配置 Power BI Premium 数据流工作负载
可以在 Power BI Premium 订阅中创建数据流工作负载。 Power BI 使用工作负载的概念来描述 Premium 内容。 工作负载包括数据集、分页报表、数据流和 AI。 通过数据流工作负载,可使用数据流自助数据准备功能来引入、转换、集成和扩充数据。 Power BI Premium 数据流在“管理门户”中进行管理。
以下部分介绍如何在组织中启用数据流,如何在高级容量中优化其设置以及常见用法指南。
在 Power BI Premium 中启用数据流
在 Power BI Premium 订阅中使用数据流的第一项要求是支持为你的组织创建和使用数据流。 在“管理门户”中,选择“租户设置”,并将“数据流设置”下的滑块切换到“启用”,如下图所示 。
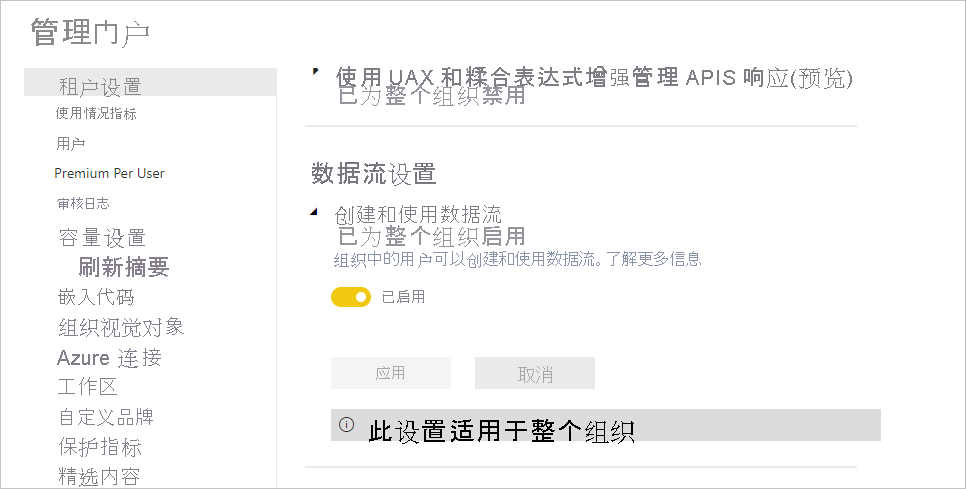
启用数据流工作负载后,会使用默认设置对其进行配置。 你可能想要根据需要调整这些设置。 接下来,我们将介绍这些设置的实时位置、描述每个设置,并帮助你了解何时可能想要更改值以优化数据流性能。
优化 Premium 中的数据流设置
启用数据流后,可以使用“管理门户”来更改或优化数据流的创建方式以及它们在 Power BI Premium 订阅中使用资源的方式。 Power BI Premium 不需要更改内存设置。 Power BI Premium 中的内存会自动管理基础系统。 以下步骤演示如何调整数据流设置。
在管理门户中,选择“租户设置”以列出创建的所有容量。 选择一种容量来管理其设置。
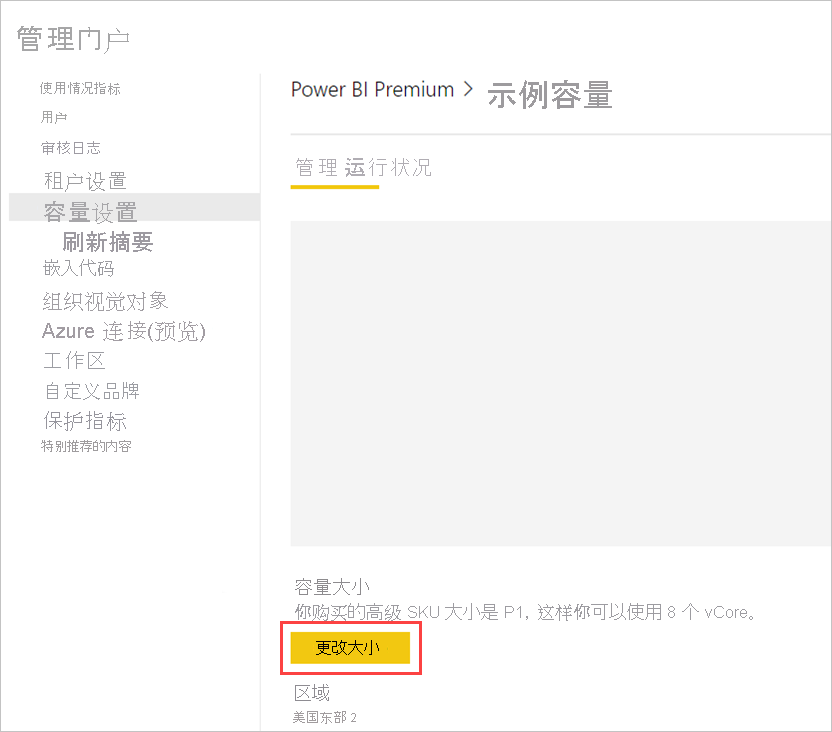
Power BI Premium 容量反映了可用于数据流的资源。 可以通过选择“更改大小”按钮来更改容量大小,如下图所示。
高级容量 SKU - 纵向扩展硬件
Power BI Premium 工作负载使用虚拟核心提供跨各种工作负载类型的快速查询。 容量和 SKU 一文包含一个图表,该图表说明了每个可用工作负载产品/服务的当前规范。 A3 及更高的容量可以利用计算引擎,因此,当你想要使用增强的计算引擎时,请从此处开始。
增强的计算引擎 - 提高性能的机会
增强的计算引擎是可加速查询的引擎。 Power BI 使用计算引擎来处理查询和刷新操作。 增强型计算引擎是对标准引擎的改进,它的工作原理是将数据加载到 SQL 缓存,并使用 SQL 加速表转换、刷新操作并启用 DirectQuery 连接。 将计算实体配置为“启用”或“优化”时(如果业务逻辑允许),Power BI 将使用 SQL 提高性能 。 DirectQuery 连接也可“启用”引擎。 确保数据流使用情况正确使用增强的计算引擎。 用户可以将增强的计算引擎配置为针对每个数据流启用、优化或关闭。
注意
增强的计算引擎尚未在所有区域提供。
常见场景指南
本部分提供有关通过 Power BI Premium 使用数据流工作负载的常见场景的指南。
刷新时间缓慢
刷新时间缓慢通常是一个并行问题。 应按顺序查看以下选项:
刷新时间缓慢的关键概念是数据准备的性质。 只要可以通过利用数据源实际进行准备并执行预先查询逻辑来优化缓慢的刷新时间,就应该这样做。 具体而言,当使用关系数据库(如 SQL)作为源时,请查看是否可以在源上运行初始查询,并将该源查询用于数据源的初始提取数据流。 如果无法在源系统中使用本机查询,请执行数据流 引擎可折叠到数据源的操作。
评估在相同容量下分散刷新时间。 刷新操作是需要大量计算的过程。 对照我们的餐馆类比,分散刷新时间类似于限制餐馆的客人数量。 正如餐馆安排客人并计划容量一样,你还希望在使用未达到完全高峰时考虑刷新操作。 这可能会对缓解容量紧张有很大帮助。
如果本部分中的步骤不能提供所需的并行度,请考虑将容量升级到更高的 SKU。 然后按照此顺序再次执行前面的步骤。
使用计算引擎提高性能
执行以下步骤以使工作负载触发计算引擎,并始终提高性能:
对于同一工作区中的计算实体和链接实体:
对于引入,重点是尽可能快地将数据导入存储,仅当筛选器减小了总体数据集大小时才使用筛选器。 最佳做法是将转换逻辑与此步骤分离,并使引擎能够专注于组成部分的初始收集。 接下来,使用链接实体或计算实体将转换和业务逻辑分离到同一工作区中的单独数据流;这样做可以使引擎激活并加快计算速度。 逻辑需要单独准备,然后才能利用计算引擎。
确保执行折叠的操作,例如合并、联接、转换及其他操作。
在已发布的指导原则和限制内生成数据流。
你还可以使用 DirectQuery。
计算引擎已启用,但性能较低
在调查计算引擎已启用但性能下降的情况时,请执行以下步骤:
限制跨工作区存在的计算和链接实体。
在打开计算引擎时执行初始刷新时,数据将写入 Lake 和缓存中。 这种双重写入意味着刷新速度较慢。
如果你有一个链接到多个数据流的数据流,请确保计划对源数据流的刷新,使其不会同时刷新。
相关内容
以下文章提供有关数据流和 Power BI 的详细信息: