群集值
群集值使用模糊匹配算法自动创建具有相似值的组,然后将每列的值映射到最匹配的组。 当处理具有相同值的许多不同变体的数据,并且需要将值合并为一致的组时,此转换非常有用。
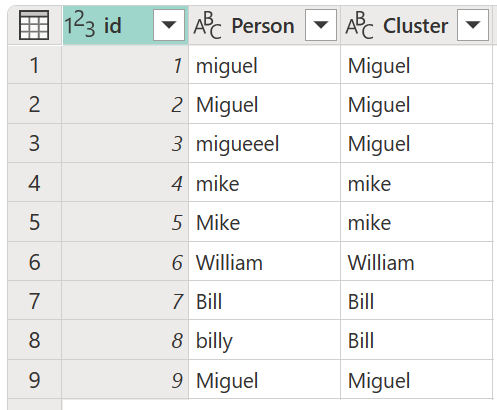
考虑一个包含 ID 列的示例表,其中包含一组 ID、一个原因列,其中包含一组各种拼写和大写版本的名称 Miguel、Mike、William 和 Bill。

在此示例中,要查找的结果是一个表,其中包含一个新列,其中显示了人员列中的正确值组,而不是相同字词的所有不同变体。
注意
群集值功能仅适用于 Power Query Online。
创建群集列
要群集值,请先选择人员列,转到功能区中的添加列选项卡,然后选择群集值选项。
![]()
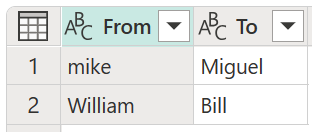
在群集值对话框中,确认要用于从中创建群集的列,然后输入列的新名称。 对于此案例,将此新列命名为群集。

该操作的结果如下图所示。
注意
对于每个值群集,Power Query 将从所选列中选取最频繁的实例作为“规范”实例。 如果多个实例出现的频率相同,Power Query 将选取第一个实例。
使用模糊群集选项
以下选项可用于群集新列中的值:
- 相似性阈值(可选):此选项指示必须将两个值组合在一起的方式。 最小设置零 (0) 将导致将所有值分组在一起。 最大设置 1 仅允许将完全匹配的值分组在一起。 默认值为 0.8。
- 忽略大小写:比较文本字符串时,忽略大小写。 默认情况下该选项处于启用状态。
- 通过组合文本部分进行分组:该算法将尝试合并文本部分(如将 Micro 和 soft 合并为 Microsoft)来对值进行分组。
- 显示相似性分数:显示模糊群集后输入值与计算出的代表值之间的相似性分数。
- 转换表(可选):可以选择一个转换表,该转换表将映射值(如将 MSFT 映射到 Microsoft)以将它们分组在一起。
对于此示例,使用名为我的转换表的新转换表来演示如何映射值。 此转换表有两列:
- 来源:要在表中查找的文本字符串。
- 目标:用于替换来源列中的文本字符串。
重要
转换表具有与上图中显示的相同列和列名称(它们必须命名为“来源”和“目标”),这一点很重要,否则 Power Query 不会将此表识别为转换表,并且不会进行任何转换。
使用之前创建的查询,双击“聚集值”步骤,然后在“群集值”对话框中展开“模糊群集选项”。 在模糊群集选项下,启用显示相似性分数选项。 对于 转换表(可选),选择具有转换表的查询。
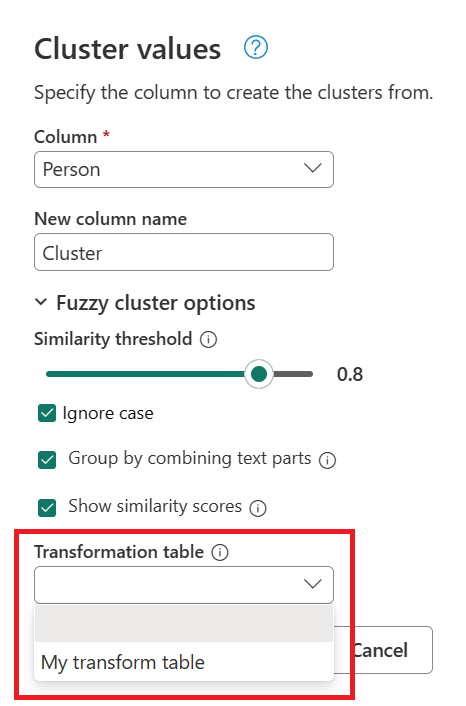
选择转换表并启用显示相似性分数选项后,选择确定。 该操作的结果会提供一个表,其中包含与原始表相同的 id 和“人员”列,但也包括名为“群集”和“Person_Cluster_Similarity”的两个新列。 群集列包含 Miguel 和 Mike 版本的名称 Miguel 的拼写正确大写版本,以及 Bill、Billy 和 William 版本的 William。 Person_Cluster_Similarity 列包含每个名称的相似性分数。

转换表规则
你可能会注意到,上一节中的转换表显示 Mike 的实例已更改为 Miguel,William 的实例已改为 Bill。 然而,在生成的表中,Bill 和“billy”的实例更改为 William。 在转换表中,转换表不是直接的“来源”至“目标”路径,而是在聚类分析过程中对称的,这意味着“mike”等效于“Miguel”,反之亦然。 转换表中给定的等效项的结果取决于下面的规则:
- 如果存在大多数相同的值,则这些值优先于不相同的值。
- 如果没有大多数值,则首先出现的值优先。
例如,在本文中使用的原始表中,“人员”列中的 Miguel 版本(“miguel”和“Miguel”)构成了名称 Miguel 和 Mike 的大多数实例。 此外,带有首字母大写字母的名称 Miguel 占名称 Miguel 的大部分。 因此,在转换表中关联 Miguel 及其派生项与 Mike 及其派生项会导致在“群集”列中使用名称 Miguel。
但是,对于 William、Bill 和“billy”这三个名称,没有大多数值,因为这三个都是唯一的。 由于 William 首先出现,因此“群集”列中使用 William。 如果“billy”首先出现在表中,则“群集”列中将使用“billy“。 此外,由于没有大多数值,因此使用了单个名称使用的大小写。 也就是说,如果 William 是第一个,则使用具有大写“W”的 William 作为结果值;如果“billy”是第一个,则使用具有小写“b”的“billy”。