特定于体验的灾难恢复指南
本文档提供了特定于体验的灾难恢复指南,旨在帮助组织在发生区域性灾难时恢复 Fabric 数据。
示例方案
本文档中的一些指导部分使用了以下示例方案进行阐述和说明。 请根据需要回顾此方案。
假设你在区域 A 中有一个容量 C1,其中有一个工作区 W1。 如果已为容量 C1 启用灾难恢复,会将 OneLake 数据复制到区域 B 中的备份。如果区域 A 发生中断,C1 中的 Fabric 服务就会故障转移到区域 B。
下图演示了此场景。 左侧框所示为中断的区域。 中间框表示故障转移后数据的持续可用性,右侧框所示为客户还原其服务的全部功能后完全恢复的状态。
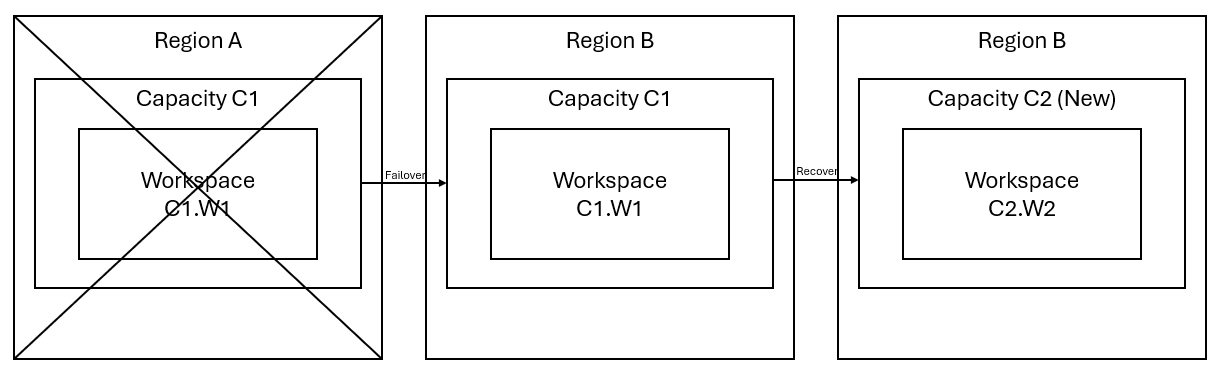
下面是常规恢复计划:
在新区域中创建新的 Fabric 容量 C2。
在 C2 中创建新的 W2 工作区,其中包括与 C1.W1 中名称相同的相应项。
将数据从中断的 C1.W1 复制到 C2.W2.
按照每个部分的专用说明还原各个项的全部功能。
特定于体验的恢复计划
以下部分提供针对每种 Fabric 体验的分步指南,帮助客户完成恢复过程。
数据工程
本指南将指导你完成数据工程体验的恢复过程。 其中包括湖屋、笔记本和 Spark 作业定义。
Lakehouse
原区域的湖屋对客户仍然不可用。 若要恢复湖屋,客户可以在工作区 C2.W2 中重新创建湖屋。 我们建议使用两种方法恢复湖屋:
方法 1:使用自定义脚本复制湖屋 Delta 表和文件
客户可以使用自定义 Scala 脚本重新创建湖屋。
在新建的工作区 C2.W2 中创建湖屋(例如 LH1)。
在工作区 C2.W2 中新建笔记本。
若要从原始湖屋恢复表和文件,请参考具有 OneLake 路径(如 abfss)的数据(请参阅连接到 Microsoft OneLake)。 在笔记本中可以使用下面的代码示例(请参阅 Microsoft Spark 实用工具简介),从原始湖屋获取文件和表的 ABFS 路径。 (将 C1.W1 替换为实际工作区名称)
mssparkutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')使用以下代码示例将表和文件复制到新创建的湖屋。
对于 Delta 表,需要一次复制一个表才能在新湖屋中恢复。 对于湖屋文件,可以一次复制带所有基础文件夹的完整文件结构。
请联系支持团队,了解脚本中所需的故障转移时间戳。
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support mssparkutils.fs.cp(source, destination, true) val filesToDelete = mssparkutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelte <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelte.name}" println(s"Deleting file $destFileToDelete") mssparkutils.fs.rm(destFileToDelete, false) } mssparkutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)运行脚本后,表将显示在新湖屋中。
方法 2:使用 Azure 存储资源管理器来复制文件和表
若要仅从原始湖屋恢复特定的湖屋文件或表,请使用 Azure 存储资源管理器。 有关详细步骤,请参考将 OneLake 与 Azure 存储资源管理器集成。 对于大型数据,请使用方法 1。
注意
上述两种方法可以同时恢复 Delta 格式表的元数据和数据,因为在 OneLake 中元数据是与数据并置并存储的。 对于使用 Spark 数据定义语言 (DDL) 脚本/命令创建的非 Delta 格式表(例如 CSV、Parquet 等),由用户负责维护和重新运行 Spark DDL 脚本/命令来恢复它们。
笔记本
主要区域中的笔记本对客户仍然不可用,笔记本中的代码也不会复制到次要区域。 若要在新区域中恢复笔记本代码,可通过以下两种方法恢复笔记本代码内容。
方法 1:用户管理的冗余与 Git 集成(公共预览版)
最简单快捷的方式就是使用 Fabric Git 集成,然后将笔记本与 ADO 存储库同步。 服务故障转移到另一个区域后,可以使用该存储库在创建的新工作区中重新生成笔记本。
为工作区配置 Git 集成,然后选择“连接并同步”ADO 存储库。
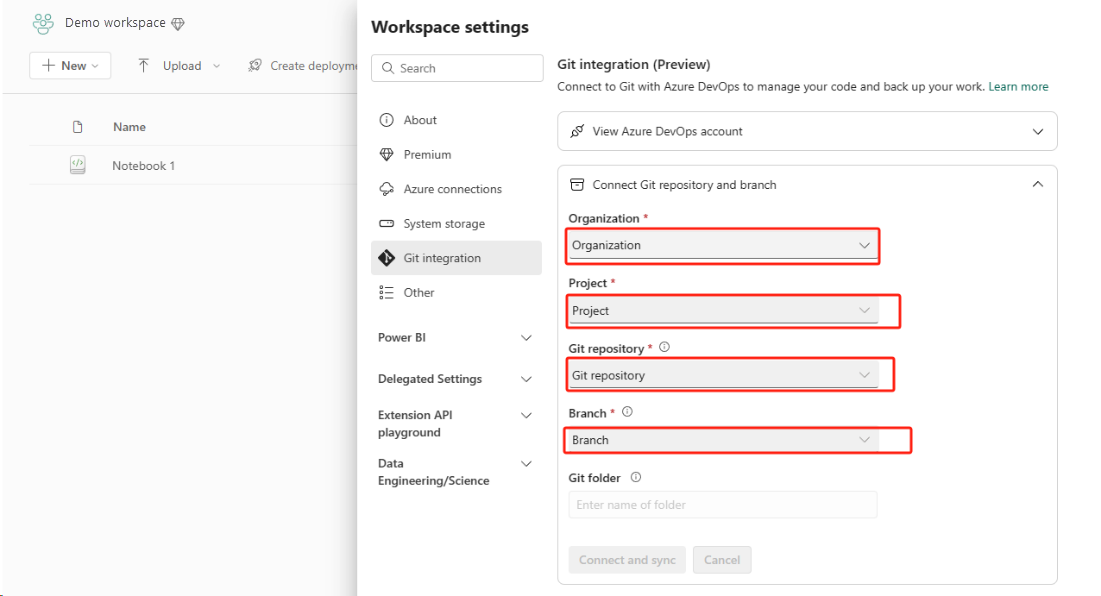
下图显示了同步后的笔记本。
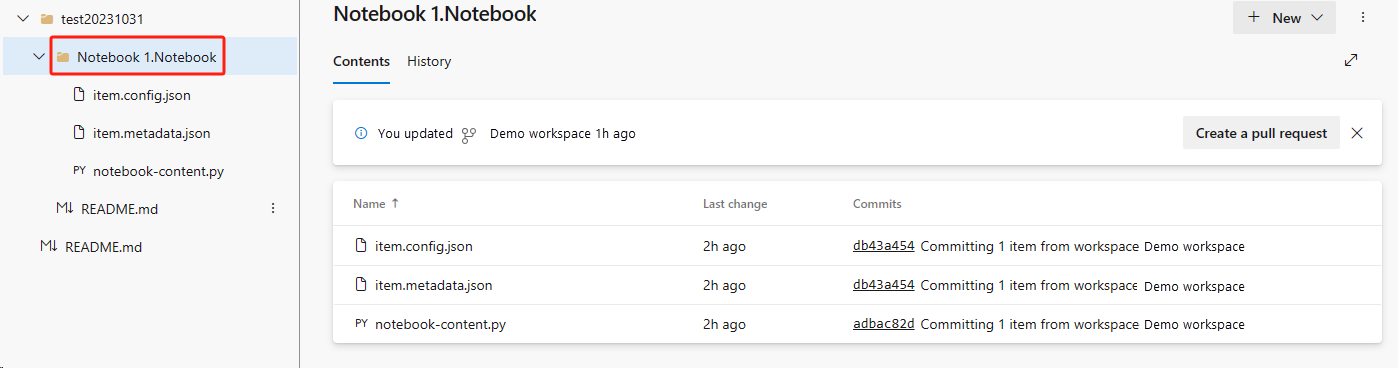
从 ADO 存储库恢复笔记本。
在新创建的工作区中,再次连接到 Azure ADO 存储库。
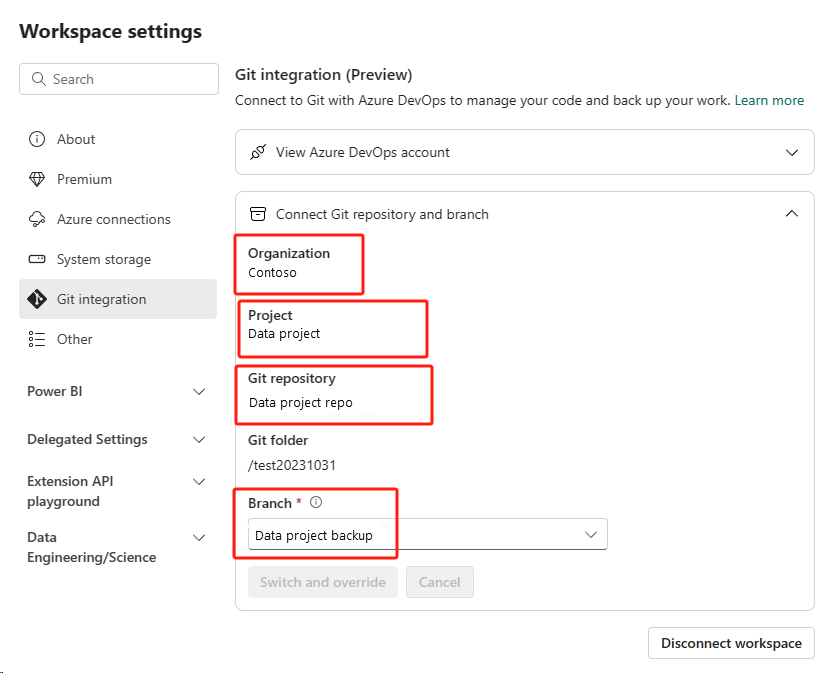
选择“源代码管理”按钮。 然后选择存储库的相关分支。 然后选择“全部更新”。 将显示原始笔记本。
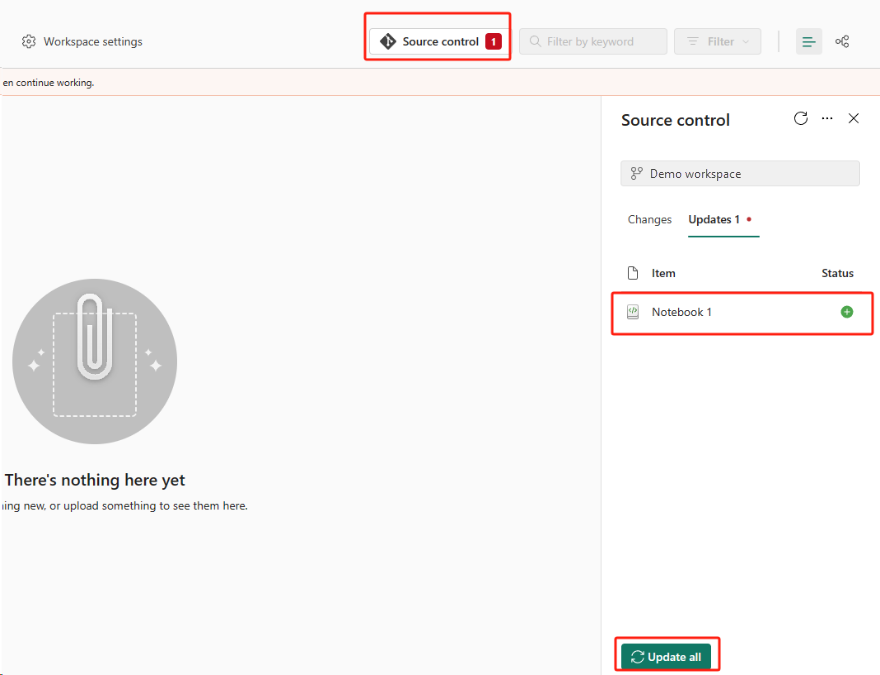
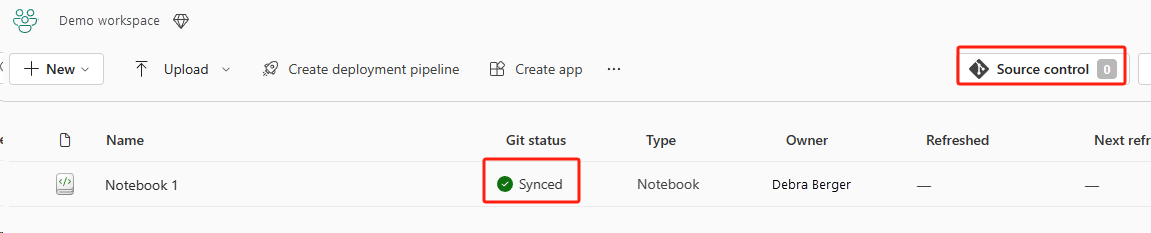
如果原始笔记本具有默认湖屋,用户可以参考湖屋部分恢复湖屋,然后将新恢复的湖屋连接到新恢复的笔记本。
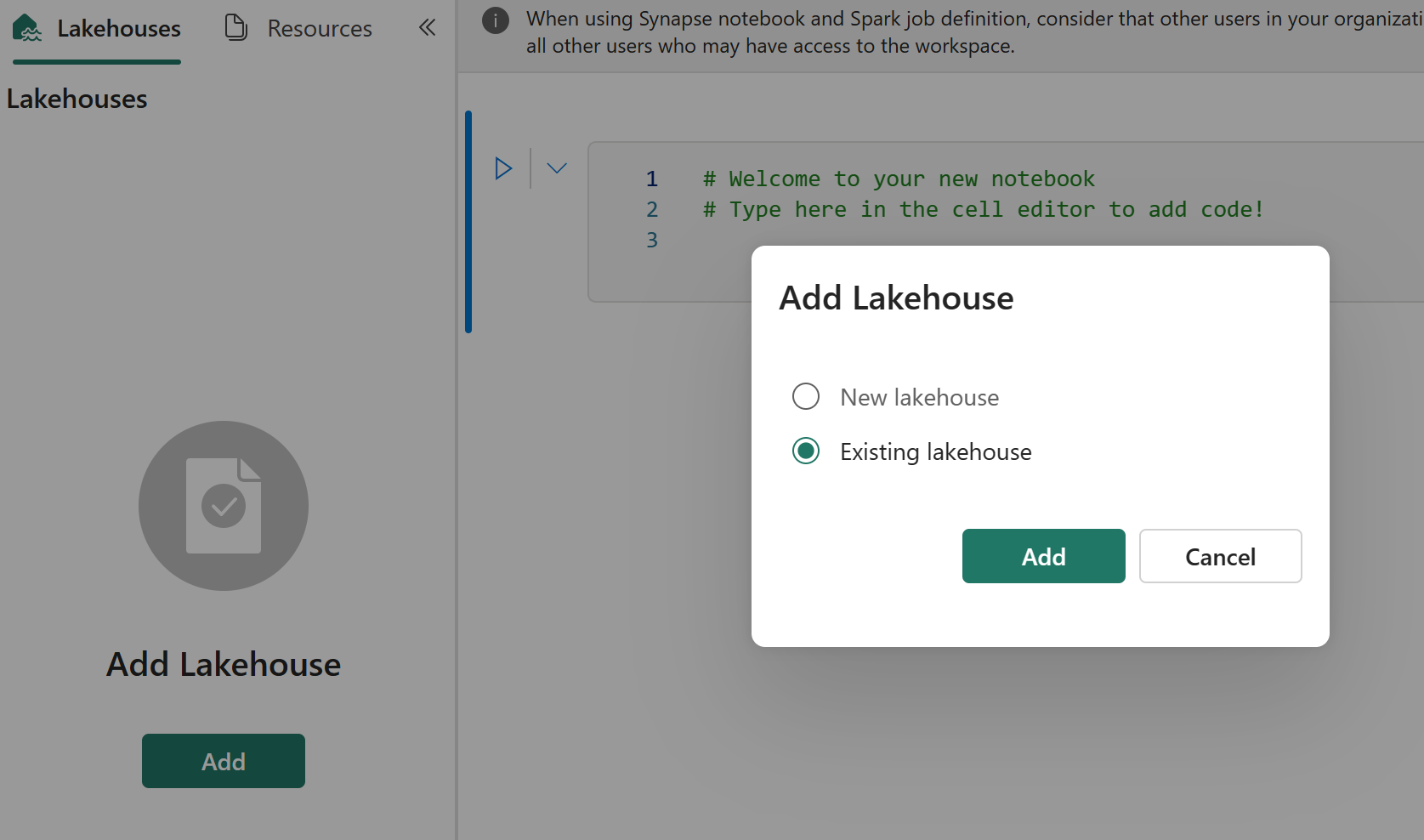
Git 集成不支持在笔记本资源管理器中同步文件、文件夹或笔记本快照。
如果原始笔记本在笔记本资源管理器中包含文件:
请务必将文件或文件夹保存到本地磁盘或其他位置。
将文件从本地磁盘或云驱动器重新上传到恢复后的笔记本。
如果原始笔记本具有笔记本快照,同样需将笔记本快照保存到自己的版本控制系统或本地磁盘。
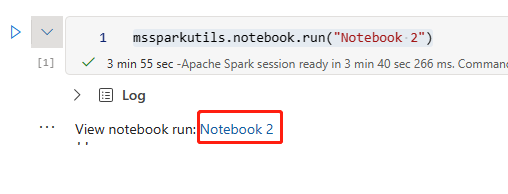
有关 Git 集成的详细信息,请参阅 Git 集成简介。
方法 2:手动备份代码内容
如果不采用 Git 集成方法,可以将最新版本的代码、资源管理器中的文件和笔记本快照保存到版本控制系统(如 Git)中,然后在灾难发生后手动恢复笔记本内容:
使用“导入笔记本”功能导入要恢复的笔记本代码。
导入后,转到所需的工作区(例如“C2.W2”)访问这些代码。
如果原始笔记本具有默认的湖屋,请参考湖屋部分。 然后将新恢复的湖屋(与原始默认湖屋的内容相同)连接到新恢复的笔记本。
如果原始笔记本在资源管理器中包含文件或文件夹,请重新上传保存在用户版本控制系统中的文件或文件夹。
Spark 作业定义
主要区域中的 Spark 作业定义 (SJD) 对客户仍然不可用,笔记本中的主定义文件和引用文件将通过 OneLake 复制到次要区域。 如果要在新区域中恢复 SJD,可以按照下面所述的手动步骤恢复 SJD。 请注意,不会恢复 SJD 的历史运行。
可以通过使用 Azure 存储资源管理器从原始区域复制代码并在灾难发生后手动重新连接湖屋引用来恢复 SJD 项。
在新工作区 C2.W2 中,使用与原始 SJD 项相同的设置和配置(例如语言、环境等)创建新的 SJD 项(例如 SJD1)。
使用 Azure 存储资源管理器将 Libs、Mains 和 Snapshots 从原始 SJD 项复制到新的 SJD 项。
代码内容将显示在新创建的 SJD 中。 需要手动将新恢复的湖屋引用添加到作业中(请参阅湖屋恢复步骤)。 用户需要手动重新输入原始命令行参数。
现在便可运行新恢复的 SJD 或制定计划。
有关 Azure 存储资源管理器的详细信息,请参阅将 OneLake 与 Azure 存储资源管理器集成。
数据科学
本指南将指导你完成数据科学体验的恢复过程。 其中包括机器学习模型和试验的内容。
机器学习模型和试验
主要区域中的数据科学项对客户仍然不可用,机器学习模型和试验中的内容与元数据也不会复制到次要区域。 若要在新区域中完全恢复它们,请将代码内容保存到版本控制系统(如 Git)中,然后在灾难发生后手动重新运行这些代码内容。
恢复笔记本。 请参考笔记本恢复步骤。
配置、历史运行的指标和元数据不会复制到配对区域。 在灾难发生后,必须重新运行每个版本的数据科学代码才能完全恢复机器学习模型和试验。
数据仓库
本指南将指导你完成数据仓库体验的恢复过程。 其中包括仓库内容。
存放地点
原始区域的仓库对客户仍然不可用。 若要恢复仓库,请使用以下两个步骤。
在工作区 C2.W2 中,为要从原始仓库复制的数据创建新的临时湖屋。
利用仓库资源管理器和 T-SQL 功能填充仓库的 Delta 表(请参阅 Microsoft Fabric 中数据仓库的表)。
注意
建议根据开发做法保留仓库代码(架构、表、视图、存储过程、函数定义和安全代码)版本并将其保存在安全位置(如 Git)。
通过湖屋和 T-SQL 代码引入数据
在新创建的工作区 C2.W2 中:
在 C2.W2 中创建临时湖屋“LH2”。
按照湖屋恢复步骤,从原始仓库恢复临时湖屋中的 Delta 表。
在 C2.W2. 中创建新的仓库“WH2”。
在仓库资源管理器中连接临时湖屋。
根据你在数据导入之前部署表定义的方式,用于导入的实际 T-SQL 可能会有所不同。 可以使用 INSERT INTO、SELECT INTO 或 CREATE TABLE AS SELECT 方法从湖屋恢复仓库表。 在本示例中,我们将使用 INSERT INTO 方法。 (如果使用下面的代码,请将示例替换为实际表名称和列名称)
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GO最后,使用 Fabric 仓库更改应用程序中的连接字符串。
注意
如果客户需要跨区域的灾难恢复和完全自动的业务连续性,我们建议在单独的 Fabric 区域中保留两个 Fabric 仓库设置,并通过定期部署并将数据引入两个站点来维护代码和数据奇偶校验。
镜像数据库
主要区域中的镜像数据库仍然对客户不可用,并且设置不会复制到次要区域。 若要在发生区域故障时进行恢复,需要在另一个工作区中从其他区域重新创建镜像数据库。
数据工厂
主要区域中的数据工厂项对客户仍然不可用,数据管道中的设置与配置或数据流 Gen2 项也不会复制到次要区域。 若要在发生区域性故障时恢复这些项,需要从其他区域的另一个工作区中重新创建数据集成项。 有关详细信息,请参阅以下部分。
Dataflows Gen2
如果要在新区域中恢复数据流 Gen2 项,需要将 PQT 文件导出到 Git 等版本控制系统中,然后在灾难发生后手动恢复数据流 Gen2 内容。
针对你的数据流 Gen2 项,在 Power Query 编辑器的“主页”选项卡中,选择“导出模板”。
在“导出模板”对话框中,输入此模板的名称(必填)和说明(选填)。 完成后,选择确定。
灾难发生后,在新工作区“C2.W2”中创建新的数据流 Gen2 项。
在 Power Query 编辑器的当前视图窗格中,选择“从 Power Query 模板导入”。
在“打开”对话框中,浏览到默认的“下载”文件夹,并选择在前面的步骤中保存的 .pqt 文件。 然后选择“打开”。
然后,该模板会被导入到你的新数据流 Gen2 项中。
数据管道
如果发生区域灾难,客户无法访问数据管道,配置也不会复制到配对区域。 建议在跨不同的区域的多个工作区中构建关键数据管道。
复制作业
CopyJob 用户必须采取主动措施,防止区域性灾难。 以下方法可确保在发生区域性灾难后,用户的 CopyJobs 仍然可用。
用户管理的冗余与 Git 集成(公共预览版)
使此过程变得简单快捷的最佳方式是使用 Fabric Git 集成,然后将 CopyJob 与 ADO 存储库同步。 服务故障转移到另一个区域后,可以使用该存储库在创建的新工作区中重新生成 CopyJob。
配置工作区的 Git 集成并选择 连接和同步 与 ADO 存储库。
下图显示了同步后的 CopyJob。
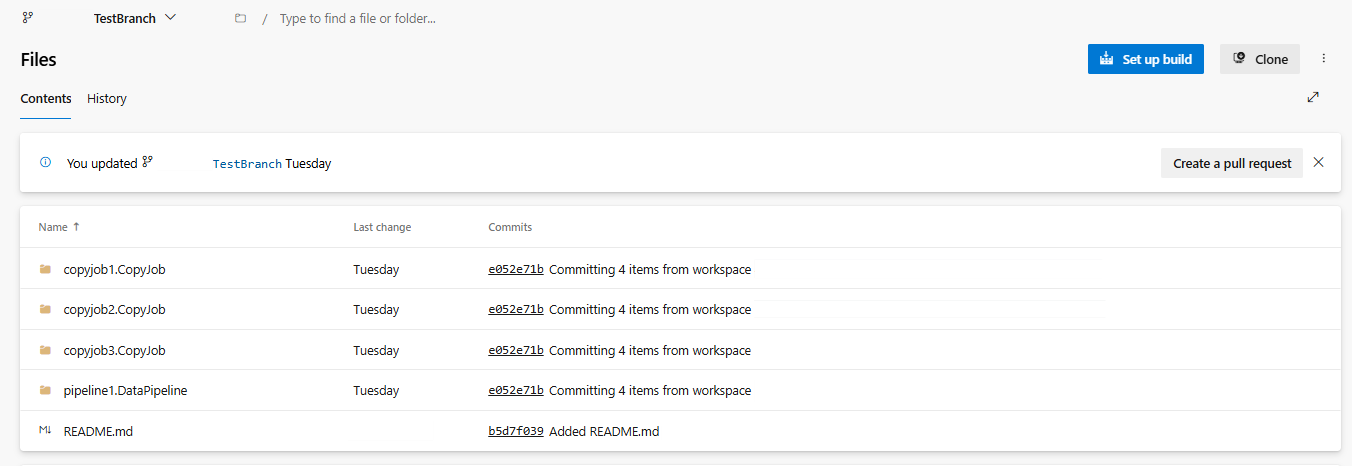
从 ADO 存储库中恢复 CopyJob。
在新创建的工作区中,再次连接并同步到 Azure ADO 存储库。 此存储库中的所有 Fabric 项会自动下载到新的工作区。
显示工作区重新连接到 ADO 存储库的屏幕截图
如果原始 CopyJob 使用湖屋,用户可以参考湖屋部分恢复湖屋,然后将新恢复的 CopyJob 连接到新恢复的湖屋。
有关 Git 集成的详细信息,请参阅 Git 集成简介。
Real-Time Intelligence
本指南将指导你完成 Real-Time Intelligence 体验的恢复过程。 其中包括 KQL 数据库/查询集和事件流内容。
KQL 数据库/查询集
KQL 数据库/查询集用户必须采取主动措施,防止发生区域性灾难。 以下方法可确保在发生区域性灾难时,KQL 数据库查询集中的数据将保持安全且可访问。
使用以下步骤保证对 KQL 数据库和查询集实施有效的灾难恢复解决方案。
建立独立的 KQL 数据库:在专用 Fabric 容量上配置两个或多个独立的 KQL 数据库/查询集。 应在两个不同的 Azure 区域(最好是 Azure 配对区域)中进行这些设置,以最大程度地提高复原能力。
复制管理活动:应将在一个 KQL 数据库中执行的所有管理操作镜像到另一个。 这样可以确保这两个数据库保持同步。要复制的关键活动包括:
表:确保表结构和架构定义在不同的数据库中保持一致。
映射:复制任何所需的映射。 确保数据源和目标完全匹配。
策略:确保两个数据库具有类似的数据保留、访问和其他相关策略。
管理身份验证和授权:对每个副本设置所需的权限。 确保建立适当的授权级别,对必要人员授予访问权限,同时又能保持安全标准。
并行数据引入:要使数据在多个区域保持一致并准备就绪,请在引入数据的同时将同一个数据集加载到每个 KQL 数据库中。
事件流
事件流就是在 Fabric 平台中提供一个集中位置,用于捕获、转换实时事件并将其路由到各种目标(例如,湖屋、KQL 数据库/查询集),同时提供无代码体验。 只要灾难恢复支持这些目标,事件流就不会丢失数据。 因此,客户应使用这些目标系统的灾难恢复功能来保证数据可用性。
客户还可以通过在实施多站点主动/主动策略过程中,在多个 Azure 区域中部署相同的事件流工作负载来实现异地冗余。 使用多站点主动/主动方法,客户可以在任何部署的区域中访问其工作负载。 这种方法是灾难恢复中最复杂、也是成本最高的方法,但在大多数情况下,这种方法可以将恢复时间缩减到接近零。 若要实现完全异地冗余,客户可以
在不同的区域中创建其数据源的副本。
在相应的区域中创建事件流项。
将这些新项连接到相同的数据源。
为不同区域中的每个事件流添加相同的目标。