使用预生成模型从Microsoft Syntex中的简单文档中提取信息
简单的文档处理模型提供了一个灵活的预训练解决方案,用于从基本结构化文档中提取信息,包括以下信息:
键值对 - 将其视为标签及其相应信息,例如“名称:Adele Vance”。
选择标记 – 这些是复选框或其他标记,用于指示文档中的选择或选择。
命名实体 – 这些是文档文本中提到的人员、地点或组织名称等特定项。
条形码 – 这些是数据的计算机可读表示形式,可用于在文档中跟踪或标识。
与其他具有固定架构的预生成模型不同,此模型可以识别其他人可能错过的键,从而为自定义模型标记和训练提供有价值的替代方法。 此模型还支持条形码和语言检测。
文档类型
简单文档处理最适合包含结构化信息的文档类型,例如:
Forms - 这些字段通常具有明确的字段和标签,以便更轻松地提取键值对。
发票 - 通常包含具有表和键值对的一致布局。
收据 - 与发票类似,它们具有可轻松提取的结构化数据。
协定 - 包含可有效分析的明确定义的节和子句。
银行对帐单 - 包括非常适合提取的表和结构化数据。
这些文档受益于光学字符识别 (OCR) 功能和深度学习过程,用于提取键值对、选择标记、表和命名实体。
注意
目前,此模型可用于 .pdf 和图像文件类型以及 100 多种语言。 将来的版本中将添加更多受支持的文件类型。
若要使用简单的文档处理模型,请执行以下步骤:
- 步骤 1: 创建模型
- 步骤 2: 上传示例文件进行分析
- 步骤 3: 为模型选择提取器
- 步骤 4: 应用模型
步骤 1:创建模型
按照 在 Syntex 中创建模型 中的说明创建简单的文档处理模型。 然后继续执行以下步骤以完成模型。
步骤 2:上传示例文件进行分析
在 “模型 ”页上的 “添加要分析的文件 ”部分中,选择“ 添加文件”。
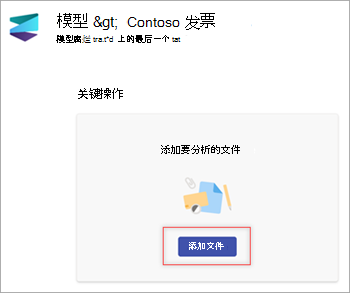
在 “要分析模型的文件 ”页上,选择“ 添加 ”以查找要使用的文件。
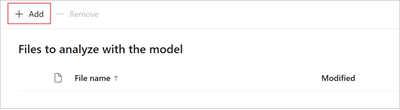
在 “从训练文件库添加文件 ”页上,选择该文件,然后选择“ 添加”。
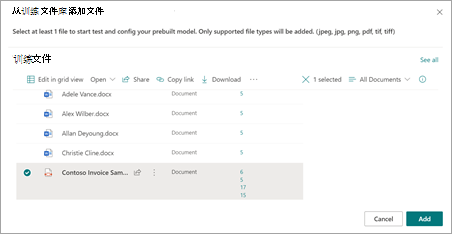
在 “要分析模型的文件” 页上,选择“ 下一步”。
步骤 3:为模型选择提取器
在提取程序详细信息页上,你将看到页面右侧的文档区域和左侧的 “提取程序 ”面板。 “ 提取程序 ”面板显示文档中已标识的提取程序列表。
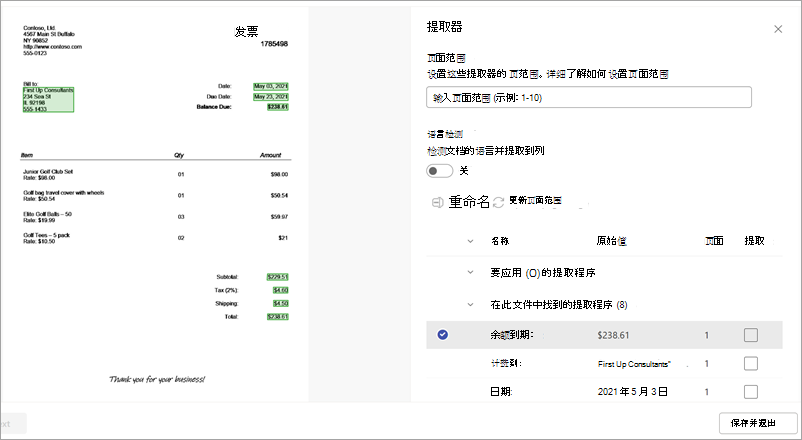
在文档区域中以绿色突出显示的实体字段是模型在分析文件时检测到的项。 选择要提取的实体时,突出显示的字段将更改为蓝色。 如果以后决定不包括实体,突出显示的字段将更改为灰色。 突出显示可更轻松地查看所选提取器的当前状态。
提示
若要放大或缩小以读取实体字段,请使用鼠标滚轮或文档区域底部的缩放控件。
选择提取程序实体
可以根据自己的偏好,从文档区域或“提取程序”面板中选择 提取程序 。
- 若要从文档区域选择提取器,请选择实体字段。
- 若要从“ 提取程序 ”面板中选择提取程序,请在“ 提取 ”列中,选中实体名称右侧的相应复选框。
选择提取程序时,文档区域中会显示 “选择提取程序?” 框。 该框显示为提取程序) 生成的名称 (键名称、 (文档中) 中该字段的值、列类型以及选择实体作为提取程序的选项。
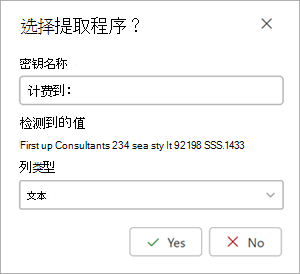
当模型应用于 SharePoint 库时,键名称用作列名称。 如果需要,可以将密钥名称更改为更具描述性。 列类型显示信息在库中的显示方式。 可以更改列类型,以显示信息的显示方式。 将模型应用于库时,可以使用列格式来指定它在文档中的外观。
继续选择要使用的其他提取程序。 还可以添加其他文件以针对此模型配置进行分析。
重命名提取器
可通过三种方式重命名提取程序:
在提取程序详细信息页的文档区域中,选择实体字段。 在 “选择提取程序?” 框中的 “密钥名称” 字段中,输入提取程序的新名称。
在 提取程序 详细信息页的“提取程序”面板中,选择要重命名的提取程序,然后选择“ 重命名”。
在模型主页的“ 提取程序 ”部分中,选择要重命名的提取程序,然后选择“ 重命名”。
设置要处理的页面范围
对于此模型,可以指定以处理文件(而不是整个文件)的页面范围。 在“ 提取程序 ”面板的“ 页面范围 ”部分中,选择要处理的页面。 默认情况下, “页面范围” 设置为空。 如果未提供页面范围,则会处理整个文档。 有关详细信息,请参阅 设置页面范围以从特定页面中提取信息。
检测文档的语言
对于此模型,可以检测文档的语言并将其提取到列中。 在 “提取程序 ”面板的“ 语言检测 ”部分中,切换以启用语言检测。 它显示检测到的语言的 ISO 代码。

还可以从 模型的“模型设置 ”面板中打开或关闭语言检测。
步骤 4:应用模型
若要保存更改并返回到模型主页,请在“ 提取程序 ”面板中选择“ 保存并退出”。
如果已准备好将模型应用于库,请在文档区域中选择“ 下一步”。 在 “添加到库 ”面板上,选择要添加模型的库,然后选择“ 添加”。
有关文件类型、语言、光学字符识别以及此预生成模型的其他注意事项的信息,请参阅 SharePoint 中预生成文档处理的要求和限制。