Microsoft Syntex中的模型类型概述
适用于: • 所有自定义模型 |• 所有预生成模型
了解Microsoft Syntex中的内容从文档处理模型开始。 使用文档处理模型可以识别上传到 SharePoint 文档库的文档并对其进行分类,然后从每个文件中提取所需的信息。
应用于 SharePoint 文档库时,模型与内容类型相关联,并且具有用于存储要提取的信息的列。 你创建的内容类型存储在 SharePoint 内容类型库中。 也可以选择使用现有内容类型来使用其架构。
模型可以是在内容中心中创建的企业模型,也可以是在本地 SharePoint 网站上创建的本地模型。
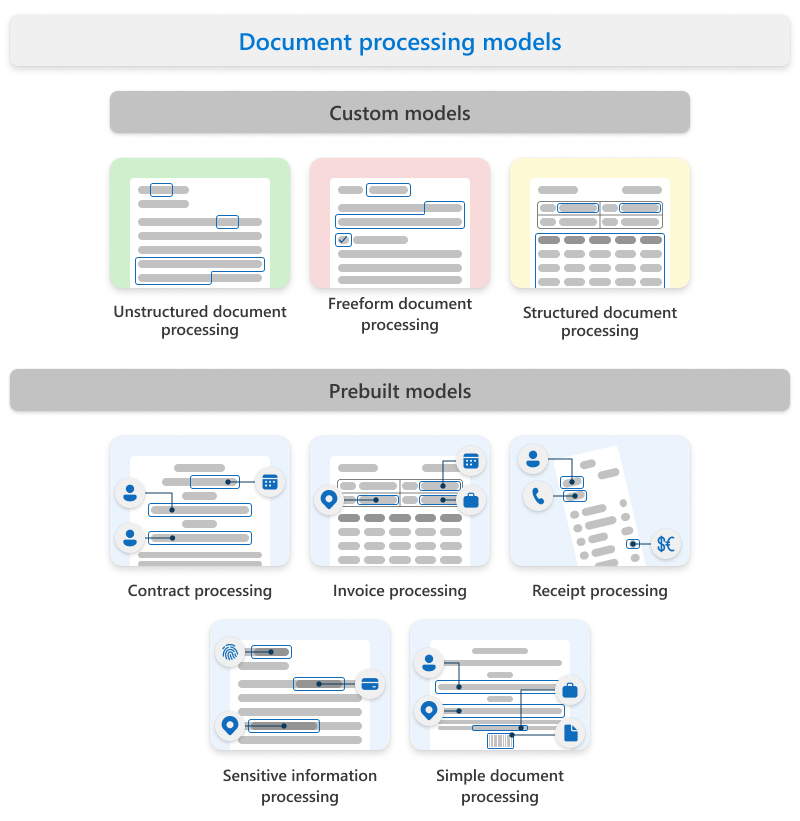
自定义模型
所选的自定义模型类型将取决于所使用的文件类型、文件的格式和结构以及要应用模型的位置。
自定义模型包括:
若要查看自定义模型中的并排差异,请参阅 比较自定义模型。
非结构化文档处理
使用非结构化文档处理模型自动对文档进行分类并从中提取信息。 它最适用于非结构化文档,例如字母或协定。 这些文档必须包含可以根据短语或图案进行识别的文本。 标识的文本将指定文件类型(分类)和要提取的内容(提取程序)。
例如,一个非结构化的文件可以是一份可以用不同的方式来写的续签合同书。 但是,信息始终存在于每个合同续订文档的正文中,例如文本字符串“服务开始日期”,后跟实际日期。
此模型类型支持最广泛的文件类型,并支持 40 多种语言。
创建非结构化文档处理模型时,请使用 “单类模型 ”选项。
有关详细信息,请参阅 非结构化文档处理概述。
任意格式文档处理
使用任意格式文档处理模型可自动从非结构化和任意格式文档(如字母和合同)中提取信息,其中信息可以出现在文档中的任意位置。
任意格式文档处理模型使用 Microsoft Power Apps AI Builder 在 Syntex 中创建和训练模型。
注意
自由格式文档处理模型在某些区域尚不可用。 有关详细信息,请参阅 功能可用性(按区域)。
由于组织从各种来源(如邮件、传真和电子邮件)接收大量信件和文档,因此处理这些文档并手动将其输入数据库可能需要相当长的时间。 通过使用 AI 从这些文档中提取文本和其他信息,此模型可自动执行此过程。
当你不需要自动分类文档类型时,此模型类型是 PDF 或图像文件中文档的最佳选择,它支持 40 多种语言。
创建任意格式文档处理模型时,请使用 任意多边形提取模型 选项。
有关详细信息,请参阅 结构化和自由格式文档处理概述。
结构化文档处理
使用结构化文档处理模型自动标识字段和表值。 它最适合结构化或半结构化文档,例如表单和发票。
结构化文档处理模型使用 Microsoft Power Apps AI Builder 文档处理 (以前称为表单处理) 在 Syntex 中创建和训练模型。
此模型类型支持 最广泛的语言, 并经过训练以从示例文档了解窗体的布局,然后学习如何查找需要从类似位置提取的数据。 Forms通常具有更结构化的布局,其中实体位于同一位置 (例如,税务表上的社会安全号码) 。
创建结构化文档处理模型时,请使用 结构化提取模型 选项。
有关详细信息,请参阅 结构化和自由格式文档处理概述。
预生成模型
如果不需要生成自定义模型,可以使用已针对特定结构化文档进行训练的 预生成文档处理模型 。
预生成模型包括:
预先训练预生成模型以识别文档和文档中的结构化信息。 无需从头开始创建新的自定义模型,可以循环访问现有预先训练的模型,以添加符合组织需求的特定字段。
合同处理
预生成的合同处理模型分析和提取合同文档中的关键信息。 API 以各种格式分析合同,并提取关键合同信息,例如客户或参与方名称、帐单地址、司法管辖区和到期日期。
有关协定处理模型的详细信息,请参阅 使用预生成模型从协定中提取信息。
发票处理
预生成发票处理模型从销售发票中分析和提取关键信息。 API 以各种格式分析发票,并提取关键发票信息,例如客户名称、帐单邮寄地址、截止日期和应付金额。
有关发票处理模型的详细信息,请参阅 使用预生成模型从发票中提取信息。
收据处理
预生成收据处理模型分析和提取销售收据的关键信息。 API 分析打印的收据和手写收据,并提取关键收据信息,例如商家名称、商家电话号码、交易日期、税款和交易总额。
有关收据处理模型的详细信息,请参阅 使用预生成模型从收据中提取信息。
敏感信息处理
预生成的敏感信息处理模型分析、检测和提取文档中的关键信息。 API 以各种格式分析合同,并提取关键敏感信息,例如社会安全号码、财务帐号、驾驶执照标识号和其他个人信息。
有关敏感信息处理模型的详细信息,请参阅 使用预生成模型检测文档中的敏感信息。
简单文档处理
预生成的简单文档处理模型提供了一个灵活的预训练解决方案,用于从基本结构化文档中提取键值对、选择标记和命名实体。 与其他具有固定架构的预生成模型不同,此模型可以识别其他人可能错过的键,从而为自定义模型标记和训练提供有价值的替代方法。 此模型还支持条形码和语言检测。
有关简单文档处理模型的详细信息,请参阅 使用预生成模型检测文档中的敏感信息。