使用 Livy API 提交和执行会话作业
注意
适用于 Fabric 数据工程的 Livy API 目前为预览版。
适用于:✅Microsoft Fabric 中的数据工程和数据科学
使用适用于 Fabric 数据工程的 Livy API 提交 Spark 批处理作业。
先决条件
远程客户端,例如带有 Jupyter Notebooks、PySpark 和适用于 Python 的 Microsoft 身份验证库 (MSAL) 的 Visual Studio Code。
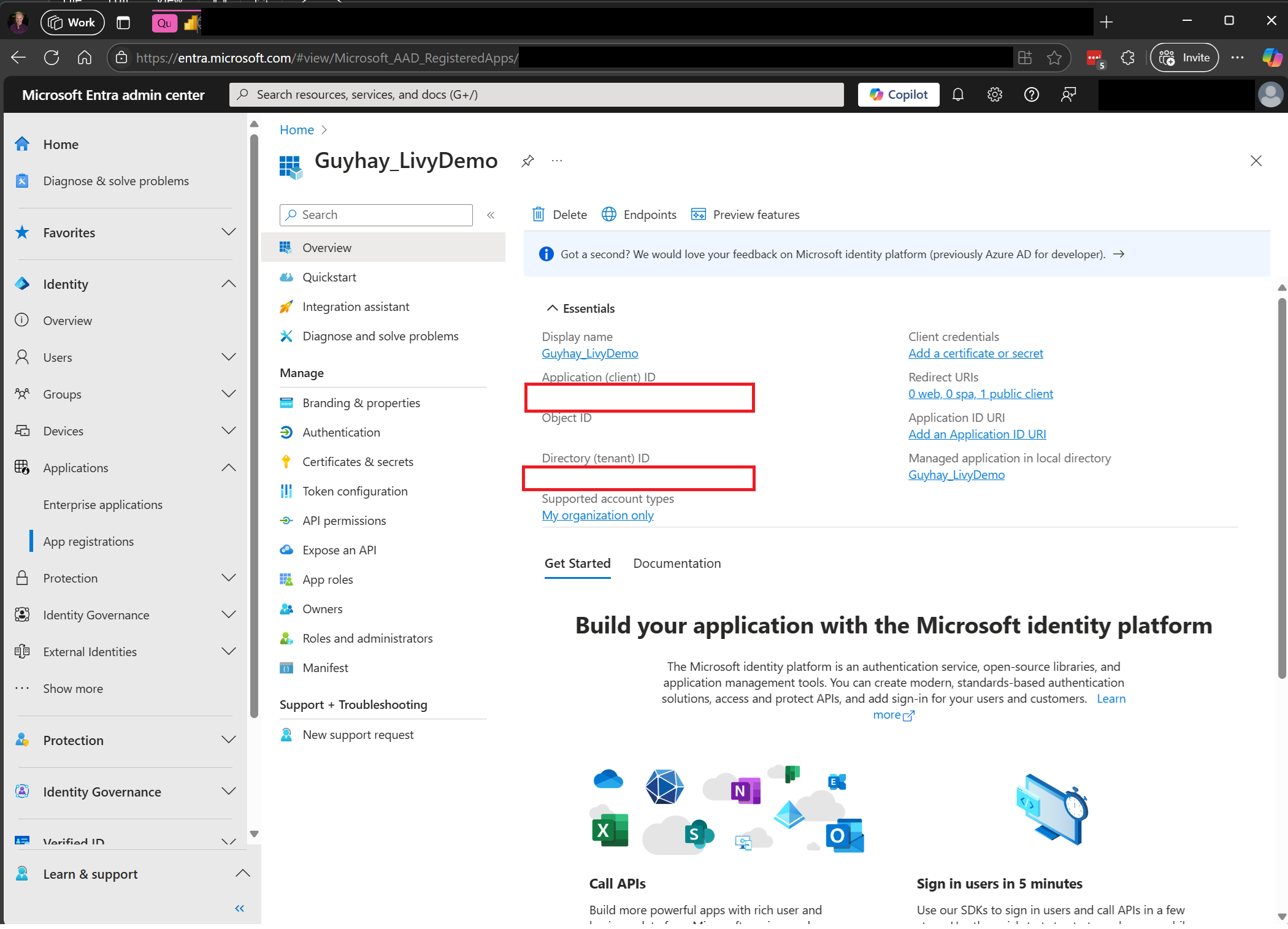
访问 Fabric Rest API 需要 Microsoft Entra 应用令牌。 将应用程序注册到 Microsoft 标识平台。
对于你的湖屋中的一些数据,此示例使用纽约市出租车和豪华轿车委员会 green_tripdata_2022_08,这是加载到湖屋中的一个 parquet 文件。
Livy API 定义用于操作的统一终结点。 按照本文中的示例操作时,请将占位符 {Entra_TenantID}、{Entra_ClientID}、{Fabric_WorkspaceID} 和 {Fabric_LakehouseID} 替换为相应的值。
为 Livy API 会话配置 Visual Studio Code
在 Fabric 湖屋中选择“湖屋设置”。

导航到“Livy 终结点”部分。
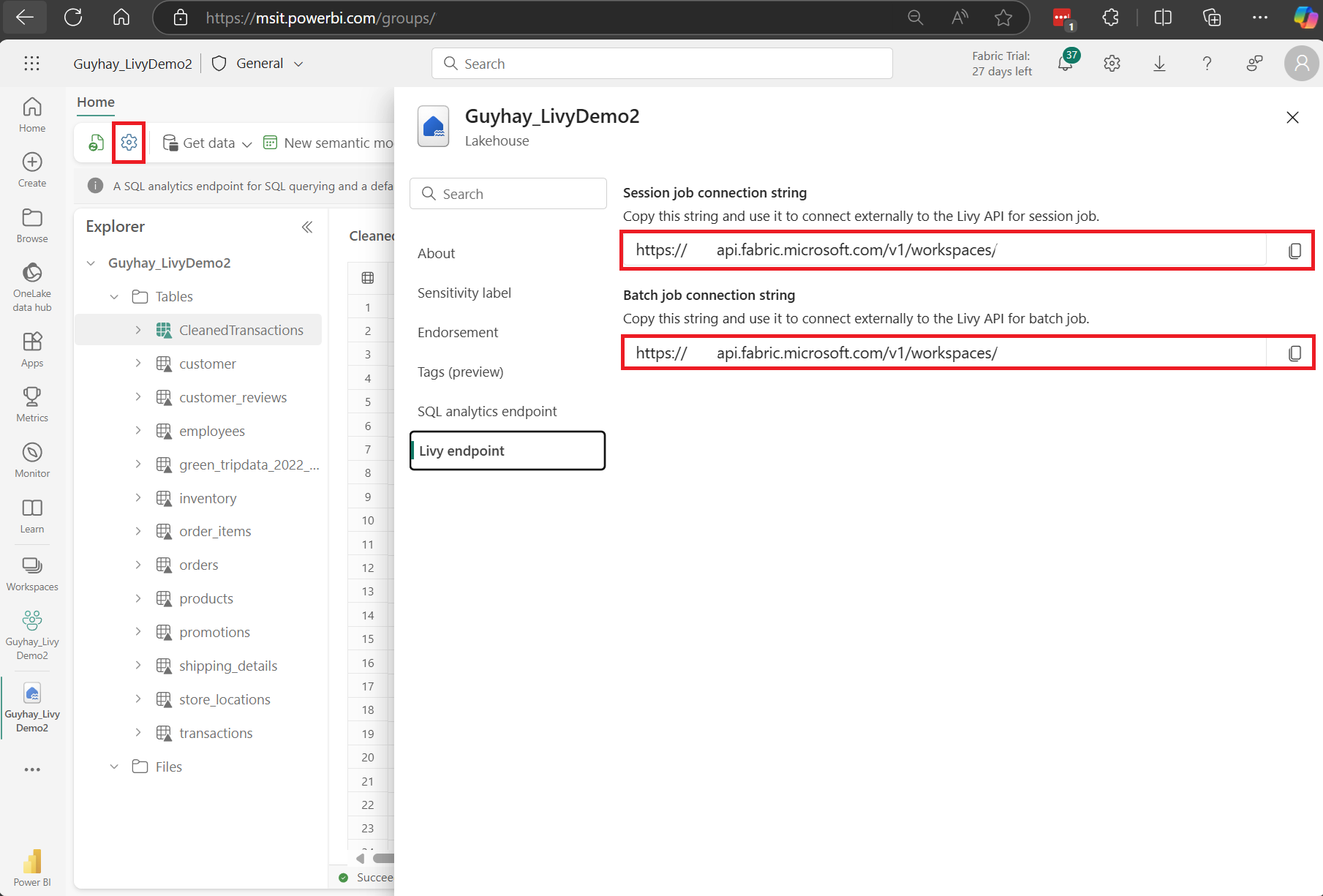
将会话作业连接字符串(图像中的第一个红色框)复制到代码。
导航到 Microsoft Entra 管理中心,并将应用程序(客户端)ID 和目录(租户)ID 复制到代码。



创建 Livy API Spark 会话
在 Visual Studio Code 中创建
.ipynb笔记本并插入以下代码。from msal import PublicClientApplication import requests import time tenant_id = "Entra_TenantID" client_id = "Entra_ClientID" workspace_id = "Fabric_WorkspaceID" lakehouse_id = "Fabric_LakehouseID" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/sessions" headers = {"Authorization": "Bearer " + access_token}运行笔记本单元格,浏览器中应会显示一个弹出窗口,允许选择要登录的身份。
选择要登录的身份后,还需要批准 Microsoft Entra 应用注册 API 权限。
完成身份验证后,请关闭浏览器窗口。

在 Visual Studio Code 中,应会看到返回的 Microsoft Entra 令牌。
添加另一个笔记本单元格并插入此代码。
create_livy_session = requests.post(livy_base_url, headers=headers, json={}) print('The request to create the Livy session is submitted:' + str(create_livy_session.json())) livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers=headers) print(get_session_response.json())运行笔记本单元格,应该会看到在创建 Livy 会话时打印了一行。

可以使用[在监视中心查看作业](#在监视中心查看作业)来验证是否已创建 Livy 会话。





使用 Livy API Spark 会话提交 spark.sql 语句
添加另一个笔记本单元格并插入此代码。
# call get session API livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers=headers) print(get_session_response.json()) while get_session_response.json()["state"] != "idle": time.sleep(5) get_session_response = requests.get(livy_session_url, headers=headers) execute_statement = livy_session_url + "/statements" payload_data = { "code": "spark.sql(\"SELECT * FROM green_tripdata_2022_08 where fare_amount = 60\").show()", "kind": "spark" } execute_statement_response = requests.post(execute_statement, headers=headers, json=payload_data) print('the statement code is submitted as: ' + str(execute_statement_response.json())) statement_id = str(execute_statement_response.json()['id']) get_statement = livy_session_url+ "/statements/" + statement_id get_statement_response = requests.get(get_statement, headers=headers) while get_statement_response.json()["state"] != "available": # Sleep for 5 seconds before making the next request time.sleep(5) print('the statement code is submitted and running : ' + str(execute_statement_response.json())) # Make the next request get_statement_response = requests.get(get_statement, headers=headers) rst = get_statement_response.json()['output']['data']['text/plain'] print(rst)运行笔记本单元格,你应该会看到在作业提交和结果返回时打印出的几条递增的行。
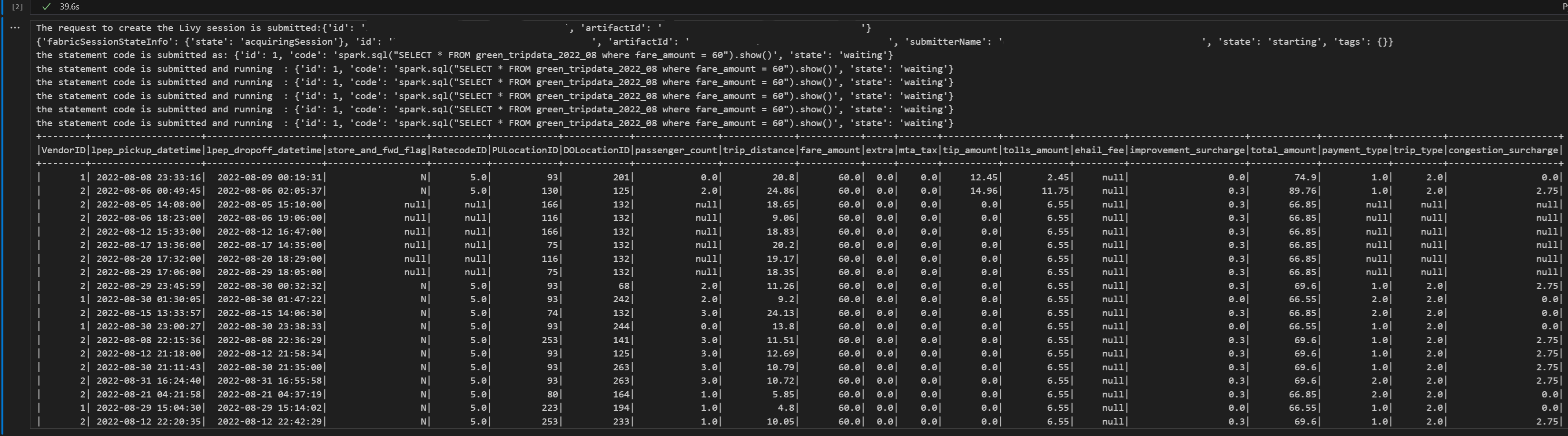

使用 Livy API Spark 会话提交第二个 spark.sql 语句
添加另一个笔记本单元格并插入此代码。
# call get session API livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers=headers) print(get_session_response.json()) while get_session_response.json()["state"] != "idle": time.sleep(5) get_session_response = requests.get(livy_session_url, headers=headers) execute_statement = livy_session_url + "/statements" payload_data = { "code": "spark.sql(\"SELECT * FROM green_tripdata_2022_08 where tip_amount = 10\").show()", "kind": "spark" } execute_statement_response = requests.post(execute_statement, headers=headers, json=payload_data) print('the statement code is submitted as: ' + str(execute_statement_response.json())) statement_id = str(execute_statement_response.json()['id']) get_statement = livy_session_url+ "/statements/" + statement_id get_statement_response = requests.get(get_statement, headers=headers) while get_statement_response.json()["state"] != "available": # Sleep for 5 seconds before making the next request time.sleep(5) print('the statement code is submitted and running : ' + str(execute_statement_response.json())) # Make the next request get_statement_response = requests.get(get_statement, headers=headers) rst = get_statement_response.json()['output']['data']['text/plain'] print(rst)运行笔记本单元格,你应该会看到在作业提交和结果返回时打印出的几条递增的行。
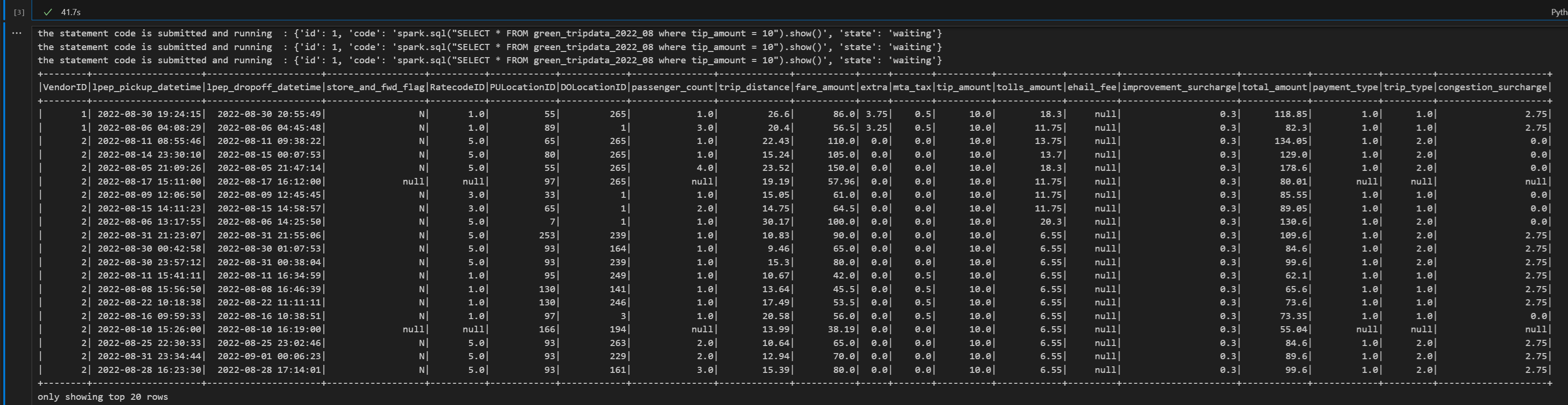

使用第三个语句关闭 Livy 会话
添加另一个笔记本单元格并插入此代码。
# call get session API with a delete session statement get_session_response = requests.get(livy_session_url, headers=headers) print('Livy statement URL ' + livy_session_url) response = requests.delete(livy_session_url, headers=headers) print (response)
在监视中心查看作业
可以通过在左侧导航链接中选择“监视”来访问监视中心,以查看各种 Apache Spark 活动。
当会话正在进行或处于完成状态后,可以通过导航到“监视”来查看会话状态。
选择并打开最新活动名称。
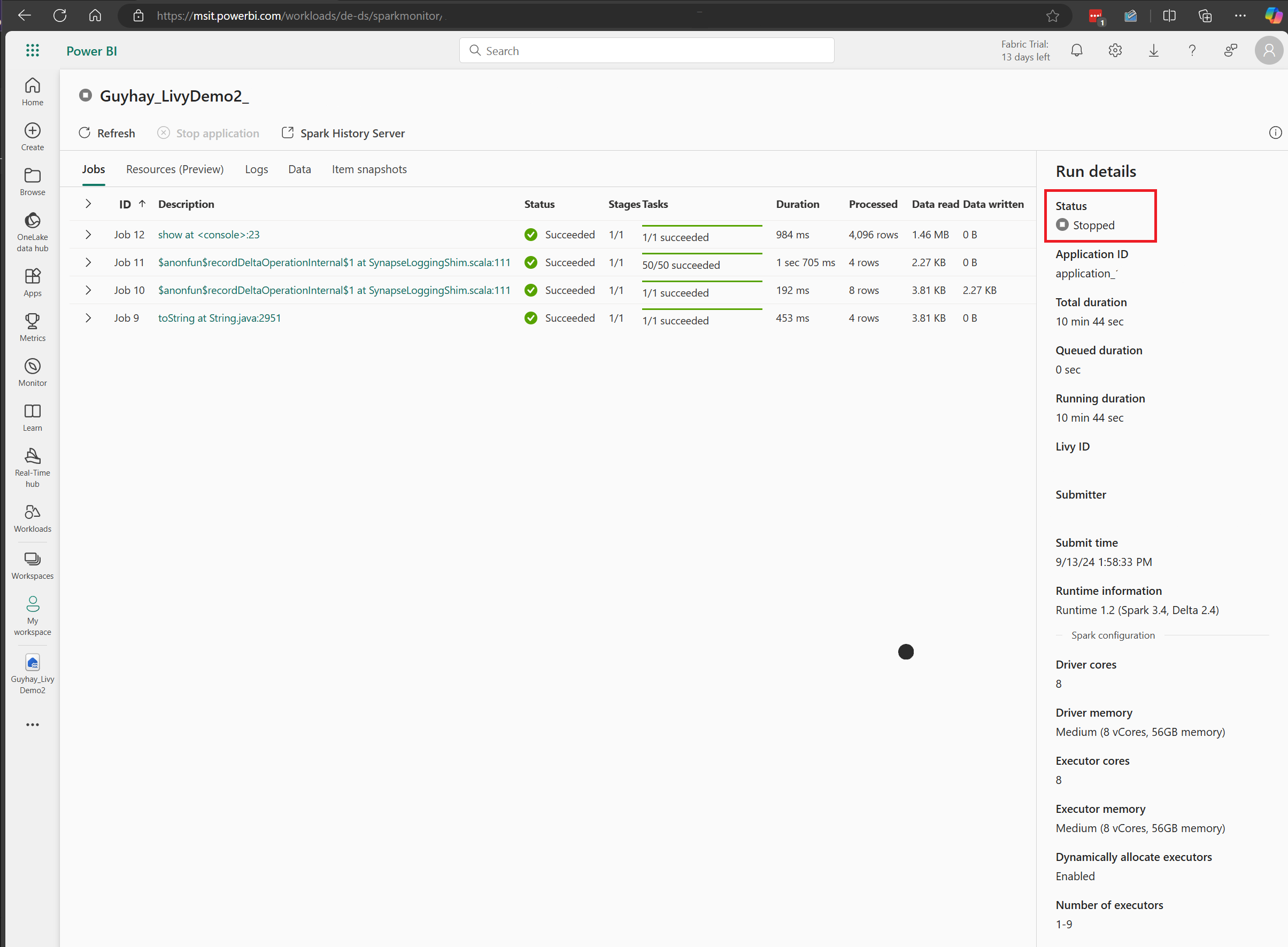
在此 Livy API 会话案例中,可以看到以前的会话提交、运行详细信息、Spark 版本和配置。 请注意右上角的已停止状态。

若要回顾整个过程,需要一个远程客户端(例如 Visual Studio Code)、Microsoft Entra 应用令牌、Livy API 终结点 URL、针对湖屋的身份验证以及会话 Livy API。