使用 Apache Spark 转换数据并使用 SQL 进行查询
在本指南中,你将:
使用 OneLake 文件资源管理器将数据上传到 OneLake。
使用 Fabric 笔记本读取 OneLake 上的数据,并作为增量表写回。
使用 Fabric 笔记本通过 Spark 分析和转换数据。
使用 SQL 查询 OneLake 上的一个数据副本。
先决条件
开始之前,必须:
下载并安装 OneLake 文件资源管理器。
创建包含湖屋项的工作区。
下载 WideWorldImportersDW 数据集。 可以使用 Azure 存储资源管理器连接到
https://fabrictutorialdata.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_city,并下载 csv 文件集。 或者可以使用自己的 csv 数据并根据需要更新详细信息。
注意
请始终直接在湖屋的“表”部分下创建、加载 Delta-Parquet 数据或创建这些数据的快捷方式。 不要将表嵌套在“表”部分下的子文件夹中,因为湖屋不会将其识别为表,并将它标记为“未识别”。
上传、读取、分析和查询数据
在 OneLake 文件资源管理器中,导航到湖屋并在
/Files目录下创建名为dimension_city的子目录。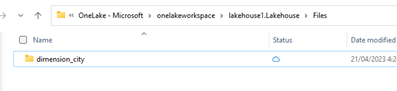
使用 OneLake 文件资源管理器将示例 csv 文件复制到 OneLake 目录
/Files/dimension_city。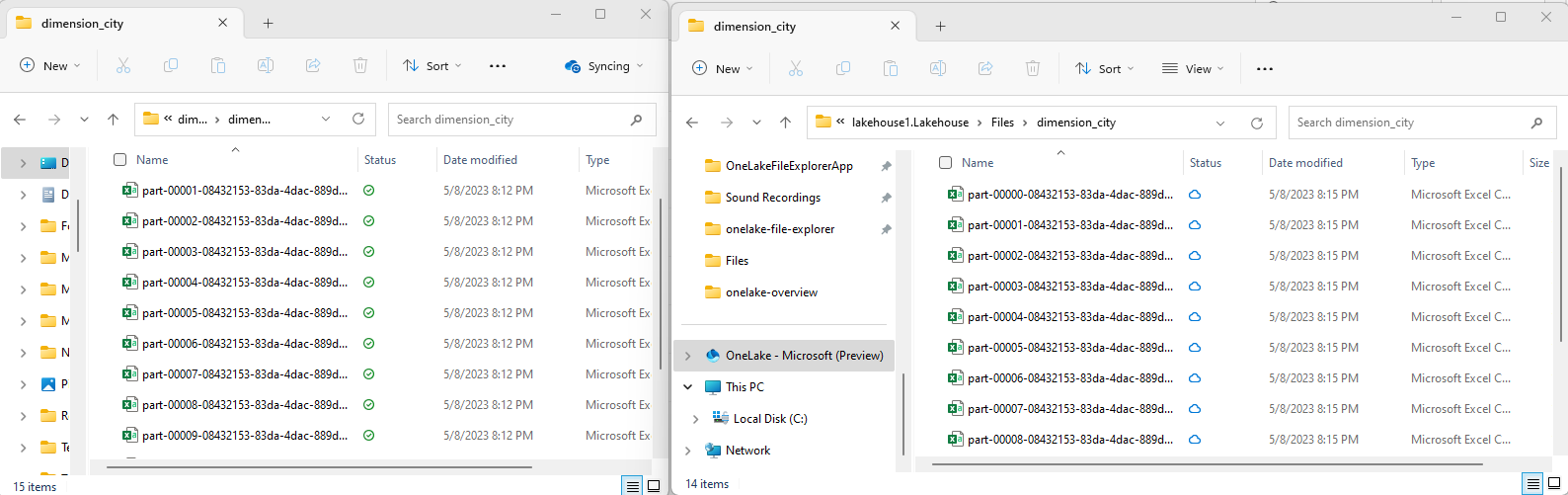
导航到 Power BI 服务中的湖屋并查看文件。
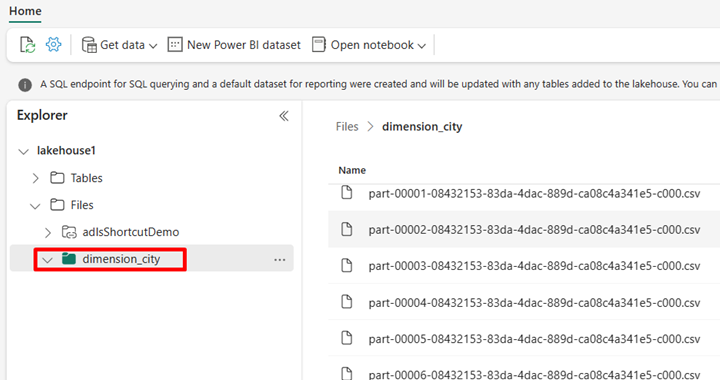
选择“打开笔记本”,然后选择“新建笔记本”以创建笔记本。
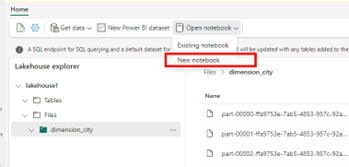
使用 Fabric 笔记本,将 CSV 文件转换为增量格式。 以下代码片段可从用户创建的目录
/Files/dimension_city读取数据,并将其转换为增量表dim_city。import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/<replace with your folder path>"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Files/<folder name>/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/<name of delta table>")要查看新表,请刷新
/Tables目录的视图。
在同一 Fabric 笔记本中使用 SparkSQL 查询表。
%%sql SELECT * from <replace with item name>.dim_city LIMIT 10;通过添加数据类型为整数,名为 newColumn 的新列来修改增量表。 为此新添加的列的所有记录设置值 9。
%%sql ALTER TABLE <replace with item name>.dim_city ADD COLUMN newColumn int; UPDATE <replace with item name>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <replace with item name>.dim_city LIMIT 10;还可以通过 SQL 分析终结点访问 OneLake 上的任何增量表。 SQL 分析终结点引用 OneLake 上增量表的相同物理副本,并提供 T-SQL 体验。 选择 lakehouse1 的 SQL 分析终结点,然后选择“新建 SQL 查询”以使用 T-SQL 查询表。
SELECT TOP (100) * FROM [<replace with item name>].[dbo].[dim_city];
