使用 Azure Databricks 将数据引入 OneLake 并进行分析
在本指南中,你将:
在工作区中创建管道,并以增量格式将数据引入你的 OneLake 中。
使用 Azure Databricks 读取和修改 OneLake 中的增量表。
先决条件
在开始之前,你必须具有:
包含湖屋项的工作区。
高级 Azure Databricks 工作区。 只有高级 Azure Databricks 工作区支持 Microsoft Entra 凭据直通。 创建群集时,在“高级选项”中启用 Azure Data Lake Storage 凭据直通。
示例数据集。
引入数据并修改增量表
导航到 Power BI 服务中的湖屋,依次选择“获取数据”、“新建数据管道”。
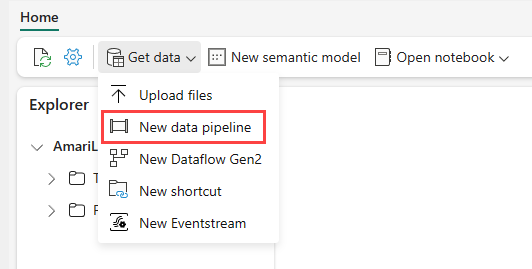
在“新建管道”提示中,输入新管道的名称,然后选择“创建”。
对于本练习,请选择“NYC 出租车 - 绿色”示例数据作为数据源,然后选择“下一步”。
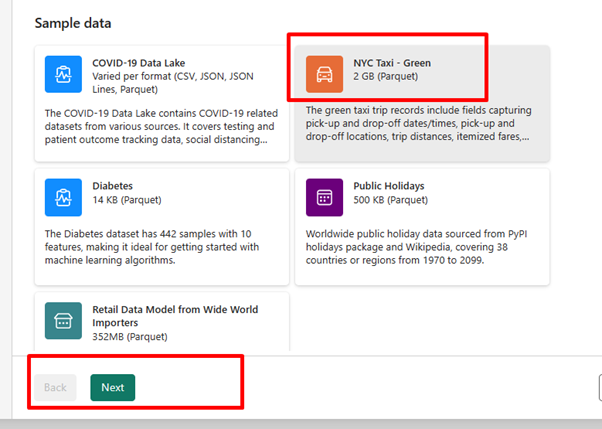
在预览屏幕上,选择“下一步”。
对于数据目标,选择要用于存储 OneLake 增量表数据的 湖屋的名称。 可以选择现有湖屋或新建湖屋。
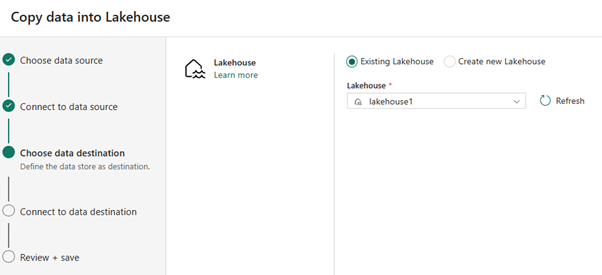
选择要存储输出的位置。 选择“表”作为根文件夹,并输入“nycsample”作为表名称。
在“查看 + 保存”屏幕上,依次选择“立即开始数据传输”、“保存 + 运行”。
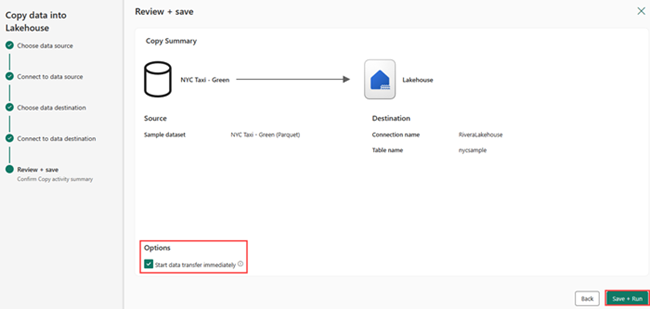
作业完成后,导航到湖屋并查看 /Tables 文件夹下列出的增量表。
右键单击创建的表名称,选择“属性”,然后复制 Azure Blob 文件系统 (ABFS) 路径。
打开 Azure Databricks 笔记本。 读取 OneLake 上的增量表。
olsPath = "abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample" df=spark.read.format('delta').option("inferSchema","true").load(olsPath) df.show(5)通过更改字段值更新增量表数据。
%sql update delta.`abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample` set vendorID = 99999 where vendorID = 1;