通过运行 Azure Databricks 活动转换数据
Microsoft Fabric 数据工厂中的 Azure Databricks 活动允许协调以下 Azure Databricks 作业:
- 笔记本
- Jar
- Python
本文提供分步演练,介绍如何使用数据工厂界面创建 Azure Databricks 活动。
先决条件
如果要开始,必须满足以下先决条件:
- 具有有效订阅的租户帐户。 免费创建帐户。
- 创建了工作区。
配置 Azure Databricks 活动
若要在管道中使用 Azure Databricks 活动,请完成以下步骤:
配置连接
在工作区中创建新管道。
单击添加管道活动并搜索 Azure Databricks。
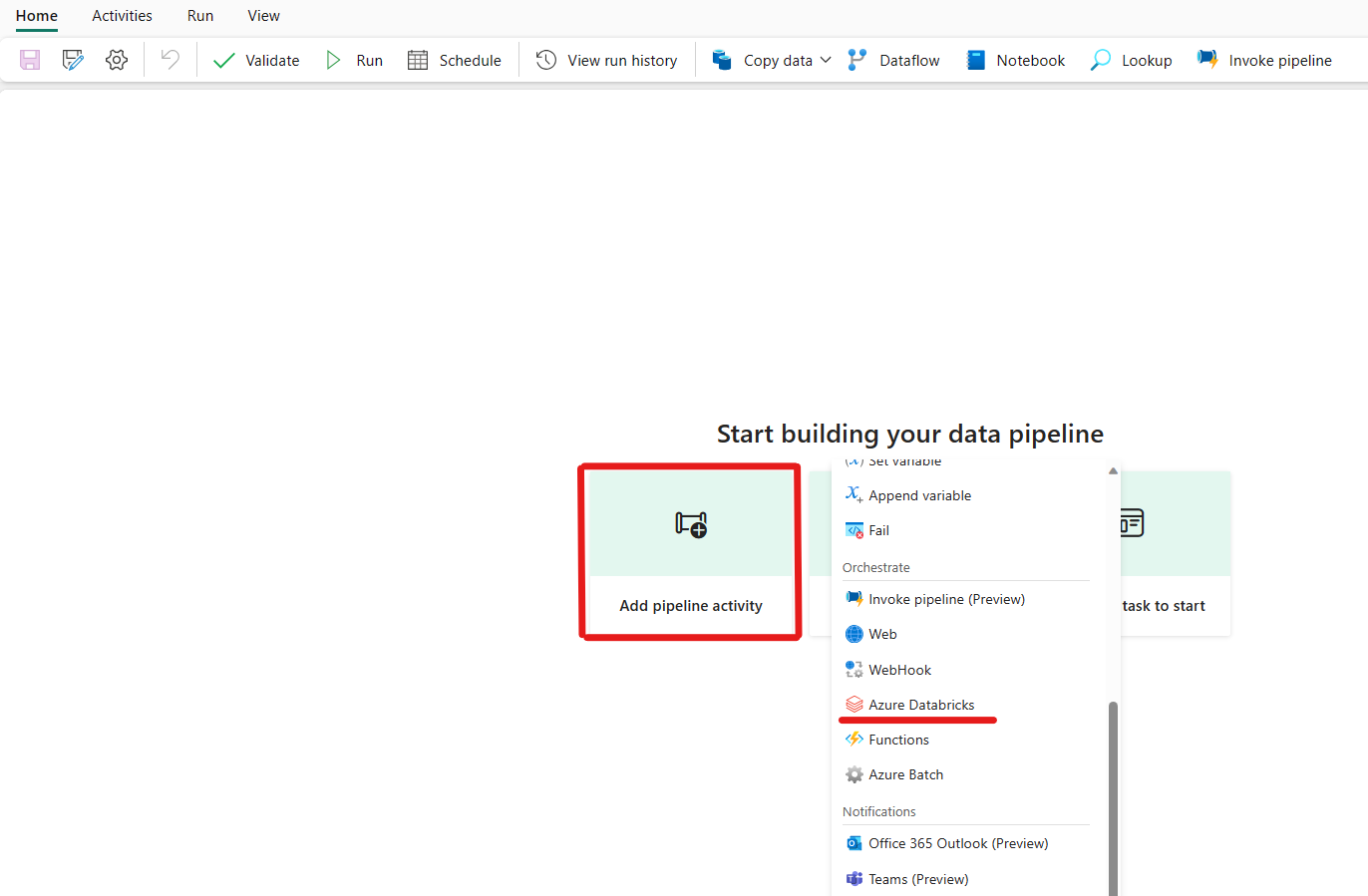
或者,可以在管道“活动”窗格中搜索“Azure Databricks”,然后选择它将其添加到管道画布上。
在画布上选择新 Azure Databricks 活动(如果尚未选择)。
若要配置“常规”设置选项卡,请参阅“常规”设置指导。
配置群集
选择“群集”选项卡。然后,可以选择现有“Azure Databricks 连接”或新建一个,随后选择“新建作业群集”、“现有交互式群集”或“现有实例池”。
根据为群集选择的内容,填写显示的相应字段。
- 在“新建作业群集”和“现有实例池”下,还可以配置辅助角色数并启用现成实例。
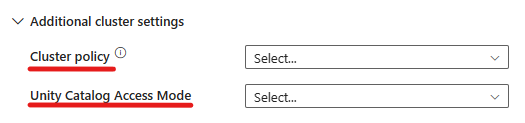
还可以根据要连接的群集的需要指定其他群集设置,例如,“群集策略”、“Spark 配置”、“Spark 环境变量”和“自定义标记”。 还可以在其他群集设置下添加“Databricks init 脚本”和“群集日志目标路径”。
注意
AZURE 数据工厂 Azure Databricks 链接服务中支持的所有高级群集属性和动态表达式现在 Microsoft Fabric 中 Azure Databricks 活动 UI 的“其他群集配置”部分下也支持。 这些属性现在包含在活动 UI 中,可以轻松地与表达式(动态内容)配合使用,无需使用 Azure 数据工厂 Azure Databricks 链接服务中的高级 JSON 规范。
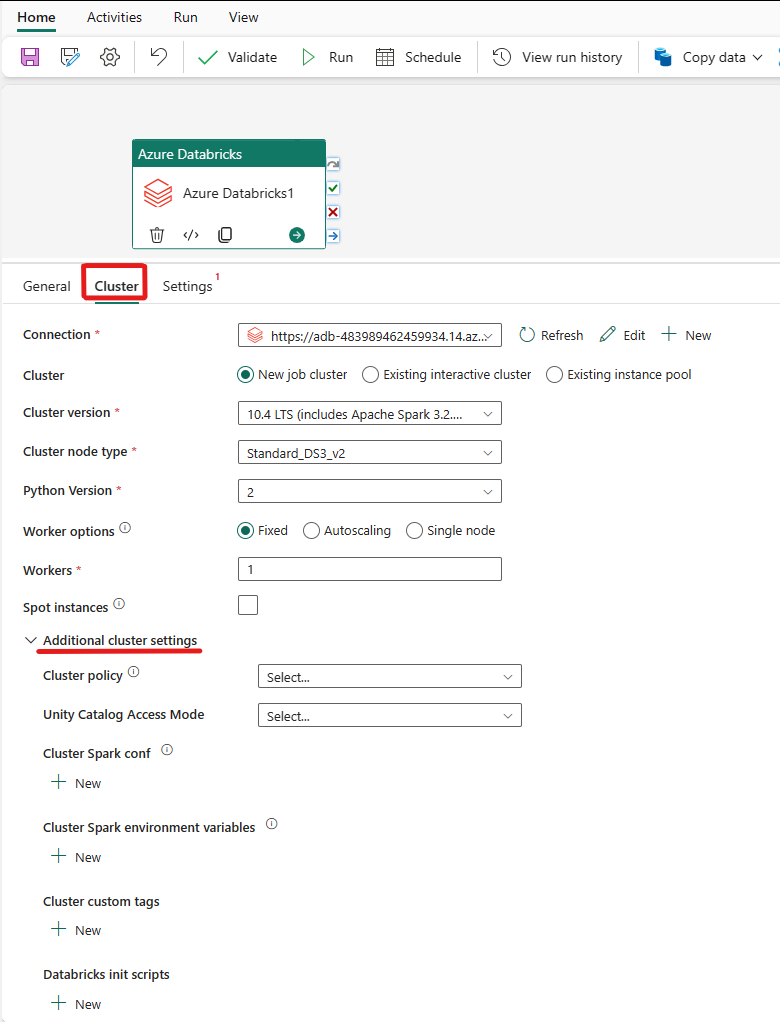
Azure Databricks 活动现在还“支持群集策略和 Unity Catalog”。
- 高级设置下提供了“群集策略”选项,以便你可以指定允许的具体群集配置。
- 此外,高级设置下还提供了配置“Unity Catalog 访问模式”的选项以提高安全性。 可用的访问模式类型包括:
- 单用户访问模式此模式专为单个用户使用每个群集的应用场景而设计。 它确保群集中的数据访问仅限于该用户。 此模式适用于需要隔离和单个数据处理的任务。
- 共享访问模式在此模式下,多个用户可以访问同一群集。 它将 Unity Catalog 的数据治理与旧表访问控制列表 (ACL) 组合在一起。 此模式支持协作数据访问,同时维护治理和安全协议。 但是,它具有特定限制,例如不支持 Databricks Runtime ML、Spark 提交作业以及特定的 Spark API 和 UDF。
- 无访问模式此模式禁用与 Unity Catalog 的交互,这意味着群集无权访问 Unity Catalog 管理的数据。 此模式适用于不需要 Unity Catalog 的治理功能的工作负载。
配置设置
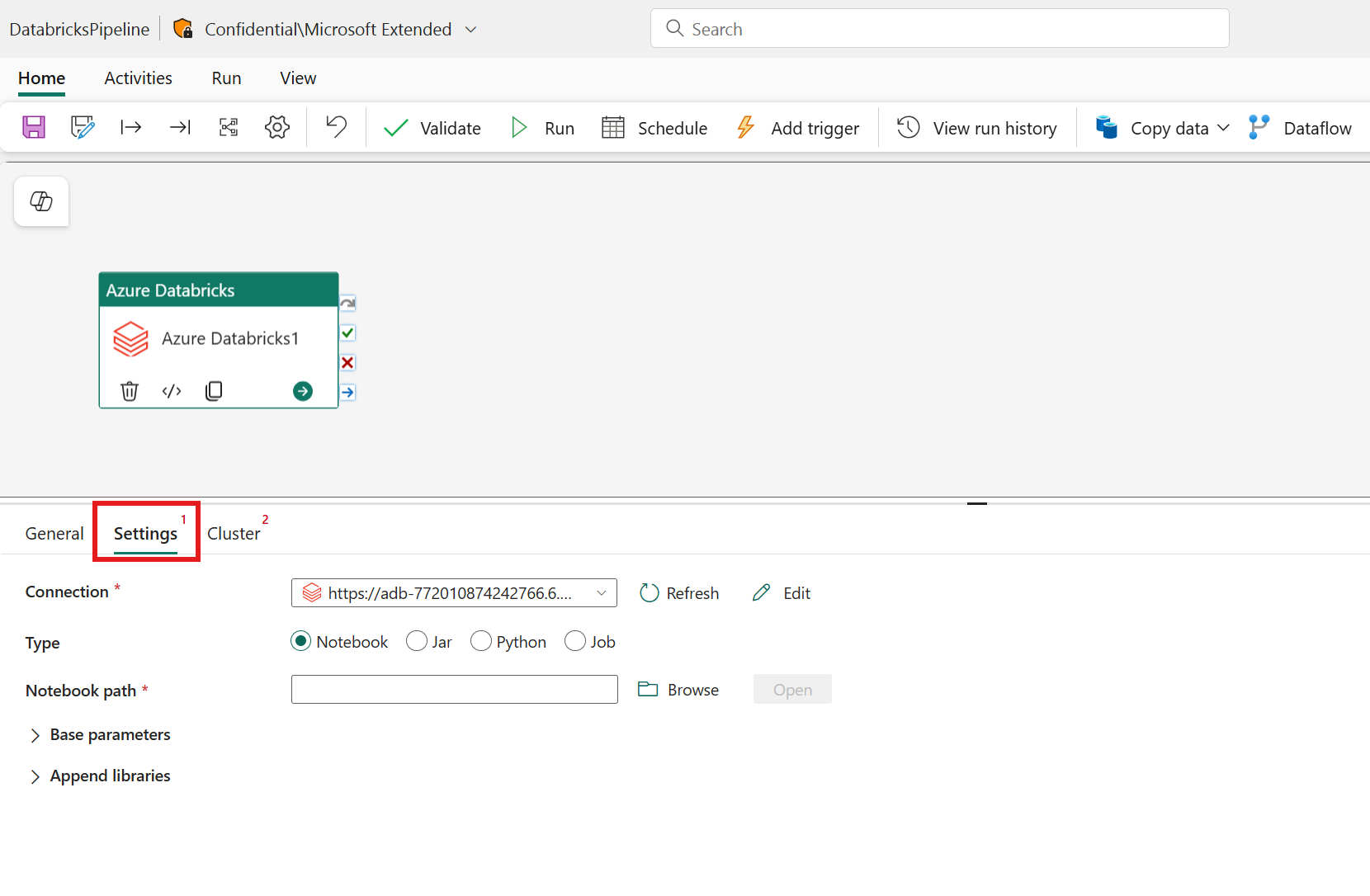
选择“设置”选项卡,可以在要协调的“Azure Databricks 类型”的 3 个选项之间进行选择。
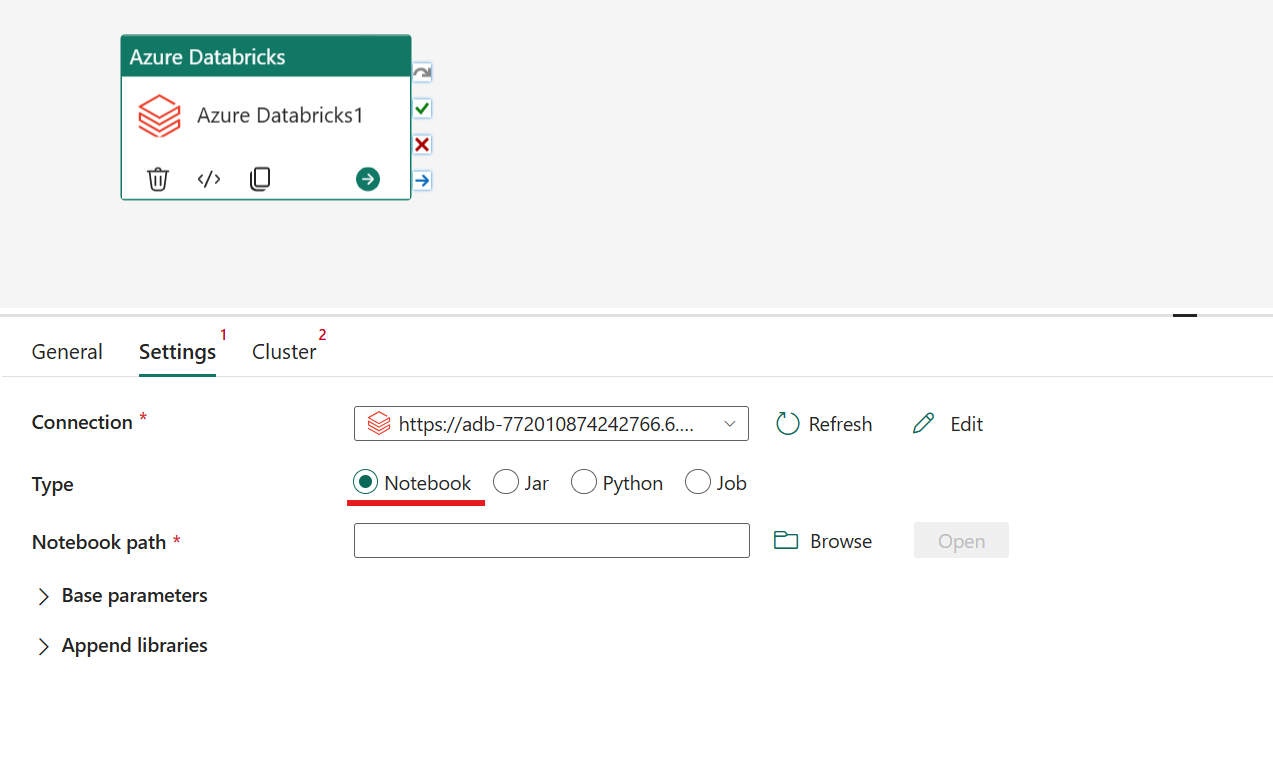
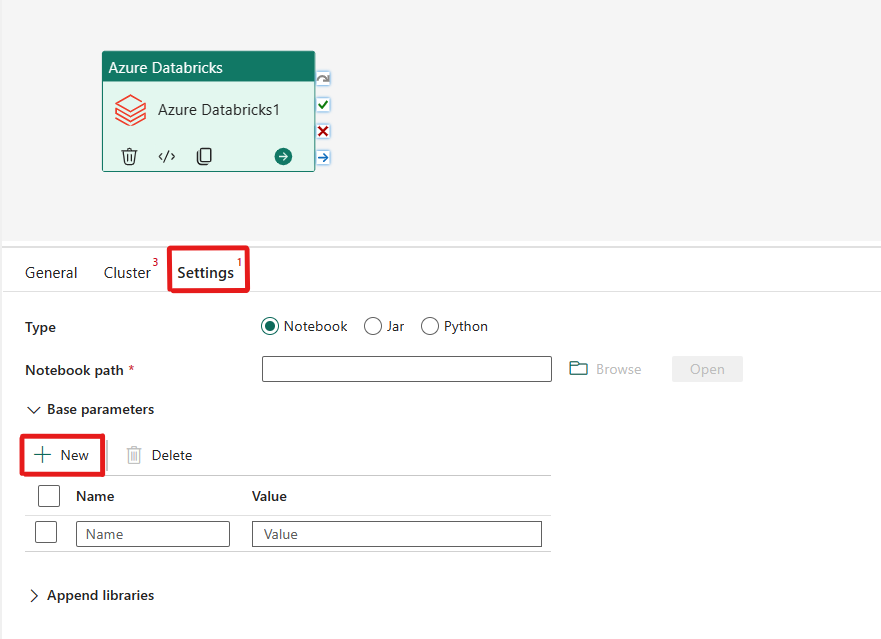
在 Azure Databricks 活动中协调 Notebook 类型:
在“设置”选项卡下,可以选择“Notebook”单选按钮来运行 Notebook。 你需要指定要在 Azure Databricks 上执行的笔记本路径、要传递到笔记本的可选基参数,以及要在群集上安装以执行作业的任何其他库。
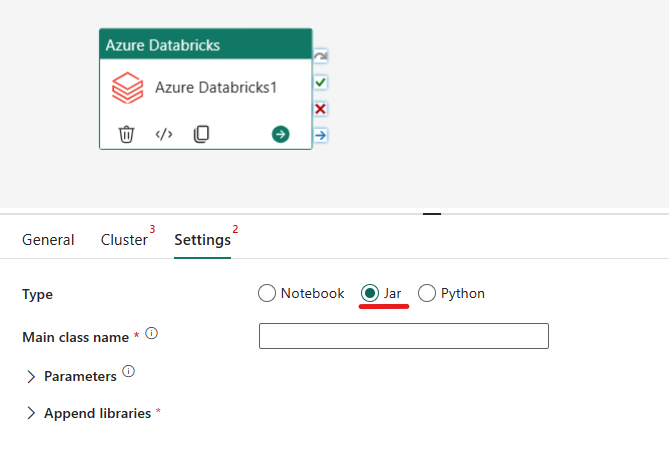
在 Azure Databricks 活动中协调 Jar 类型:
在“设置”选项卡下,可以选择“Jar”单选按钮来运行 Jar。 你需要指定要在 Azure Databricks 上执行的类名、要传递到 Jar 的可选基参数,以及要在群集上安装以执行作业的任何其他库。
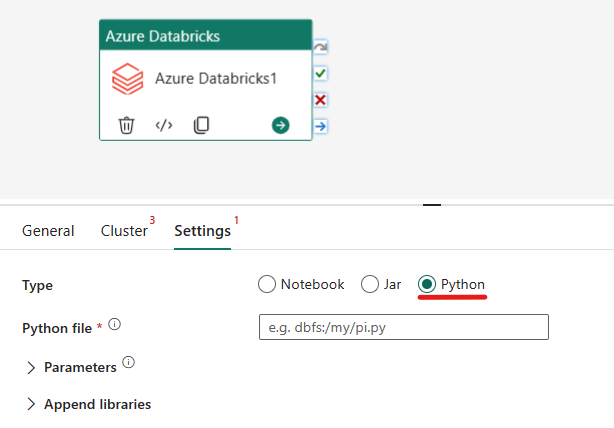
在 Azure Databricks 活动中协调 Python 类型:
在“设置”选项卡下,可以选择“Python”单选按钮来运行 Python 文件。 你需要指定 Azure Databricks 中要执行的 Python 文件的路径、要传递的可选基参数,以及要在群集上安装以执行作业的任何其他库。
Azure Databricks 活动支持的库
在以上 Databricks 活动定义中,可以指定这些库类型:jar、egg、whl、maven、pypi、cran。
有关详细信息,请参阅针对库类型的 Databricks 文档。
在 Azure Databricks 活动和管道之间传递参数
可以使用 Databricks 活动中的 baseParameters 属性将参数传递给笔记本。
在某些情况下,你可能需要将某些值从笔记本传回服务,这些值可用于服务中的控制流(条件检查)或由下游活动使用(大小限制为 2 MB)。
例如,你可以在笔记本中调用 dbutils.notebook.exit("returnValue"),相应的“returnValue”将会返回到服务。
可以使用表达式(如
@{activity('databricks activity name').output.runOutput})在服务中使用该输出。
进行保存,并运行或计划管道
配置管道所需的任何其他活动后,切换到管道编辑器顶部的“主页”选项卡,然后选择“保存”按钮以保存管道。 选择“运行”来直接运行它,或者选择“计划”进行计划。 还可以在此处查看运行历史记录,或者配置其他设置。
