
函数 GetNextLink 只需检查 @odata.nextLink 字段的响应正文,并返回其值。
// In this implementation, 'response' will be the parsed body of the response after the call to Json.Document.
// Look for the '@odata.nextLink' field and simply return null if it doesn't exist.
GetNextLink = (response) as nullable text => Record.FieldOrDefault(response, "@odata.nextLink");
汇总
实现分页逻辑的最后一步是更新 TripPin.Feed 以使用新函数。 现在,只需调用到 GetAllPagesByNextLink,但在后续教程中,你将添加新功能(例如强制实施架构和查询参数逻辑)。
TripPin.Feed = (url as text) as table => GetAllPagesByNextLink(url);
如果重新运行本教程前面的测试查询,就会看到页面阅读器正在运行。 你还应看到响应中有 24 行,而不是八行。
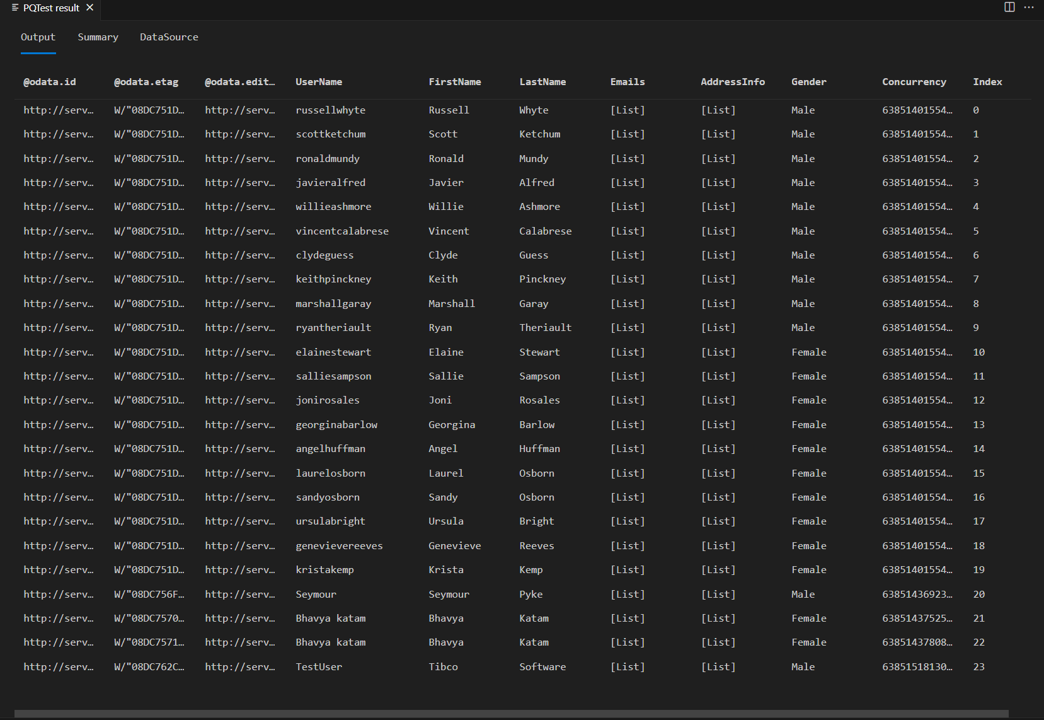
如果查看 Fiddler 中的请求,现在应该可以看到每个数据页面都有单独的请求。
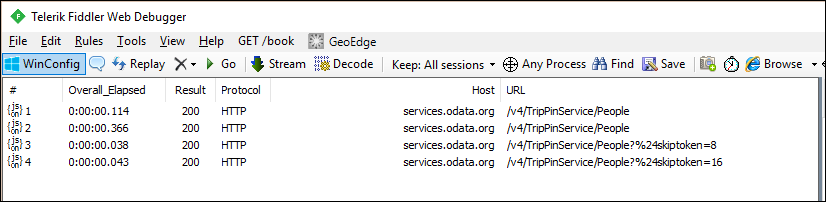
注意
您会注意到对服务第一页数据的重复请求,这并不理想。 额外请求是 M 引擎架构检查行为的结果。 请暂时忽略此问题,并在下一个教程中应用显式模式时再解决它。
结束语
本课程介绍了如何实现对 Rest API 的分页支持。 虽然不同 API 的逻辑可能会有所不同,但此处建立的模式只需稍加修改即可重复使用。
在下一课中,你将了解如何在数据中应用显式架构,而不只是从中 Json.Document 中获取简单的 text 和 number 数据类型。