教程:使用功能依赖项清理数据
在本教程中,你将使用功能依赖项进行数据清理。 当语义模型中的一列(Power BI 数据集)是另一列的函数时,就会存在功能依赖关系。 例如,邮政编码 列可以确定 城市 列中的值。 函数依赖关系表现为数据框中两列或多列的值之间的一对多关系。 本教程使用 Synthea 数据集来展示功能关系如何帮助检测数据质量问题。
本教程介绍如何:
- 应用域知识来构建有关语义模型中功能依赖关系的假设。
- 熟悉语义链接的 Python 库(SemPy)组件,以帮助自动执行数据质量分析。 这些组件包括:
- FabricDataFrame - 一种类似 panda 的结构,通过其他语义信息进行了增强。
- 有用的函数可自动评估有关功能依赖关系的假设,并确定语义模型中的关系冲突。
先决条件
获取 Microsoft Fabric 订阅。 或者,注册免费的 Microsoft Fabric 试用版。
登录 Microsoft Fabric。
使用主页左下侧的体验切换器切换到 Fabric。
- 从左侧导航窗格中选择 工作区 以查找并选择工作区。 此工作区将成为当前工作区。
在笔记本中继续操作
data_cleaning_functional_dependencies_tutorial.ipynb 笔记本随附本教程。
若要打开本教程随附的笔记本,请按照 为数据科学教程准备系统 中的说明将笔记本导入工作区。
如果要复制并粘贴此页面中的代码,可以 创建新的笔记本。
在开始运行代码之前,请务必将湖屋附加到笔记本。
设置笔记本
在本部分中,你将使用必要的模块和数据设置笔记本环境。
- 对于 Spark 3.4 及更高版本,使用 Fabric 时,默认运行时中提供了语义链接,无需安装它。 如果使用 Spark 3.3 或更低版本,或者想要更新到最新版本的语义链接,可以运行以下命令:
python %pip install -U semantic-link
执行必要的模块导入以备后用:
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_synthea拉取示例数据。 在本教程中,你将使用合成医疗记录的 Synthea 数据集(简单起见,称其为小版本):
download_synthea(which='small')
浏览数据
使用 providers.csv 文件的内容初始化
FabricDataFrame:providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()通过绘制自动检测到的功能依赖项图来检查 SemPy
find_dependencies函数的数据质量问题:deps = providers.find_dependencies() plot_dependency_metadata(deps)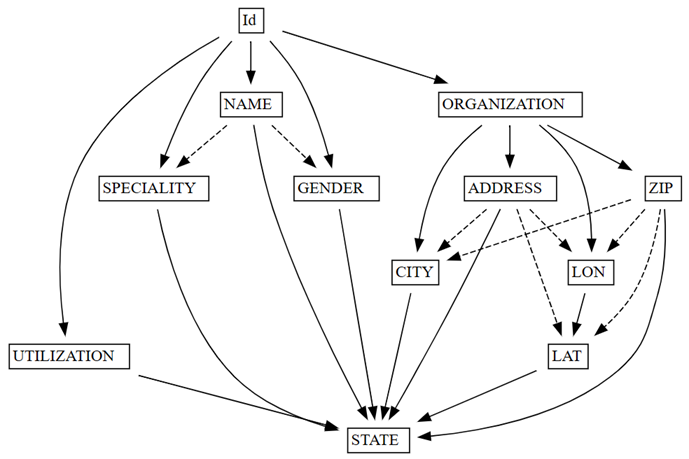
功能依赖项图显示,
Id确定NAME和ORGANIZATION(由实心箭头指示),这是预期的,因为Id是唯一的:确认
Id是唯一的:providers.Id.is_unique代码返回
True,以确认Id是唯一的。

深入分析功能依赖项
函数依赖项图还显示,ORGANIZATION 按预期确定 ADDRESS 和 ZIP。 但是,你可能预计 ZIP 也会确定 CITY,但虚线箭头表示依赖项只是近似的,指向数据质量问题。
图形中还有其他特点。 例如,NAME 不确定 GENDER、Id、SPECIALITY或 ORGANIZATION。 其中每一个特点都值得调查。
更深入地了解
ZIP与CITY之间的近似关系,方法是使用 SemPy 的list_dependency_violations函数查看冲突的表格列表:providers.list_dependency_violations('ZIP', 'CITY')使用 SemPy 的
plot_dependency_violations可视化函数绘制图形。 如果冲突数较小,则此图非常有用:providers.plot_dependency_violations('ZIP', 'CITY')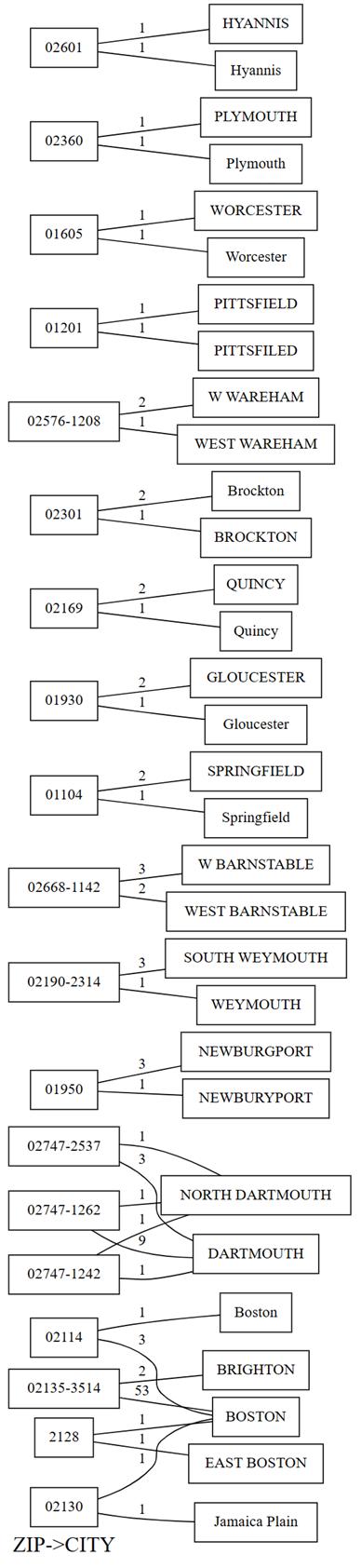
依赖关系冲突的绘图在左侧显示了
ZIP的值,在右侧显示了CITY的值。 如果存在包含这两个值的行,边缘将绘图左侧的邮政编码与右侧的城市连接起来。 边缘使用此类行的计数进行批注。 例如,有两行包含邮政编码 02747-1242,一行包含城市“NORTH DARTHMOUTH”,另一行包含城市“DARTHMOUTH”,如上一个绘图和以下代码所示:通过运行以下代码,确认之前对依赖项冲突绘图所做的观察:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()绘图还显示,在
CITY为“DARTHMOUTH”的行中,9行的ZIP为 02747-1262;一行的ZIP为 02747-1242;一行的ZIP为 02747-2537。 使用以下代码确认这些观察:providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()还有其他与“DARTMOUTH”关联的邮政编码,但这些邮政编码不会显示在依赖项冲突的图中,因为它们不暗示数据质量问题。 例如,邮政编码“02747-4302”与“DARTMOUTH”唯一关联,不会显示在依赖项冲突关系图中。 通过运行以下代码进行确认:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
汇总使用 SemPy 检测到的数据质量问题
返回到依赖项冲突图,可以看到此语义模型中存在几个有趣的数据质量问题:
- 某些城市名称全部大写。 此问题很容易使用字符串方法进行修复。
- 某些城市名称具有限定符(或前缀),例如“North”和“East”。 例如,邮政编码“2128”映射到“EAST BOSTON”一次,一次映射到“BOSTON”。 在“NORTH DARTHMOUTH”和“DARTHMOUTH”之间也存在类似的问题。 可以尝试删除这些限定符,或将邮政编码映射到最常见的城市。
- 某些城市有拼写错误,如“PITTSFIELD”与“PITTSFILED”和“NEWBURGPORT vs. NEWBURYPORT”。 对于“NEWBURGPORT”,可以通过使用更常见的写法来修复此拼写错误。 对于“PITTSFIELD”这种仅有一次出现的情况,在没有外部知识或语言模型的辅助下,自动消除歧义会变得更加困难。
- 有时,前缀(如“West”)缩写为单个字母“W”。 如果出现的所有“W”代表“West”,则只需要进行替换就有可能修复此问题。
- 邮政编码“02130”分别对应“波士顿”和“牙买加平原”。 此问题并不容易修复,但如果有更多数据,则映射到最常见的事件可能是一种潜在的解决方案。
清理数据
通过将所有大写更改为标题大小写来修复大写问题:
providers['CITY'] = providers.CITY.str.title()再次运行冲突检测,发现一些不明确之处已消失(违规次数较小):
providers.list_dependency_violations('ZIP', 'CITY')此时,可以更手动地优化数据,但一个潜在的数据清理任务是使用 SemPy 的
drop_dependency_violations函数删除违反数据列之间的功能约束的行。对于确定变量的每个值,
drop_dependency_violations通过选取依赖变量的最常见值并删除具有其他值的所有行来工作。 仅当确信此统计启发式操作会导致数据得到正确的结果时,才应应用此操作。 否则,应编写自己的代码来根据需要处理检测到的冲突。对
ZIP和CITY列运行drop_dependency_violations函数:providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')列出
ZIP和CITY之间的任何依赖性违规:providers_clean.list_dependency_violations('ZIP', 'CITY')该代码返回一个空列表,指示不再违反 CITY -> ZIP 的功能约束。
相关内容
查看有关语义链接/SemPy 的其他教程:
- 教程:分析示例语义模型中的功能依赖项
- 教程:从 Jupyter 笔记本中提取和计算 Power BI 度量值
- 教程:使用语义链接 发现语义模型中的关系
- 教程:使用语义链接 发现 Synthea 数据集中的关系
- 教程:使用 SemPy 和 Great Expectations (GX) 验证数据