教程第 2 部分:使用 Microsoft Fabric 笔记本浏览和可视化数据
在本教程中,你将学习如何进行探索性数据分析 (EDA) 来检查和调查数据,同时通过使用数据可视化技术总结其关键特征。
你将使用 seaborn,它是一个 Python 数据可视化库,提供用于在数据帧和数组上生成视觉对象的高级界面。 有关 seaborn 的详细信息,请参阅 Seaborn:统计数据可视化。
你还需要使用数据整理器,这是一种基于笔记本的工具,可为你提供进行探索性数据分析和清理的沉浸式体验。
本教程的主要步骤包括:
- 读取湖屋中的增量表中存储的数据。
- 将 Spark 数据帧转换为 Python 可视化库所支持的 Pandas 数据帧。
- 使用数据整理器执行初始数据清理和转换。
- 使用
seaborn执行探索性数据分析。
先决条件
获取 Microsoft Fabric 订阅。 或者注册免费的 Microsoft Fabric 试用版。
登录 Microsoft Fabric。
使用主页左侧的体验切换器切换到 Synapse 数据科学体验。
这是系列教程的第 2 部分(共 5 部分)。 若要完成本教程,请先完成:
在笔记本中继续操作
2-explore-cleanse-data.ipynb 是本教程随附的笔记本。
若要打开本教程随附的笔记本,请按照让系统为数据科学做好准备教程中的说明操作,将该笔记本导入到工作区。
或者,如果要从此页面复制并粘贴代码,则可以创建新的笔记本。
在开始运行代码之前,请务必将湖屋连接到笔记本。
重要
随附在第 1 部分中使用的同一个湖屋。
从湖屋中读取原始数据
从湖屋的文件部分读取原始数据。 你在上一个笔记本中上传了此数据。 在运行此代码之前,请确保你已将第 1 部分中使用的湖屋连接到此笔记本。
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
基于数据集创建 pandas 数据帧
将 spark 数据帧转换为 pandas 数据帧,以便更轻松地完成处理和可视化。
df = df.toPandas()
显示原始数据
使用 display 浏览原始数据,执行一些基本统计操作并显示图表视图。 请注意,首先需要导入所需的库,例如 Numpy、Pnadas、Seaborn,以及用于数据分析和可视化的 Matplotlib。
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
使用数据整理器执行初始数据清理
若要浏览和转换笔记本中的任何 pandas 数据帧,请直接从笔记本启动数据整理器。
注意
当笔记本内核繁忙时,无法打开数据整理程序。 在启动数据整理器之前,单元执行必须已完成。
- 在笔记本功能区“数据”选项卡下,选择“启动数据整理器”。 你将看到可供编辑的已激活 pandas 数据帧的列表。
- 选择要在数据整理器中打开的数据帧。 由于此笔记本仅包含
df这一个数据帧,因此请选择df。
数据整理器将启动并生成数据的描述性概述。 中间的表将显示每个数据列。 表旁边的“摘要”面板显示有关数据帧的信息。 在表中选择列时,摘要会更新包含有关所选列的信息。 在某些情况下,显示和汇总的数据将是数据帧的截断视图。 如果发生这种情况,你将在“摘要”窗格中看到警告图像。 将鼠标悬停在此警告上可以查看说明情况的文本。

你执行的每个操作只需单击便可应用,实时更新显示的数据并生成可作为可重用函数保存回笔记本的代码。
本部分的其余部分将指导你完成使用数据整理器执行数据清理的步骤。
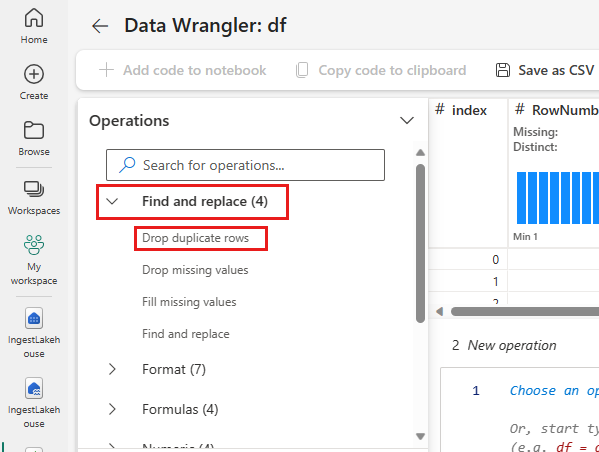
删除重复行
左侧面板中是可以对数据集执行的操作(如查找和替换、格式、公式、数值)的列表。
展开“查找并替换”并选择“删除重复行”。
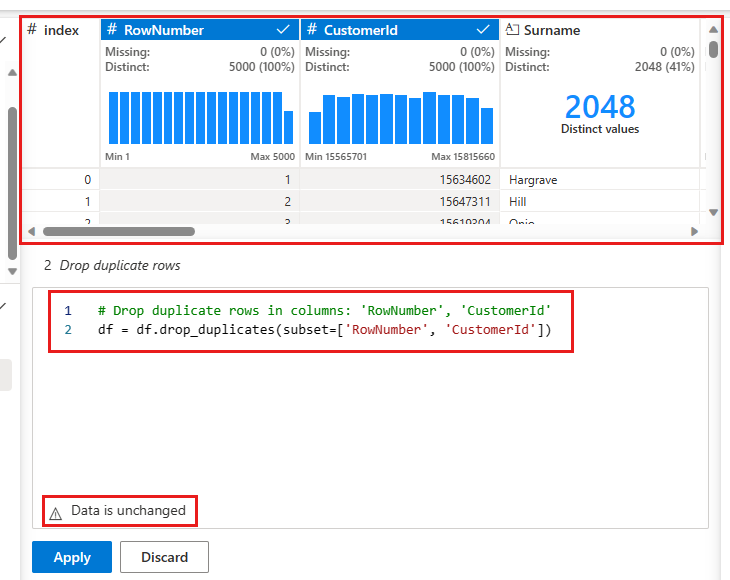
此时会显示一个面板,用于选择要比较的列列表以定义重复行。 选择 RowNumber 和 CustomerId。
中间面板中是此操作结果的预览。 预览版下是执行操作的代码。 在此实例中,数据似乎保持不变。 但是,由于你查看的是截断的视图,因此最好仍然应用该操作。
选择“应用”(位于侧边或底部),转到下一步。

删除缺少数据的行
使用数据整理器删除所有列缺少数据的行。
从“查找和替换”中选择“删除缺失值”。
从“目标”列中选择“全选”。
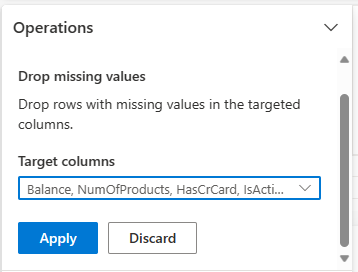
选择“应用”,转到下一步。

删除列
使用数据整理器删除不需要的列。
展开“架构”并选择“删除列”。
选择 RowNumber、CustomerId、Surname。 这些列在预览中显示为红色,表示它们已被代码更改(在本例中为已删除)。
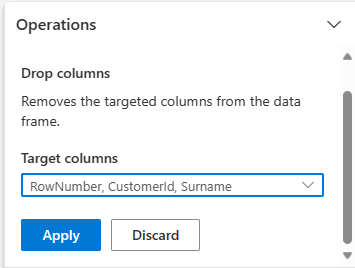
选择“应用”,转到下一步。

将代码添加到笔记本
每次选择“应用”时,都会在左下角的“清理步骤”面板中创建一个新步骤。 在面板底部,选择“预览所有步骤的代码”以查看所有单独步骤的组合。
选择左上角的“向笔记本添加代码”以关闭数据整理器并自动添加代码。 “将代码添加到笔记本”将代码包装在函数中,然后调用该函数。
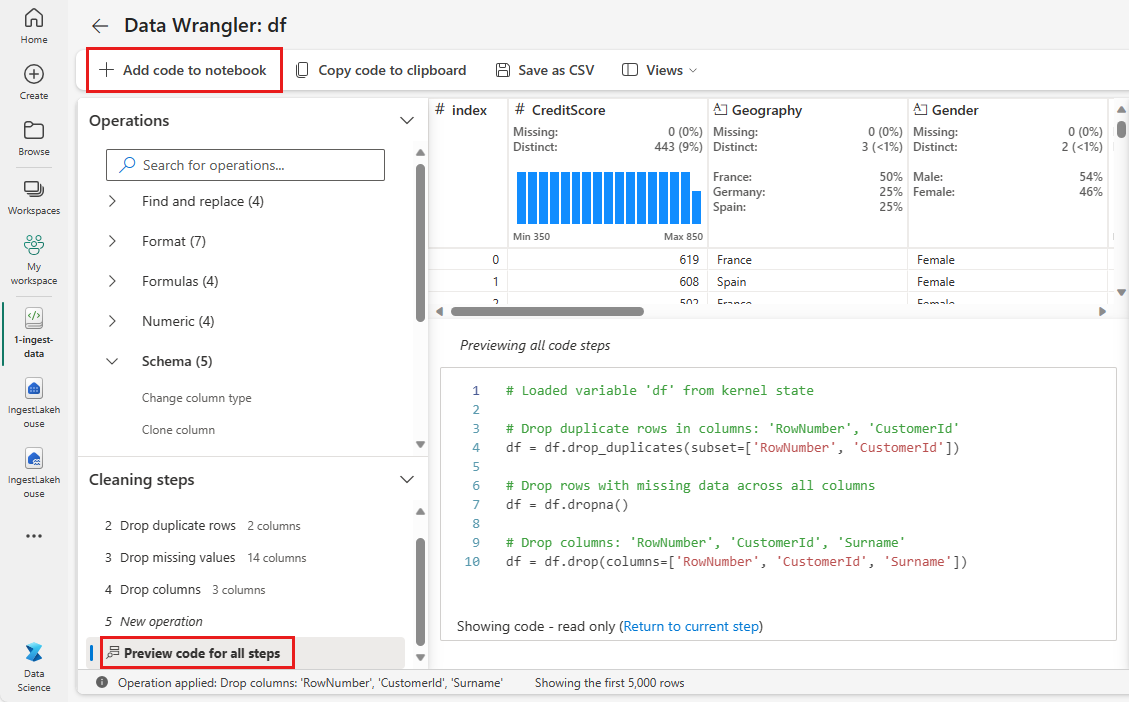
提示
在手动运行新单元格之前,不会应用数据整理器生成的代码。
如果未使用数据整理器,可以改用下一个代码单元。
此代码与数据整理器生成的代码类似,但会将参数 inplace=True 添加到每个生成的步骤中。 通过设置 inplace=True,pandas 将覆盖原始的数据帧,而不是生成新的数据帧作为输出。
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
浏览数据
显示已清理数据的一些摘要和可视化效果。
确定分类、数值和目标属性
使用此代码可以确定分类、数值和目标属性。
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
五数字摘要
使用箱形图显示相应数值属性的五数字摘要(最低分数、第一四分位数、中位数、第三四分位数、最高分数)。
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
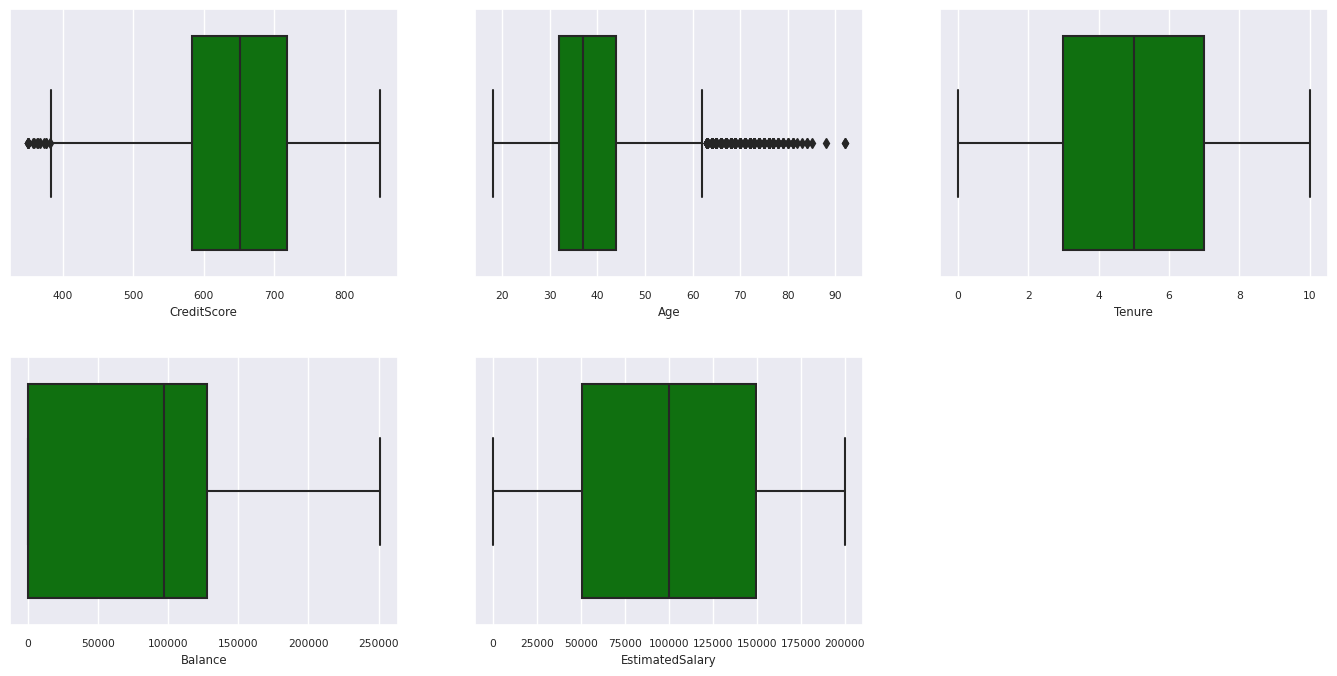
已退出和未退出客户的分布
显示已退出客户与未退出客户在各分类属性中的分布情况。
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)

数值属性的分布
使用直方图显示数值属性的频率分布。
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

执行特征工程
执行特征工程将基于当前属性生成新属性:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
使用数据整理器执行独热编码
数据整理器还可用于执行独热编码。 为此,请重新打开数据整理器。 这次,请选择 df_clean 数据。
- 展开“公式”并选择“独热编码”。
- 此时会显示一个面板,用于选择要执行独热编码的列的列表。 选择“地理”和“性别”。
你可以复此生成的代码,关闭数据整理器以返回笔记本,然后粘贴到新单元格中。 或者,选择左上角的“向笔记本添加代码”以关闭数据整理器并自动添加代码。
如果未使用数据整理器,可以改用下一个代码单元:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
探索性数据分析中的观察结果摘要
- 与西班牙和德国相比,大多数客户来自法国,但西班牙的流失率低于法国和德国。
- 大多数客户都有信用卡。
- 有些客户的年龄和信用评分分别在 60 岁以上和 400 分以下,但他们不能被视为离群值。
- 很少有客户拥有两个以上的银行产品。
- 未处于活动状态的客户流失率较高。
- 性别和保有年数似乎不会影响客户关闭银行账户的决定。
为已清理的数据创建增量表
你将在此系列的下一个笔记本中使用此数据。
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
下一步
通过此数据训练和注册机器学习模型: