数据流的高级功能
数据流对于 Power BI Pro、Premium Per User (PPU) 和 Power BI Premium 用户是受支持的。 某些功能仅适用于 Power BI Premium 订阅(Premium 容量或 PPU 许可证)。 本文详细介绍了 PPU 和 Premium 专用功能及其用途。
以下功能仅适用于 Power BI Premium(PPU 或 Premium 容量订阅):
- 增强的计算引擎
- DirectQuery
- 计算实体
- 链接实体
- 增量刷新
以下各节详细介绍了这些功能。
重要
本文适用于第一代数据流 (Gen1),不适用于 Microsoft Fabric(预览版)中提供的第二代 (Gen2) 数据流。 有关详细信息,请参阅从第 1 代数据流到第 2 代数据流。
增强的计算引擎
Power BI 中增强的计算引擎使 Power BI Premium 订阅者能够使用其容量优化数据流的使用。 使用增强的计算引擎具有以下优势:
- 大大减少了对计算实体执行长时间运行的 ETL(提取、转换、加载)步骤所需的刷新时间,例如执行“联接”、“去重”、“筛选”和“分组”操作。
- 对实体执行 DirectQuery 查询。
注意
- 验证和刷新过程会通知模型架构的数据流。 若要自行设置表的架构,请使用 Power Query 编辑器并设置数据类型。
- 除 WABI-INDIA-CENTRAL-A-PRIMARY 之外的所有 Power BI 群集上均提供此功能
启用增强的计算引擎
重要
增强的计算引擎仅适用于 A3 及以上的 Power BI 容量。
在 Power BI Premium 中,将为每个数据流单独设置增强的计算引擎。 有三种配置可供选择:
已禁用
优化(默认)- 增强的计算引擎处于“关闭”状态。 当数据流中的表被另一个表引用时,或者当数据流连接到同一工作区中的另一个数据流时,它会自动打开。
开
若要更改默认设置并启用增强的计算引擎,请执行以下步骤:
在工作区中,在要更改设置的数据流旁边,选择“更多选项”。
从数据流的“更多选项”菜单中,选择“设置”。
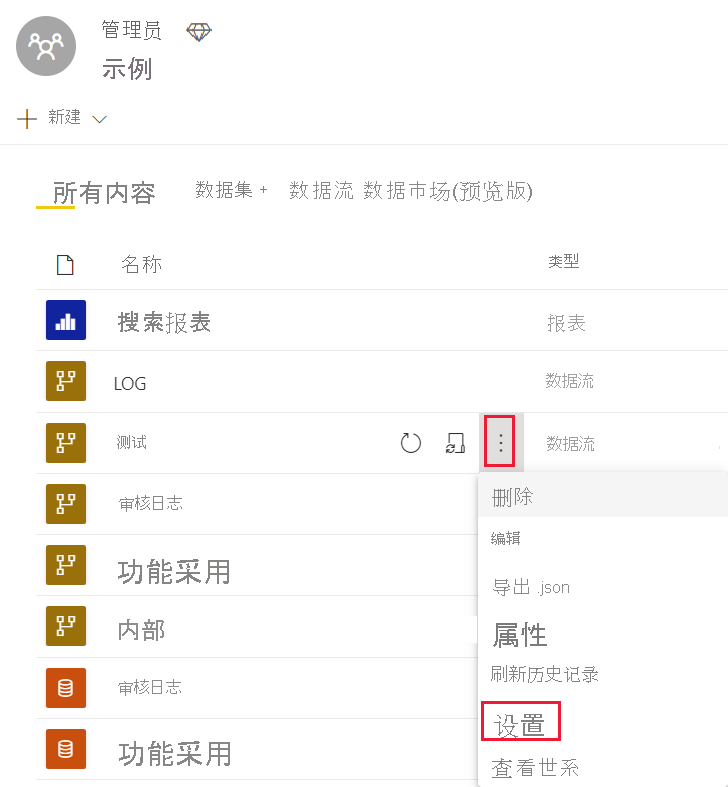
展开“增强的计算引擎设置”。

在“增强的计算引擎设置”中,选择“开”,然后选择“应用”。

使用增强的计算引擎
打开增强的计算引擎后,返回到数据流。你应会看到,任何对基于现有链接实体创建的数据流(容量相同)执行复杂操作(如“联接”或“分组”操作)的计算表的性能都有所提高。
若要充分利用计算引擎,请通过以下方式将 ETL 阶段拆分为同一工作区中的两个单独的数据流:
- 数据流 1 - 此数据流应该只从数据源接收所有必需的数据。
- 数据流 2 - 在第二个数据流中执行所有 ETL 操作,但要确保引用数据流 1 且它应具有相同的容量。 你还要确保先执行可以折叠的操作:筛选、分组、去重、联接。 在执行任何其他操作之前执行这些操作,确保计算引擎得到利用。
常见问题与解答
问: 我启用了增强的计算引擎,但刷新速度较慢。 为什么?
答: 如果你启用了增强的计算引擎,则对于刷新时间缓慢,可能有两种解释:
启用增强的计算引擎后,它需要一些内存才能正常工作。 因此,可用于执行刷新的内存减少,增加了刷新排队的可能性。 这一增加减少了可同时刷新的数据流的数量。 若要解决此问题,在启用增强计算时,请随着时间的推移分散数据流刷新,并评估容量大小是否足够,以确保有内存可用于并发数据流刷新。
导致刷新速度较慢的另一个原因是,计算引擎仅适用于现有实体。 如果数据流引用的数据源不是数据流,则不会出现速度提升。 性能不会得到提升,因为在某些大数据场景中,由于需要将数据传递到增强的计算引擎,因此从数据源进行的初始读取速度会比较慢。
问:我看不到增强的计算引擎的切换开关。 为什么?
答:增强的计算引擎正在分阶段发布到世界各地的区域,但尚未在每个区域提供。
问: 计算引擎支持哪些数据类型?
答: 增强的计算引擎和数据流当前支持以下数据类型。 如果数据流不使用以下数据类型之一,则刷新期间会发生错误:
- 日期/时间
- 十进制数
- 文本
- 整数
- 日期/时间/区域
- True/false
- 日期
- 时间
在 Power BI 中将 DirectQuery 用于数据流
可以使用 DirectQuery 直接连接到数据流,从而能直接连接到自己的数据流,而无需导入其数据。
将 DirectQuery 用于数据流,可以让 Power BI 和数据流过程得到以下增强:
避免单独刷新计划:DirectQuery 直接连接到数据流,无需创建导入的语义模型。 因此,将 DirectQuery 与数据流一起使用意味着不再需要数据流和语义模型的单独刷新计划,就能确保数据已同步。
筛选数据 - DirectQuery 对于处理数据流中经过筛选的数据视图非常有用。 可以使用 DirectQuery 和计算引擎来筛选数据流数据,并处理筛选出的所需子集。 通过筛选数据,可以在数据流中处理较小的且更易于管理的数据子集。
将 DirectQuery 用于数据流
将 DirectQuery 用于数据流在 Power BI Desktop 中可用。
若要将 DirectQuery 用于数据流,需要满足以下先决条件:
- 数据流必须位于已启用 Power BI Premium 的工作区中。
- 必须已打开计算引擎。
若要详细了解如何将 DirectQuery 用于数据流,请参阅将 DirectQuery 用于数据流。
为数据流启用 DirectQuery
为了确保数据流可用于 DirectQuery 访问,增强的计算引擎必须处于最优状态。 若要为数据流启用 DirectQuery,请将新的“增强的计算引擎设置”选项设置为“打开”。

应用该设置后,请刷新数据流以让优化生效。
DirectQuery 的注意事项和限制
DirectQuery 和数据流存在一些已知限制:
目前不支持具有导入和 DirectQuery 数据源的复合/混合模型。
大型数据流在查看可视化效果时可能会遇到超时问题。 遇到超时问题的大型数据流应使用导入模式。
在“数据源设置”下,如果使用 DirectQuery,数据流连接器将显示无效凭据。 此警告不会影响行为,并且语义模型可以正常工作。
当数据流具有 340 个或更多的列时,如果在启用了增强计算引擎设置的情况下在 Power BI Desktop 中使用数据流连接器,那么会禁用数据流的 DirectQuery 选项。 若要在此类配置中使用 DirectQuery,请将列数减少到少于 340。
计算实体
在 Power BI Premium 订阅中使用“数据流”时,可以执行“存储中计算”。 此功能让你能够对现有数据流执行计算,并返回让你能够专注于报表创建和分析的结果。

若要执行“存储中计算”,首先必须创建数据流并将数据导入该 Power BI 数据流存储。 一旦具有包含数据的数据流后,就可以创建“计算实体”,它们是执行存储中计算的实体。
计算实体的注意事项和限制
使用组织的 Azure Data Lake Storage Gen2 帐户中创建的数据流时,仅当链接实体和计算实体位于同一存储帐户中时,这些实体才能正常工作。
计算实体仅在单个工作区中受支持。
最佳做法如下:对由本地数据和云数据联接的数据执行计算时,为每个源创建一个新的数据流(一个用于本地,一个用于云),然后创建第三个数据流来合并/计算这两个数据源。
链接实体
可以通过将链接实体与 Power BI Premium 订阅结合使用来引用同一工作区中的现有数据流,这样就可以使用计算实体对这些实体执行计算,也可以创建可在多个数据流中重复使用的“事实的单一源”表。
增量刷新
可以将数据流设置为增量刷新,以避免每次刷新时都必须提取所有数据。 为此,请选择数据流,然后选择“增量刷新”图标。

设置增量刷新会向数据流添加用于指定日期范围的参数。 有关如何设置增量刷新的详细信息,请参阅将增量刷新与数据流配合使用。
何时不设置增量刷新的注意事项
在以下情况下,请勿将数据流设置为增量刷新:
- 如果链接实体引用数据流,则不应使用增量刷新。
相关内容
以下文章提供有关数据流和 Power BI 的详细信息: