Microsoft Fabric 中的数据工程工作区管理设置
适用于:✅Microsoft Fabric 中的数据工程和数据科学
在 Microsoft Fabric 中创建工作区时,会自动创建与该工作区关联的初学者池。 借助 Microsoft Fabric 中的简化设置,无需选择节点或计算机大小,因为这些选项已在后台为你处理的。 此配置提供更快的(5-10 秒)Apache Spark 会话启动体验,让用户可以在许多常见方案中开始使用和运行 Apache Spark 作业,而无需担心设置计算。 对于具有特定计算要求的高级应用场景,用户可以创建自定义 Apache Spark 池,并根据其性能需求调整节点大小。
要更改工作区中的 Apache Spark 设置,应具有该工作区的管理员角色。 要了解详细信息,请参阅工作区中的角色。
要管理与工作区关联的池的 Spark 设置:
转到工作区中的“工作区设置”,然后选择“数据工程/科学”选项以展开菜单:
左侧菜单中会显示“Spark 计算”选项:
注意
如果将默认池更改为从初学者池更改为自定义 Spark 池,则会话启动时间可能会更长(约 3 分)。

池
工作区的默认池
可以使用自动创建的初学者池,也可以为工作区创建自定义池。
初学者池:自动创建预水化实时池,以便获得更快的体验。 这些群集为中等大小。 初学者池根据购买的 Fabric 容量 SKU 设置为默认配置。 管理员可以根据 Spark 工作负荷缩放要求而自定义节点和执行程序的最大数量。 若要了解详细信息,请参阅配置初学者池
自定义 Spark 池:可以根据 Spark 作业要求调整节点大小、自动缩放和动态分配执行程序。 要创建自定义 Spark 池,容量管理员应在“容量管理员设置”的“Spark 计算”部分中启用“自定义工作区池”选项。
注意
默认情况下,自定义工作区池的容量级别控制处于启用状态。 要了解详细信息,请参阅配置和管理 Fabric 容量的数据工程和数据科学设置。
管理员可以通过选择“新建池”选项来根据计算要求创建自定义 Spark 池。

Apache Spark for Microsoft Fabric 支持单节点群集,允许用户选择最小节点配置 1,在这种情况下,驱动程序和执行程序在一个节点中运行。 这些单节点集群在节点故障期间提供可还原的高可用性,并为计算要求较小的工作负载提供更好的作业可靠性。 此外,还可以为自定义 Spark 池启用或禁用自动缩放。 启用自动缩放后,池将获取用户指定的最大节点限制内的新节点,并在作业执行后停用这些节点,以获得更好的性能。
还可以选择选项,将执行程序动态分配到基于数据量指定的最大边界内自动池中的最佳执行程序数,以提高性能。

详细了解 Apache Spark for Fabric 计算。
- 自定义项的计算配置:作为工作区管理员,你可以允许用户使用环境调整各个项目(如笔记本、Spark 作业定义)的计算配置(会话级别属性,包括驱动程序/执行程序核心、驱动程序/执行程序内存)。
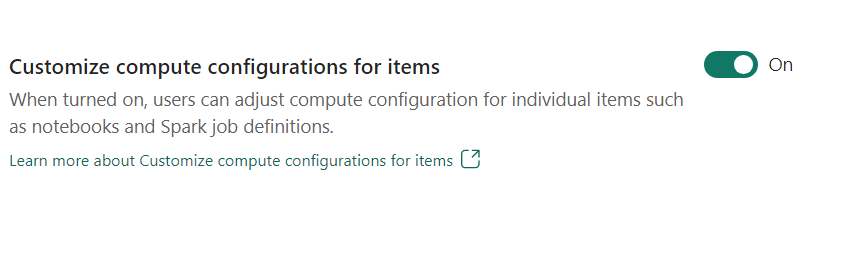
如果工作区管理员关闭了该设置,则默认池及其计算配置将用于工作区中的所有环境。
Environment
环境为运行 Spark 作业(笔记本、Spark 作业定义)提供了灵活的配置。 在环境中,可以配置计算属性,根据工作负荷要求选择不同的运行时、设置库包依赖项。
在“环境”选项卡中,可以选择设置默认环境。 你可以选择要用于工作区的 Spark 版本。
作为 Fabric 工作区管理员,可以选择将某个环境作为工作区默认环境。
还可以通过“环境”下拉列表创建新的环境。

如果禁用设置默认环境的选项,可以选择从下拉列表中列出的可用运行时版本中选择 Fabric 运行时版本。

详细了解 Apache Spark 运行时。
作业
作业设置允许管理员控制工作区中所有 Spark 作业的作业许可逻辑。

默认情况下,所有工作区都启用了乐观作业许可。 详细了解 Microsoft Fabric 中的 Spark 作业许可。
可以启用“为活跃的 Spark 作业保留最大核心数”以关闭基于乐观作业许可的方法,并为他们的 Spark 作业保留最大核心数。
还可以设置 Spark 会话超时,以自定义所有笔记本交互式会话的会话到期时间。
注意
交互式 Spark 会话的默认会话到期时间设置为 20 分钟。
高并发性
高并发模式使用户能够在 Apache Spark for Fabric 数据工程和数据科学工作负载中共享相同的 Spark 会话。 像笔记本这样的项使用 Spark 会话来执行,并且在启用时允许用户在多个笔记本之间共享单个 Spark 会话。

详细了解 Apache Spark for Fabric 中的高并发性。
机器学习模型和试验的自动日志记录
管理员现在可以为其机器学习模型和试验启用自动日志记录。 此选项在训练机器学习模型时会自动捕获输入参数、输出指标和输出项的值。 详细了解自动日志记录。

相关内容
- 阅读 Fabric 中的 Apache Spark 运行时 - 概述、版本控制、多个运行时支持和升级 Delta Lake 协议。
- 有关详细信息,请参阅 Apache Spark 公共文档。
- 查找常见问题解答:Apache Spark 工作区管理设置常见问题解答。