为数据科学教程准备系统
在开始数据科学端到端教程系列之前,请先了解先决条件、如何导入笔记本以及如何将湖屋附加到这些笔记本。
先决条件
获取 Microsoft Fabric 订阅。 或者,注册免费的 Microsoft Fabric 试用版。
登录 Microsoft Fabric。
使用主页左下侧的体验切换器切换到 Fabric。
- 如果没有 Microsoft Fabric 湖屋,请按照在 Microsoft Fabric 中创建湖屋中的步骤创建一个。
创建笔记本
每个教程作为 GitHub 中的 Jupyter 笔记本文件提供。 许多教程也可用作数据科学工作负载中的示例。 使用以下方法之一访问教程:
创建新笔记本,然后复制并粘贴本教程中的代码。
-
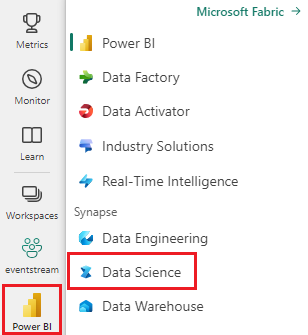
在左窗格中,选择 工作负载。
选择 数据科学。
在“浏览示例”卡片中,选择“选择”。
选择相应的示例:
- 默认情况下,如果示例是针对 Python 教程,请从 端到端工作流(Python) 选项卡开始。
- 如果示例对应的是 R 教程,则从“端到端工作流(R)”选项卡中进行选择。
- 如果示例对应的是快速教程,则从“快速教程”选项卡中进行选择。
-
下载笔记本。 请确保使用 GitHub 中的“Raw”文件链接下载文件。
- 对于“开始”笔记本,请从父文件夹 data-science-tutorial 下载笔记本 (.ipynb) 文件。
- 对于“教程”笔记本,请从父文件夹 ai-samples 下载笔记本 (.ipynb) 文件。
在 Fabric 主页的左侧导航上,选择工作区。
选择“导入”>“笔记本”>“从此计算机”。
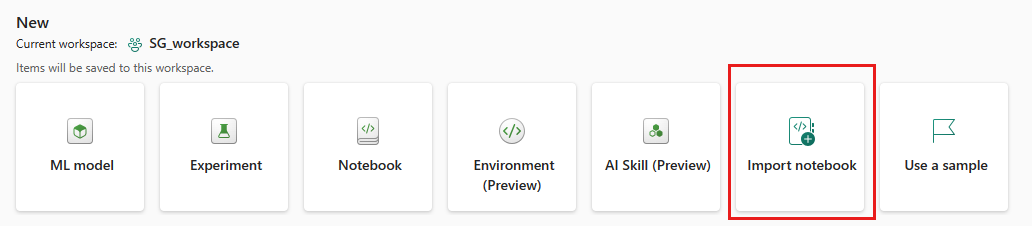
选择“上传”并选择下载的笔记本文件。
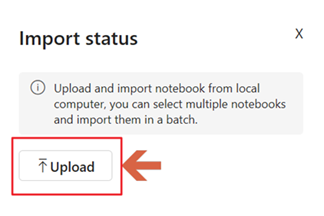
导入笔记本后,在导入对话框中选择“转到工作区”。

导入的笔记本现在可在工作区中使用。
如果导入的笔记本包含输出,请选择“编辑”菜单,然后选择“清除所有输出”。





将湖屋附加到笔记本
为了演示 Fabric Lakehouse 的功能,许多教程都需要将默认的 Lakehouse 附加到笔记本中。 以下步骤显示如何将湖屋添加到已启用 Fabric 的工作区中的笔记本中。
注意
在执行每个笔记本之前,需要在该笔记本上执行这些步骤。
在工作区中打开笔记本。
在左窗格中选择“添加湖屋”。

创建新的湖屋或使用现有的湖屋。
- 若要创建新的湖屋,请选择“新建”。 为湖屋命名并选择 创建。
- 若要使用现有的湖仓,请选择 现有的湖仓 打开 数据枢纽 对话框。 选择要使用的湖屋,然后选择“添加”。
添加湖屋后,它将显示在湖屋窗格中,你可以查看存储在 Lakehouse 中的表和文件。

下一步
第 1 部分:使用 Apache Spark 将数据引入 Fabric Lakehouse