模糊匹配在 Power Query 中的工作原理
Power Query 功能(如模糊合并、群集值和模糊分组)使用与模糊匹配相同的机制。
本文介绍了许多场景,这些场景演示了如何利用模糊匹配的选项,目的是使“模糊”变得清晰。
调整相似性阈值
应用模糊匹配算法的最佳场景是,列中的所有文本字符串只包含需要比较的字符串,而不包含额外的组件。 例如,对Apples比 4ppl3s 得到的相似分数比对Apples比 My favorite fruit, by far, is Apples. I simply love them!得到的相似分数高。
因为第二个字符串中的单词Apples只是整个文本字符串的一小部分,所以这种比较会产生较低的相似性分数。
例如,下面的数据集来自一个只有一个问题的调查——“您最喜欢的水果是什么?”
| 水果 |
|---|
| 蓝莓 |
| 蓝莓就是最好的 |
| 草莓 |
| 草莓 = <3 |
| 苹果 |
| 'sples |
| 4ppl3s |
| Bananas |
| 最喜欢的水果是香蕉 |
| 香蕉 |
| 到目前为止,我最喜欢的水果是苹果。 我就是爱它们! |
该调查提供了一个单独的文本框来输入值,并且不需要验证。
现在,您的任务是对这些值进行聚类分析。 若要完成该任务,请将前面的水果表加载到 Power Query 中,选择该列,然后在功能区中的添加列选项卡中选择群集值选项。
![]()
此时会显示群集值对话框,可在其中指定新列的名称。 将此新列命名为群集,然后选择确定。

默认情况下,Power Query 使用相似度阈值 0.8(或 80%)。 最小值 0.00 会导致具有任何相似度的所有值相互匹配,最大值 1.00 只允许精确匹配。 模糊“精确匹配”可能会忽略大小写、词序和标点符号等差异。 上一次操作的结果产生了带有新群集列的下表。

虽然已经完成了聚类分析,但它并没有为所有行提供预期结果。 行号二 (2) 仍具有值Blue berries are simply the best,但它应聚集到Blueberries,与文本字符串Strawberries = <3、fav fruit is bananas 和 My favorite fruit, by far, is Apples. I simply love them! 类似。
若要确定导致此聚类分析的原因,请双击已应用的步骤面板中的聚集值,以恢复群集值对话框。 在此对话框中,展开模糊群集选项。 启用显示相似性分数选项,然后选择确定。
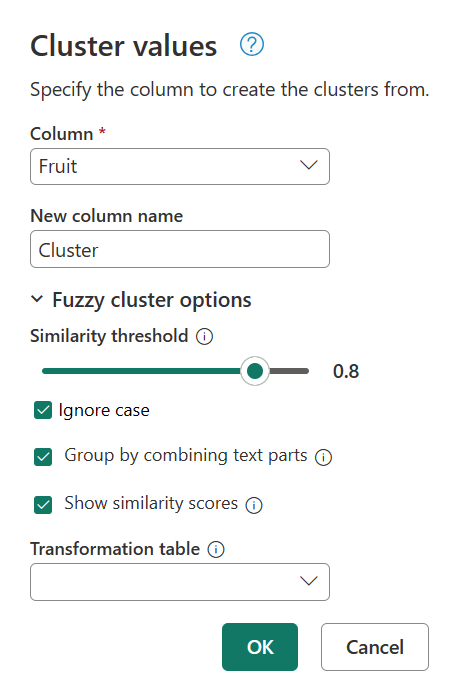
启用显示相似性分数选项会在表中创建新列。 这一列显示了所定义的群集与原始值之间精确的相似性分数。

仔细检查后,Power Query 在文本字符串Blue berries are simply the best、Strawberries = <3和fav fruit is bananasMy favorite fruit, by far, is Apples. I simply love them!的相似性阈值中找不到任何其他值。
在已应用的步骤面板中双击聚集值,返回群集值对话框。 将相似性阈值 从 0.8 更改为 0.6,然后选择确定。
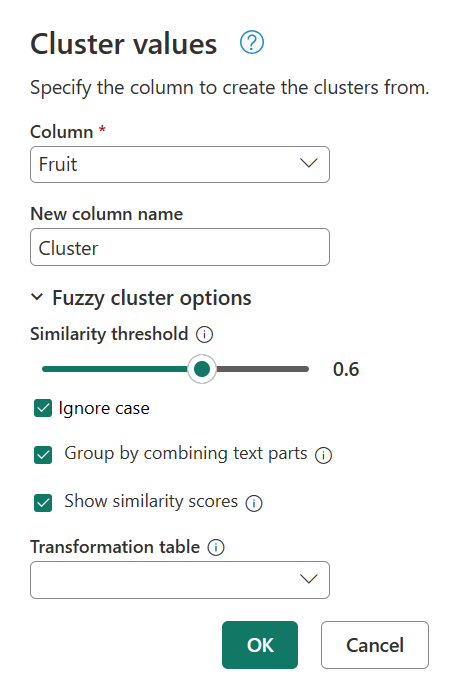
此更改会使您更接近所要查找的结果,但文本字符串My favorite fruit, by far, is Apples. I simply love them!除外。 将相似性阈值的值从 0.8 更改为 0.6 后,Power Query 现在能够使用从 0.6 开始一直到 1 的相似性分数的值。

注意
Power Query 总是使用最接近阈值的值来定义群集。 该阈值定义了可接受的相似性分数的下限,以便将该值分配给群集。
可以通过将相似性分数从 0.6 更改为较低的数字来重试,直到获得要查找的结果。 在本例中,将相似性分数更改为 0.5。 此更改将生成您期望的确切结果,其中文本字符串My favorite fruit, by far, is Apples. I simply love them!现在分配给群集Apples。

注意
目前,只有 Power Query Online 中的群集值功能提供具有相似性分数的新列。
转换表的特殊注意事项
转换表帮助您在执行模糊匹配算法之前将列中的值映射到新值。
关于如何使用转换表的一些示例:
重要
使用转换表时,转换表中值的最大相似性分数为 0.95。 0.05 的故意惩罚是为了区分此类列的原始值与转换发生后的比较值不相等。
对于首先要映射值,然后执行模糊匹配而不执行 0.05 惩罚的场景,我们建议您替换列中的值,然后执行模糊匹配。