Dataflows Gen2 中的快速复制
本文介绍适用于 Microsoft Fabric 的数据工厂中的 Dataflows Gen2 的快速复制功能。 数据流有助于引入和转换数据。 通过使用 SQL DW 计算引入数据流横向扩展,可以大规模转换数据。 但是,需要首先引入数据。 引入快速复制后,可以通过简单的数据流体验以及管道复制活动的可缩放后端引入 TB 级数据。
启用此功能后,当数据大小超过特定阈值时,数据流会自动切换后端,而无需在数据流创作期间进行任何更改。 刷新数据流后,可以通过查看刷新历史记录中显示的引擎类型来检查运行期间是否使用了快速复制。
开启 需要快速复制 选项后,若未使用快速复制,则数据流刷新将被取消。 这有助于避免等待刷新超时后再继续。 此行为还有助于在调试会话中使用数据测试数据流行为,同时减少等待时间。 使用查询步骤窗格中的快速复制指示器,可以轻松检查查询是否可以通过快速复制运行。

先决条件
- 必须具有 Fabric 容量。
- 对于文件数据,文件采用 .csv 或 parquet 格式,大小至少为 100 MB,并存储在 Azure Data Lake Storage (ADLS) Gen2 或 Blob 存储帐户中。
- 对于包括 Azure SQL DB 和 PostgreSQL 在内的数据库,数据源中有 500 万行或更多的数据。
注意
可以通过选择“需要快速复制”设置来绕过阈值,以强制执行快速复制。
连接器支持
目前以下 Dataflow Gen2 连接器支持快速复制:
- ADLS Gen2
- Blob 存储
- Azure SQL DB
- Lakehouse
- PostgreSQL
- 本地 SQL Server
- 仓库
- Oracle
- Snowflake
连接到文件源时,复制活动仅支持几个转换:
- 合并文件
- 选择列
- 更改数据类型
- 重命名列
- 删除列
仍然可以通过将引入和转换步骤拆分为单独的查询来应用其他转换。 第一个查询实际检索数据,第二个查询引用其结果,以便可以使用 DW 计算。 对于 SQL 源,支持属于本机查询一部分的任何转换。
直接将查询加载到输出目标时,当前仅支持湖屋目标。 如果想使用其他输出目标,可以先暂存查询,然后再引用它。
如何使用快速复制
导航到相应的 Fabric 端点。
导航到高级工作区并创建 Dataflows Gen2。
在新数据流的“主页”选项卡上,选择“选项”:
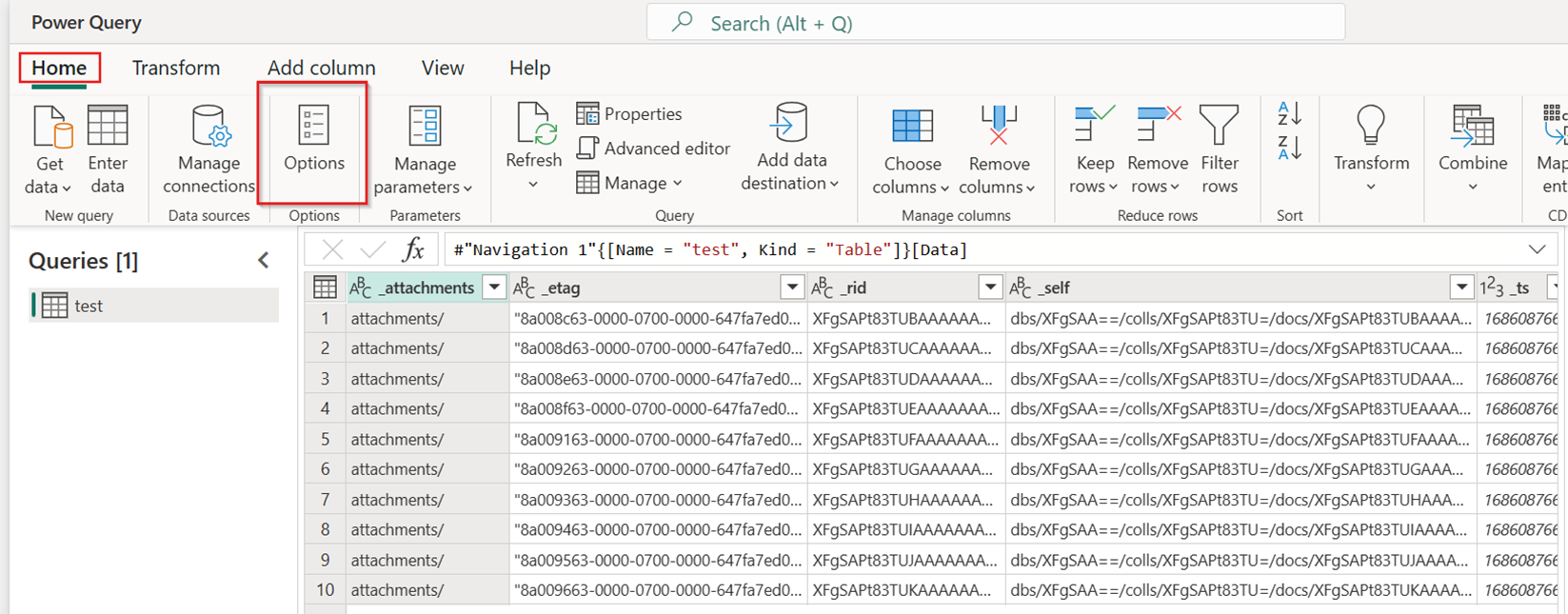
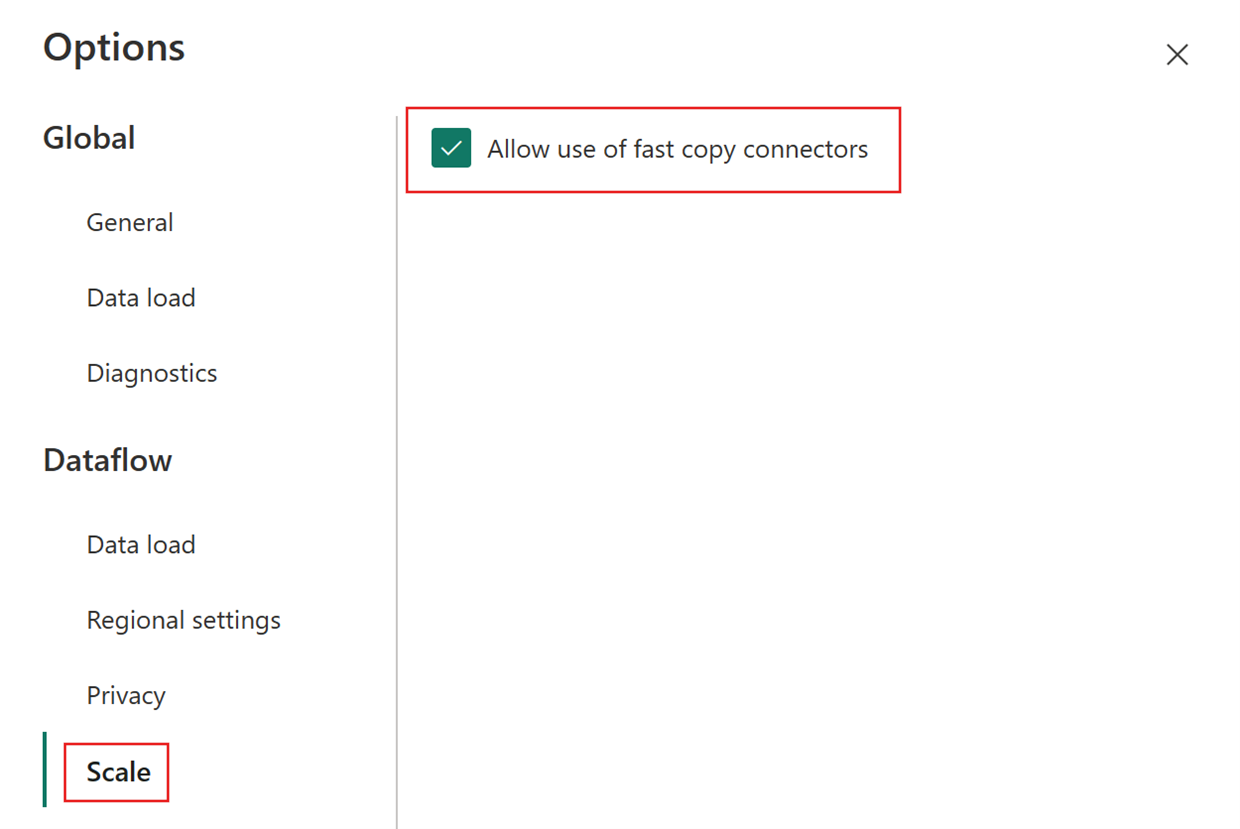
然后,选择“选项”对话框中的“缩放”选项卡,并选中“允许使用快速复制连接器”复选框以打开快速复制。 这时,关闭“选项”对话框。
选择“获取数据”,然后选择 ADLS Gen2 源,并填写容器的详细信息。
使用合并文件功能。

若要确保快速复制,请仅应用本文连接器支持部分中列出的转换。 如果需要应用更多转换,请先暂存数据,稍后再引用查询。 对引用的查询进行其他转换。
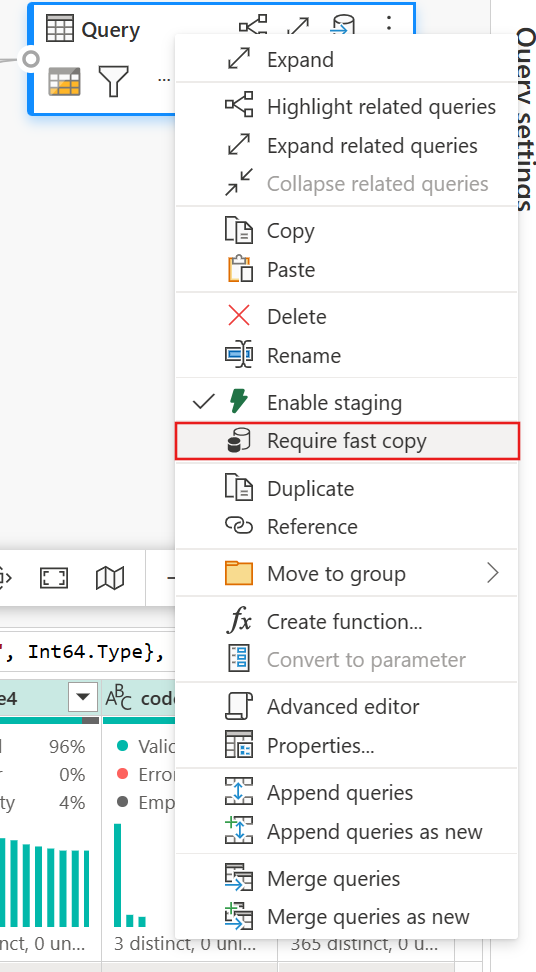
(可选)可以通过右键单击查询来选择并启用该选项来设置查询的“需要快速复制”选项。
(可选)目前,只能将湖屋配置为输出目的地。 对于任何其他目的地,请暂存查询,稍后在另一个可在输出到任何源的查询中引用它。
检查快速复制指示器,查看查询是否可以使用快速复制运行。 如果是,则引擎类型将显示 CopyActivity。

发布数据流。
刷新完成后检查以确认使用了快速复制。

如何拆分查询以利用快速复制
为了获得最佳性能,使用 Dataflow Gen2 处理大量数据时,请使用快速复制功能首先将数据引入暂存区,然后使用 SQL DW 计算进行大规模转换。 此方法显著增强了端到端性能。
若要实现此目的,Fast Copy 指示器可指导你将查询拆分为两个部分:数据引入到暂存阶段和使用 SQL DW 计算的大规模转换。 建议尽可能多地将查询的评估推送到快速复制,以用于引入数据。 当快速复制指示器显示快速复制无法执行其余步骤时,可以在启用暂存的情况下拆分查询的其余部分。
步骤诊断指示器
| 指示器 | 图标 | 描述 |
|---|---|---|
| 将评估此步骤能否进行快速复制 | 
|
快速复制指示器会告诉你,到此步骤的查询支持快速复制。 |
| 快速复制不支持此步骤 | 
|
快速复制指示器显示此步骤不支持快速复制。 |
| 快速查询不支持查询中的一个或多个步骤 | 
|
快速复制指示器显示此查询中的某些步骤支持快速复制,而其他步骤则不支持。 若要优化,请拆分查询:黄色步骤(可能由快速复制支持)和红色步骤(不支持)。 |
分步指南
在 Dataflow Gen2 中完成数据转换逻辑后,快速复制指示器将评估每个步骤,以确定有多少步骤可以利用快速复制来提高性能。
在下面的示例中,最后一步显示为红色,指示快速复制不支持带“分组依据”的步骤。 不过,快速复制可以支持前面所有显示为黄色的步骤。
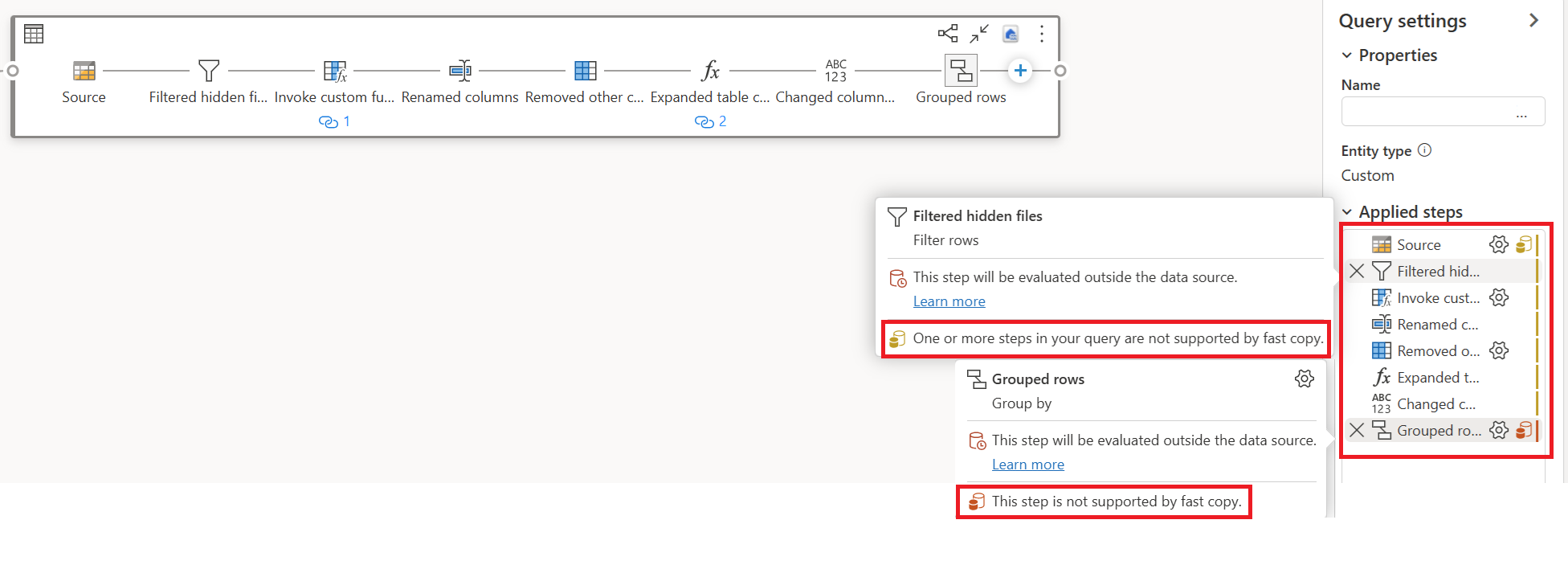
目前,如果直接发布并运行数据流 Gen2,则不会使用快速复制引擎加载数据,如下图所示:

若要使用快速复制引擎并提高数据流 Gen2 的性能,可以将查询拆分为两部分:将数据引入到暂存区和使用 SQL DW 计算进行大规模转换,如下所示:
删除快速复制不支持的转换(显示红色),以及目标(如果已定义)。
快速复制指示器现在显示剩余步骤为绿色,这意味着您的第一个查询可以利用快速复制来提高性能。
为第一个查询选择“操作”,然后选择“启用暂存和引用”。
显示第二个查询的
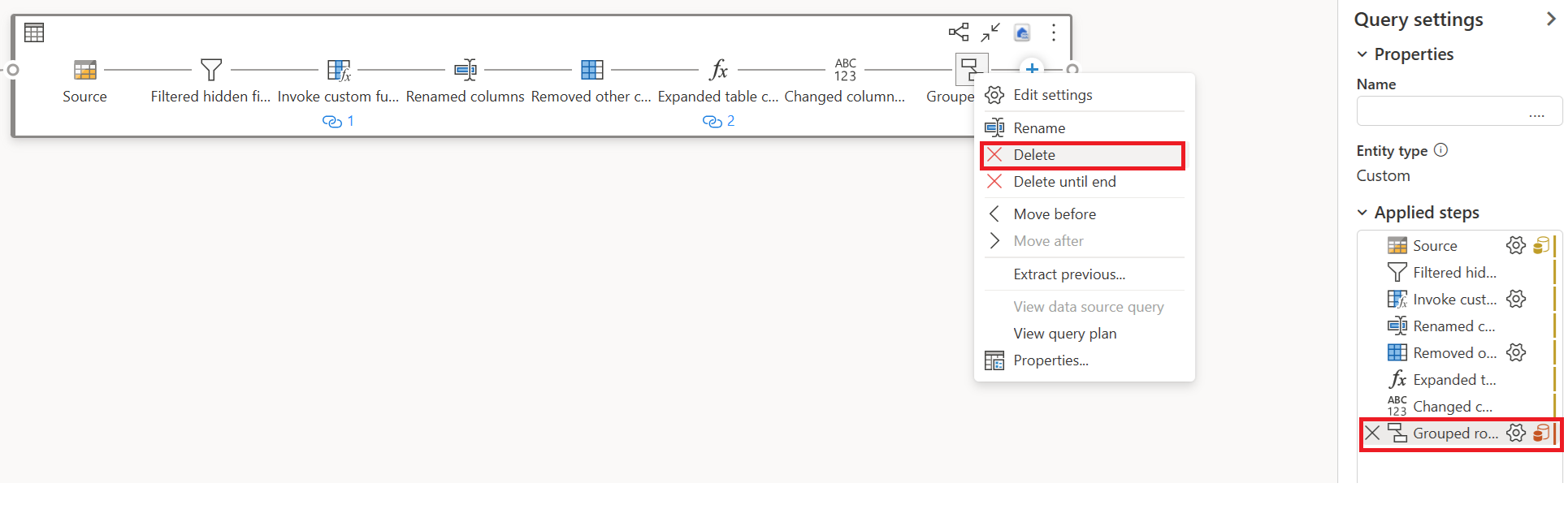
在新引用的查询中,转播了“分组依据”转换和目标(如果适用)。
显示第三个查询的
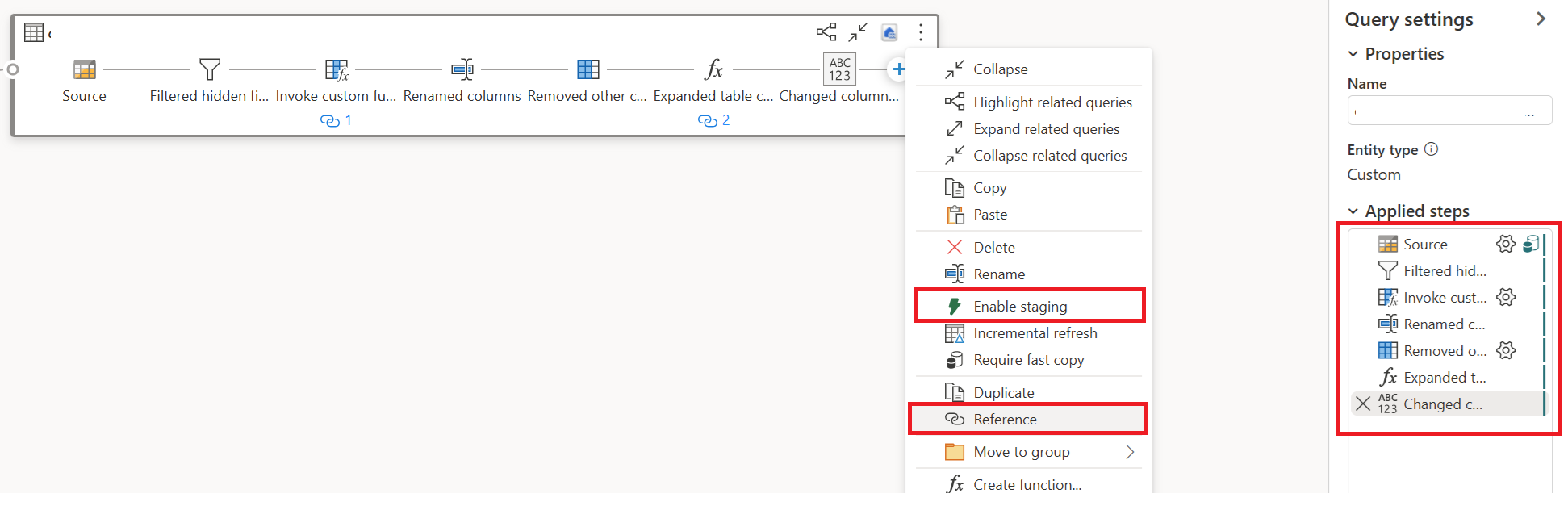
发布和刷新 Dataflow Gen2。 现在,你将在 Dataflow Gen2 中看到两个查询,总体持续时间大大缩短。
第一个查询使用快速复制将数据引入暂存区。
第二个查询使用 SQL DW 计算执行大规模转换。
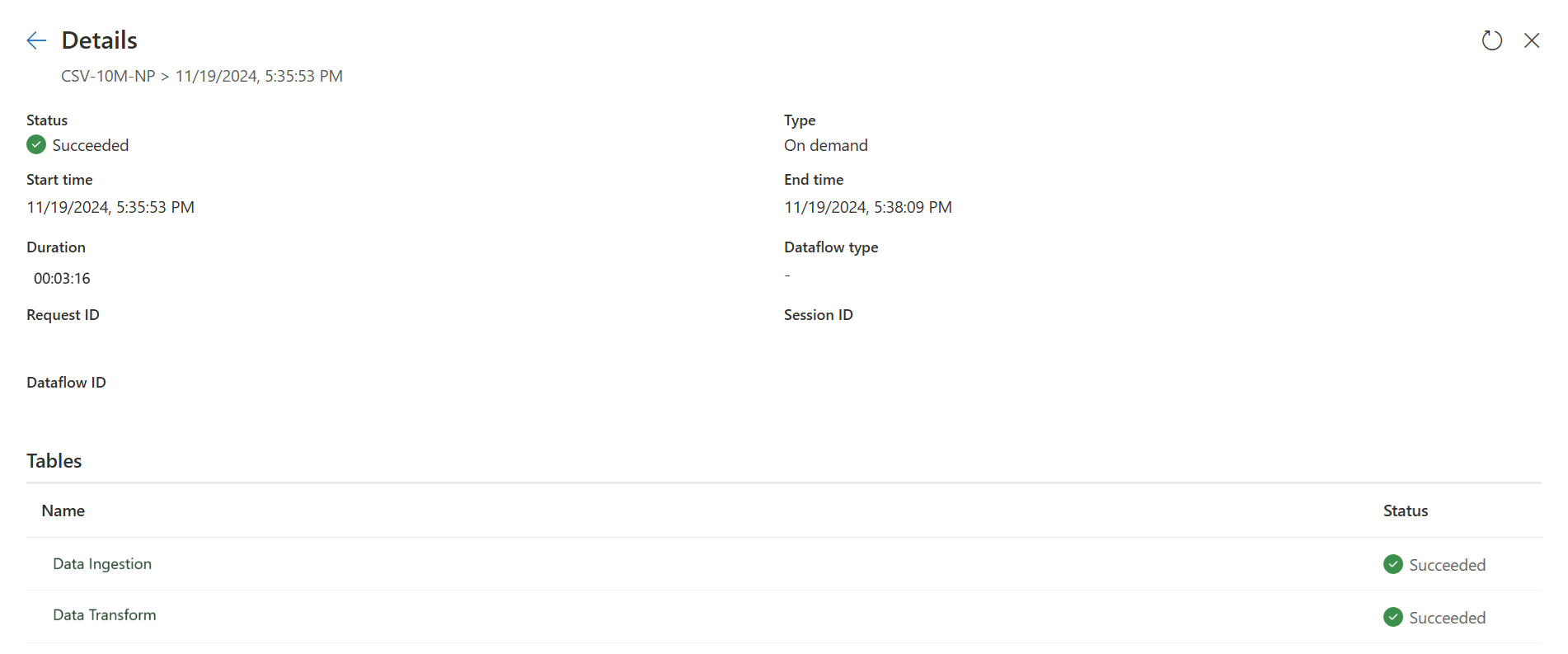
第一个查询:
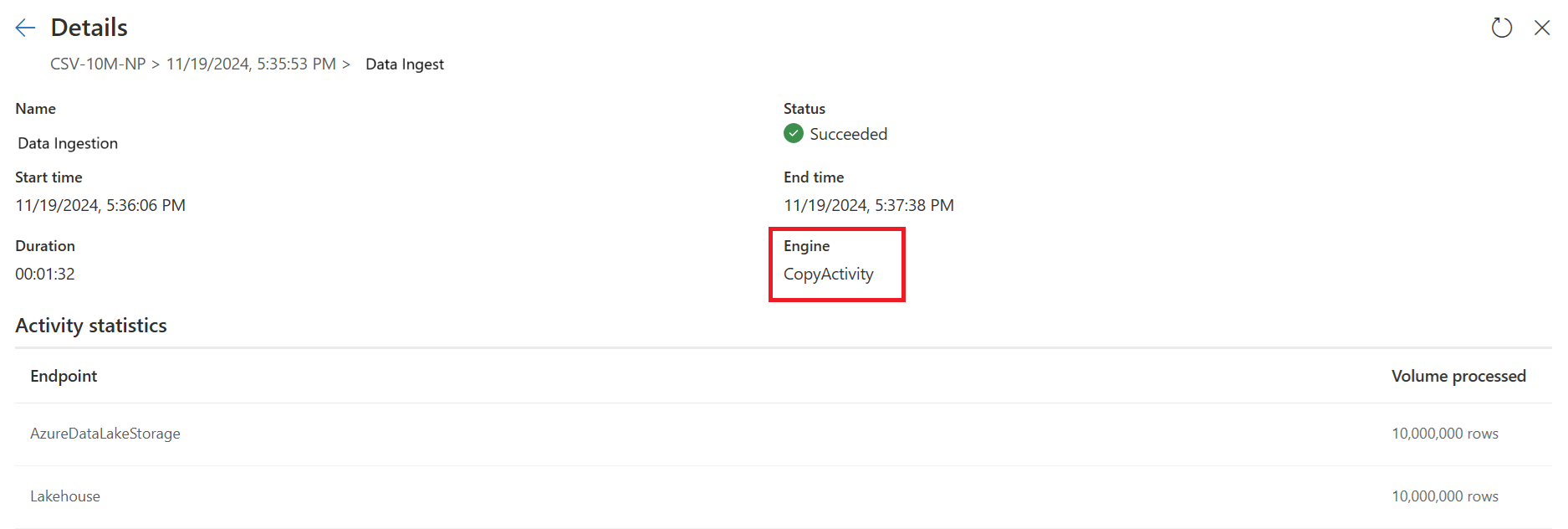
第二个查询:

已知限制
- 要支持快速复制,需要本地数据网关版本 3000.214.2 或更高版本。
- 不支持 VNet 网关。
- 不支持将数据写入湖屋中的现有表。
- 不支持固定架构。