使用 Livy API 提交和执行 Livy 批处理作业
注意
适用于 Fabric 数据工程的 Livy API 目前为预览版。
适用于:✅Microsoft Fabric 中的数据工程和数据科学
使用适用于 Fabric 数据工程的 Livy API 提交 Spark 批处理作业。
先决条件
远程客户端,例如带有 Jupyter Notebooks、PySpark 和适用于 Python 的 Microsoft 身份验证库 (MSAL) 的 Visual Studio Code。
访问 Fabric Rest API 需要 Microsoft Entra 应用令牌。 将应用程序注册到 Microsoft 标识平台。
对于你的湖屋中的一些数据,此示例使用纽约市出租车和豪华轿车委员会 green_tripdata_2022_08,这是加载到湖屋中的一个 parquet 文件。
Livy API 定义用于操作的统一终结点。 按照本文中的示例操作时,请将占位符 {Entra_TenantID}、{Entra_ClientID}、{Fabric_WorkspaceID} 和 {Fabric_LakehouseID} 替换为相应的值。
为 Livy API 批处理配置 Visual Studio Code
在 Fabric 湖屋中选择“湖屋设置”。

导航到“Livy 终结点”部分。
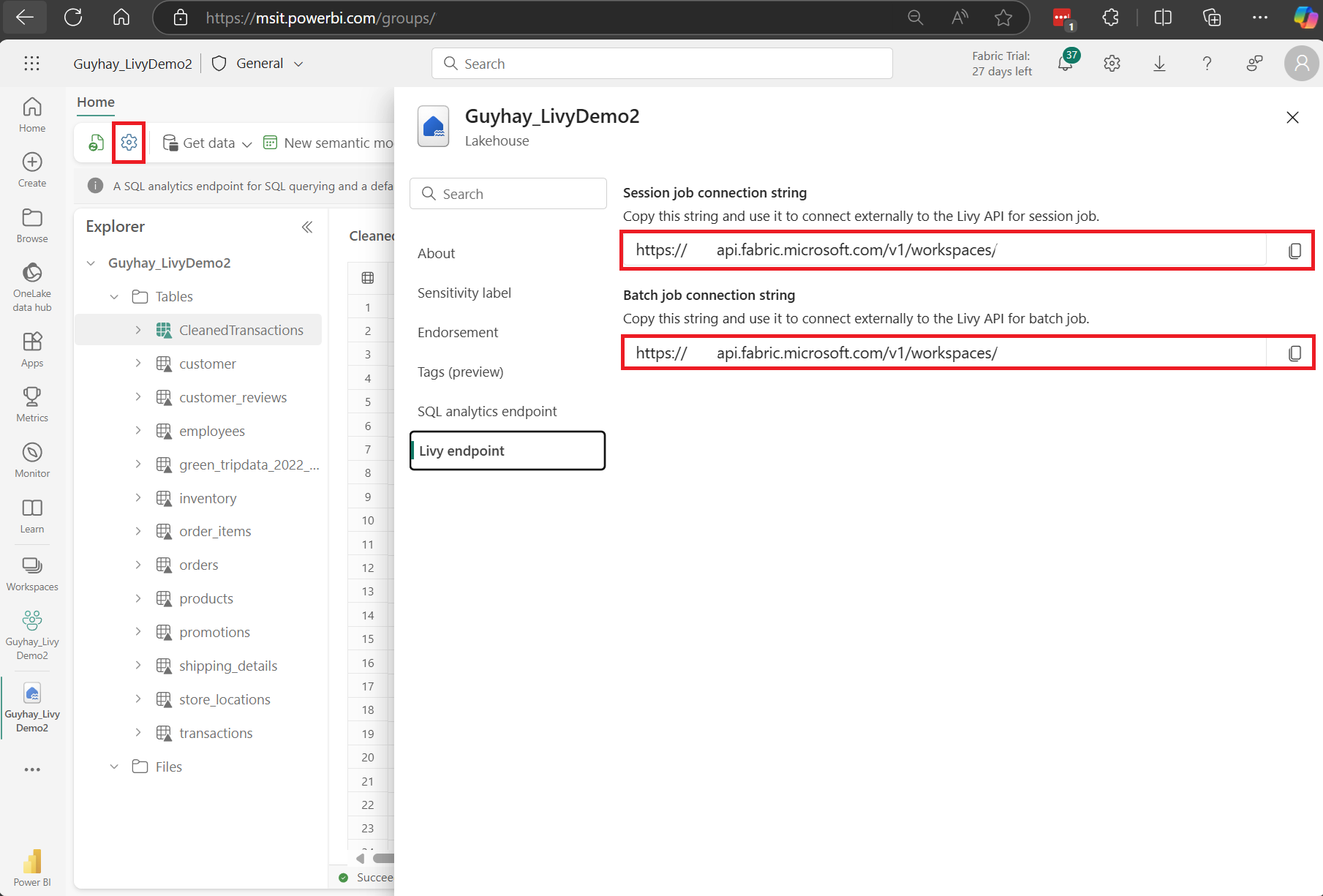
将批处理作业连接字符串(图像中的第二个红色框)复制到代码。
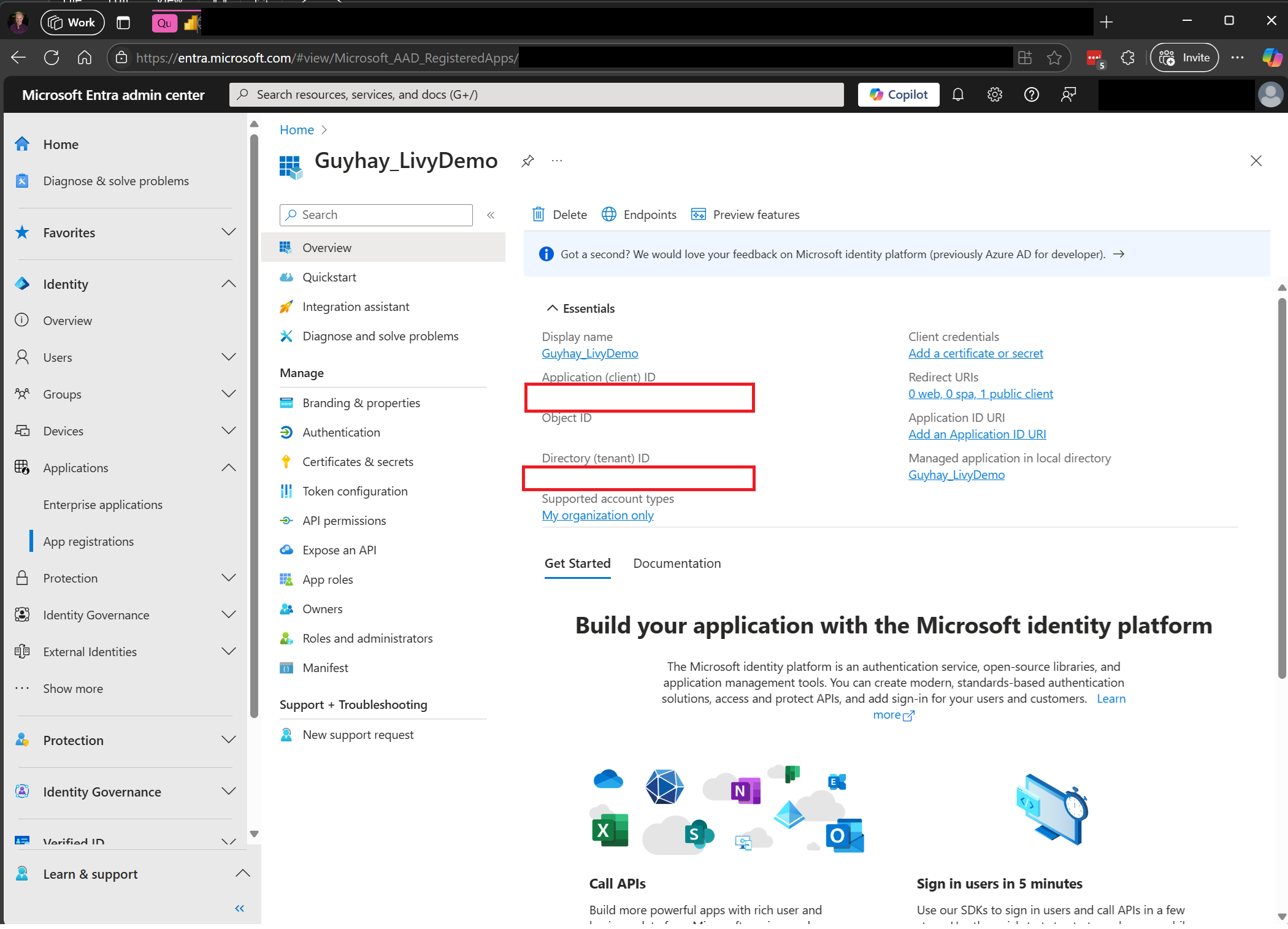
导航到 Microsoft Entra 管理中心,并将应用程序(客户端)ID 和目录(租户)ID 复制到代码。



创建 Spark 有效负载并上传到湖屋
在 Visual Studio Code 中创建
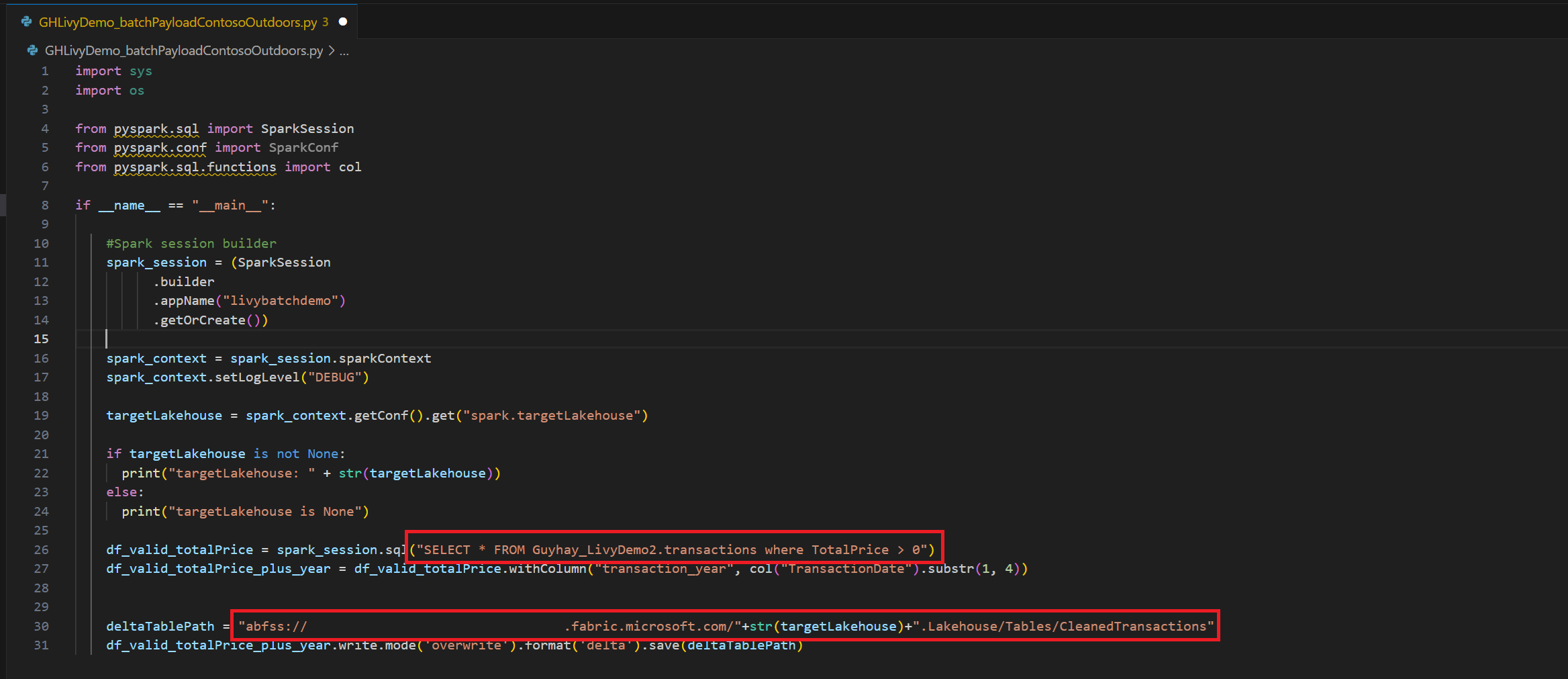
.ipynb笔记本并插入以下代码import sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM <YourLakeHouseDataTableName>.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)在本地保存 Python 文件。 此 Python 代码有效负载包含两个处理湖屋中数据的 Spark 语句,需要上传到你的湖屋。 你将需要有效负载的 ABFS 路径,以便在 Visual Studio Code 中的 Livy API 批处理作业中引用,并需要 Lakehouse 表名称,以便在 Select SQL 语句中引用。
将 Python 有效负载上传到湖屋的“文件”部分。 > 获取数据 > 上传文件 > 单击“文件/”输入框。
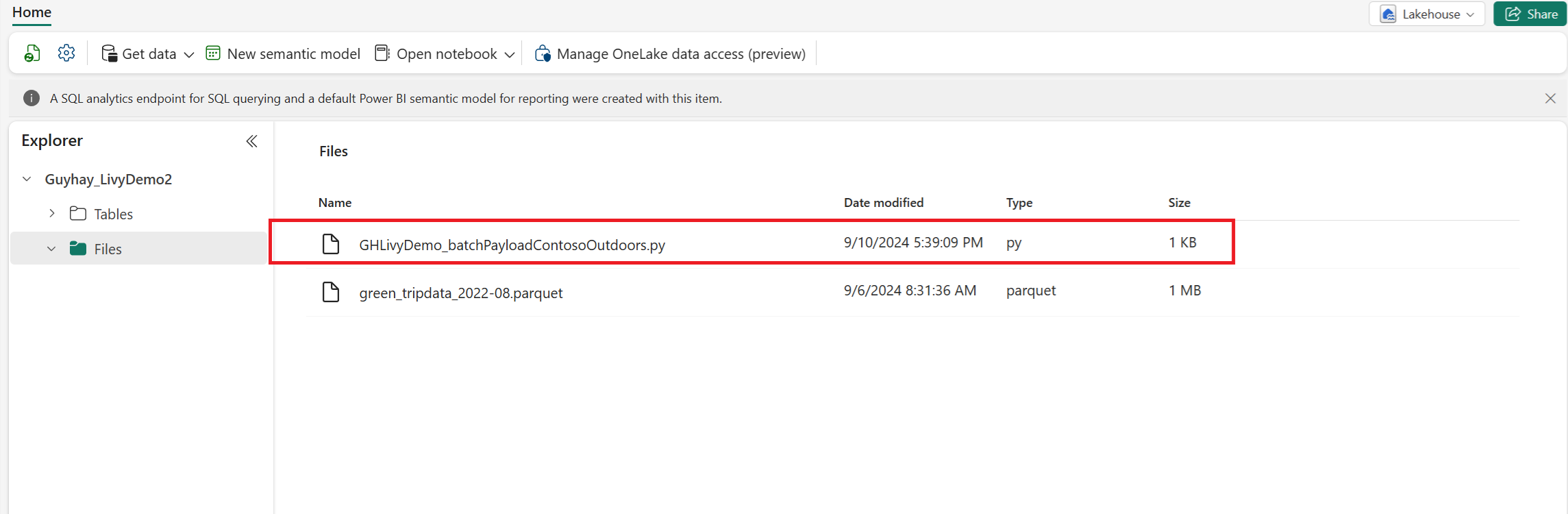
在文件位于湖屋的“文件”部分中后,请单击有效负载文件名右侧的三个点并选择“属性”。
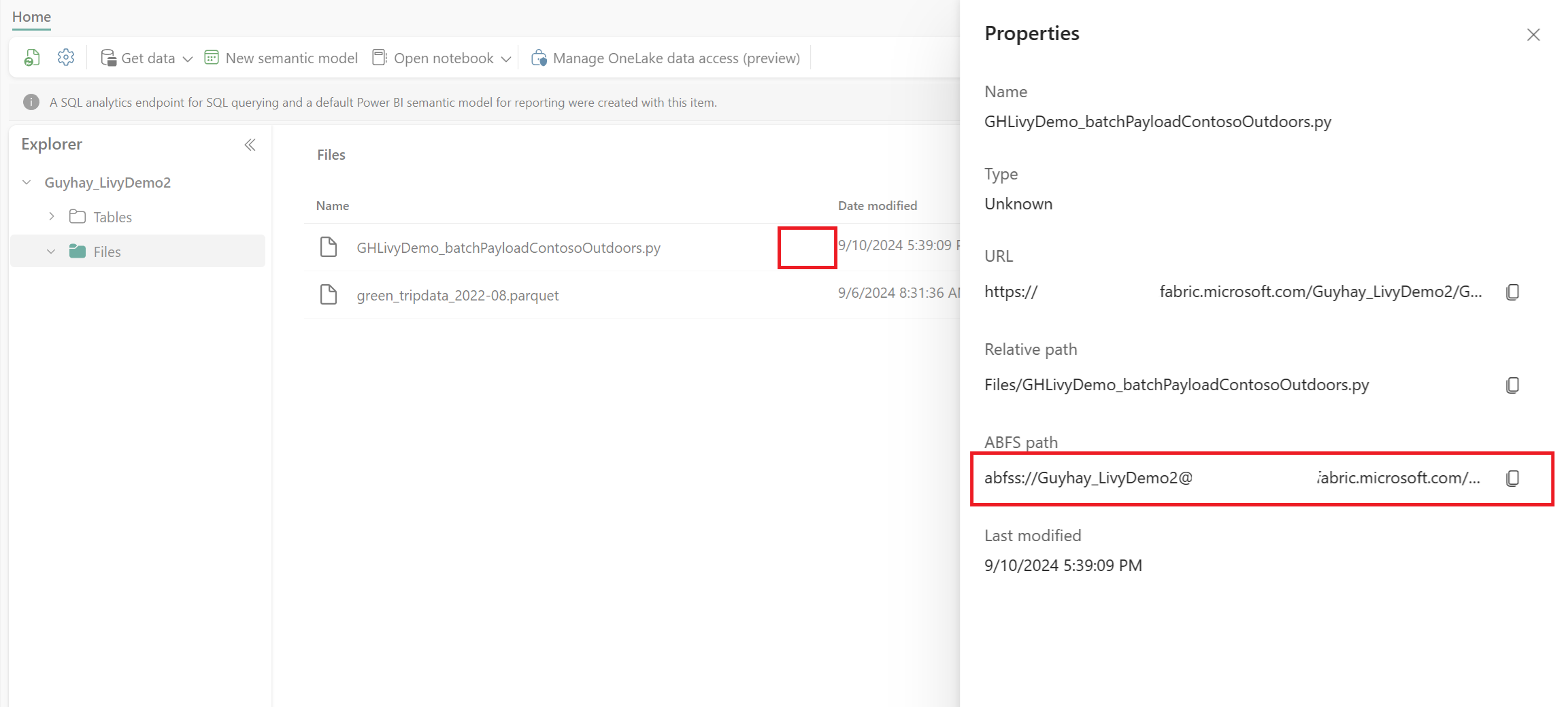
将此 ABFS 路径复制到步骤 1 中的笔记本单元格。



创建 Livy API Spark 批处理会话
在 Visual Studio Code 中创建
.ipynb笔记本并插入以下代码。from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}运行笔记本单元格,浏览器中应会显示一个弹出窗口,允许选择要登录的身份。
选择要登录的身份后,还需要批准 Microsoft Entra 应用注册 API 权限。
完成身份验证后,请关闭浏览器窗口。

在 Visual Studio Code 中,应会看到返回的 Microsoft Entra 令牌。
添加另一个笔记本单元格并插入此代码。
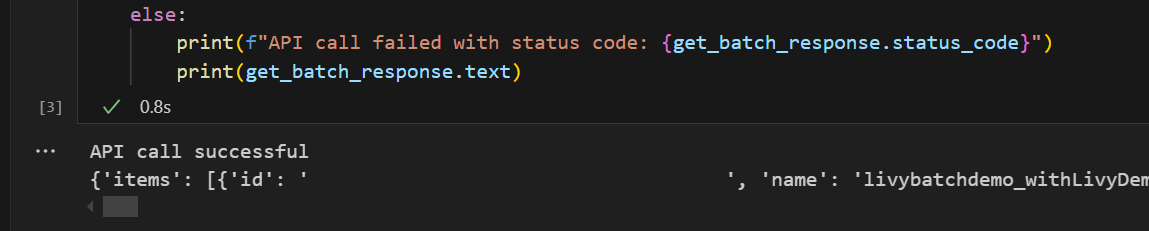
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)运行笔记本单元,应该会看到在创建 Livy 批处理作业时打印了两行。





使用 Livy API 批处理会话提交 spark.sql 语句
添加另一个笔记本单元格并插入此代码。
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())运行笔记本单元格,应会看到在创建并运行 Livy 批处理作业时打印了几行。

导航回湖屋以查看更改。

在监视中心查看作业
可以通过在左侧导航链接中选择“监视”来访问监视中心,以查看各种 Apache Spark 活动。
批处理作业处于完成状态后,可以通过导航到“监视”来查看会话状态。
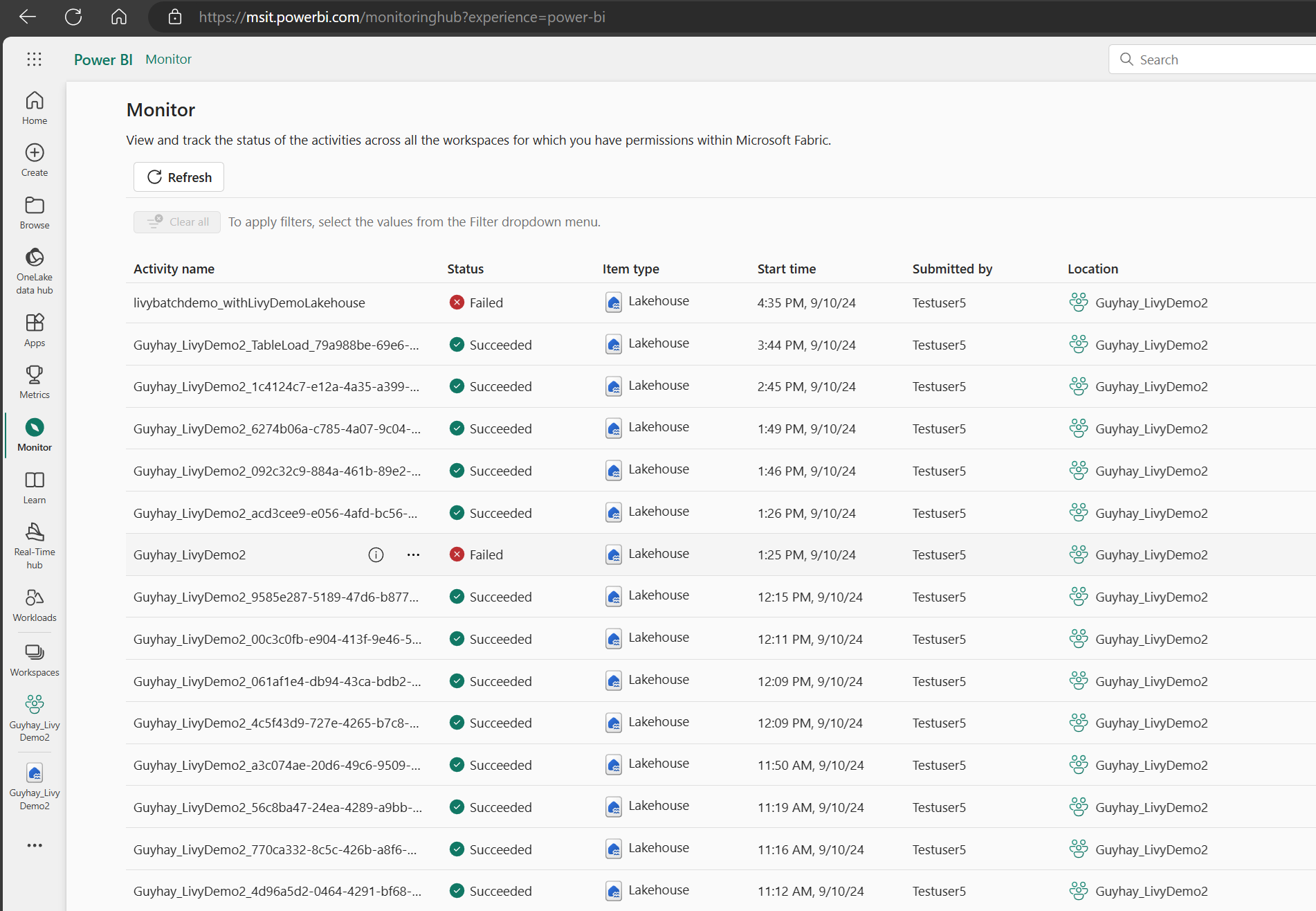
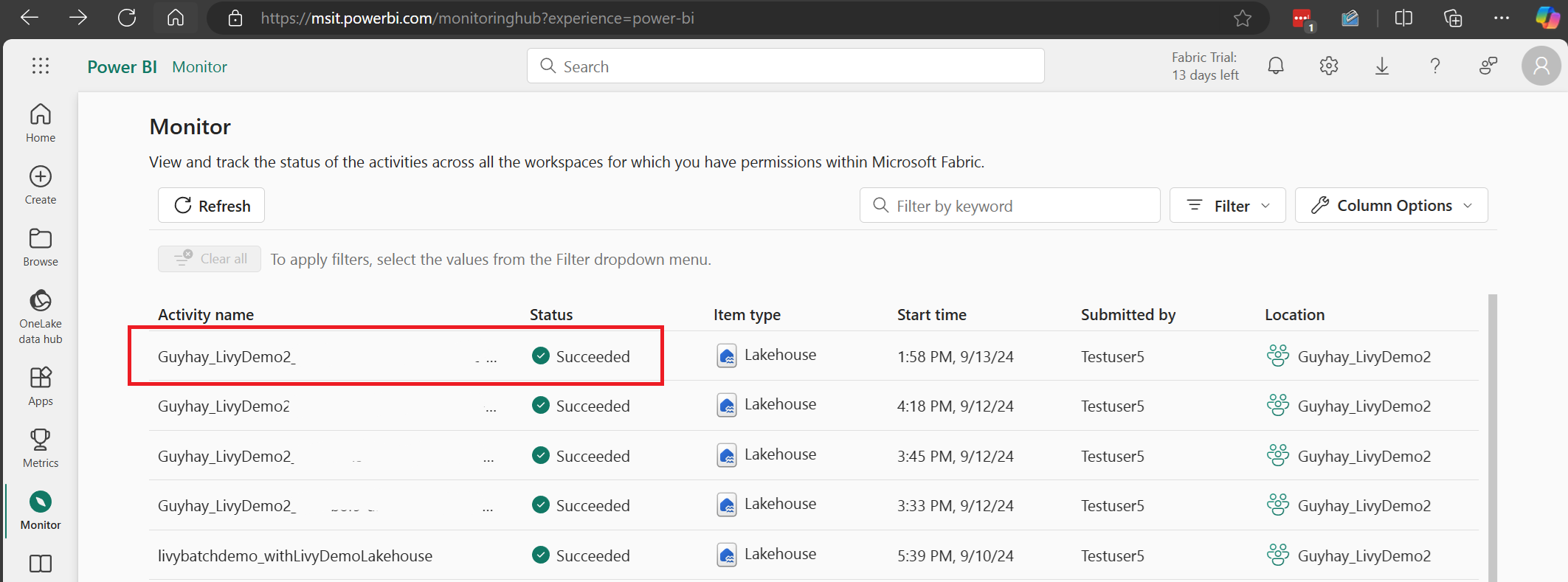
选择并打开最新活动名称。
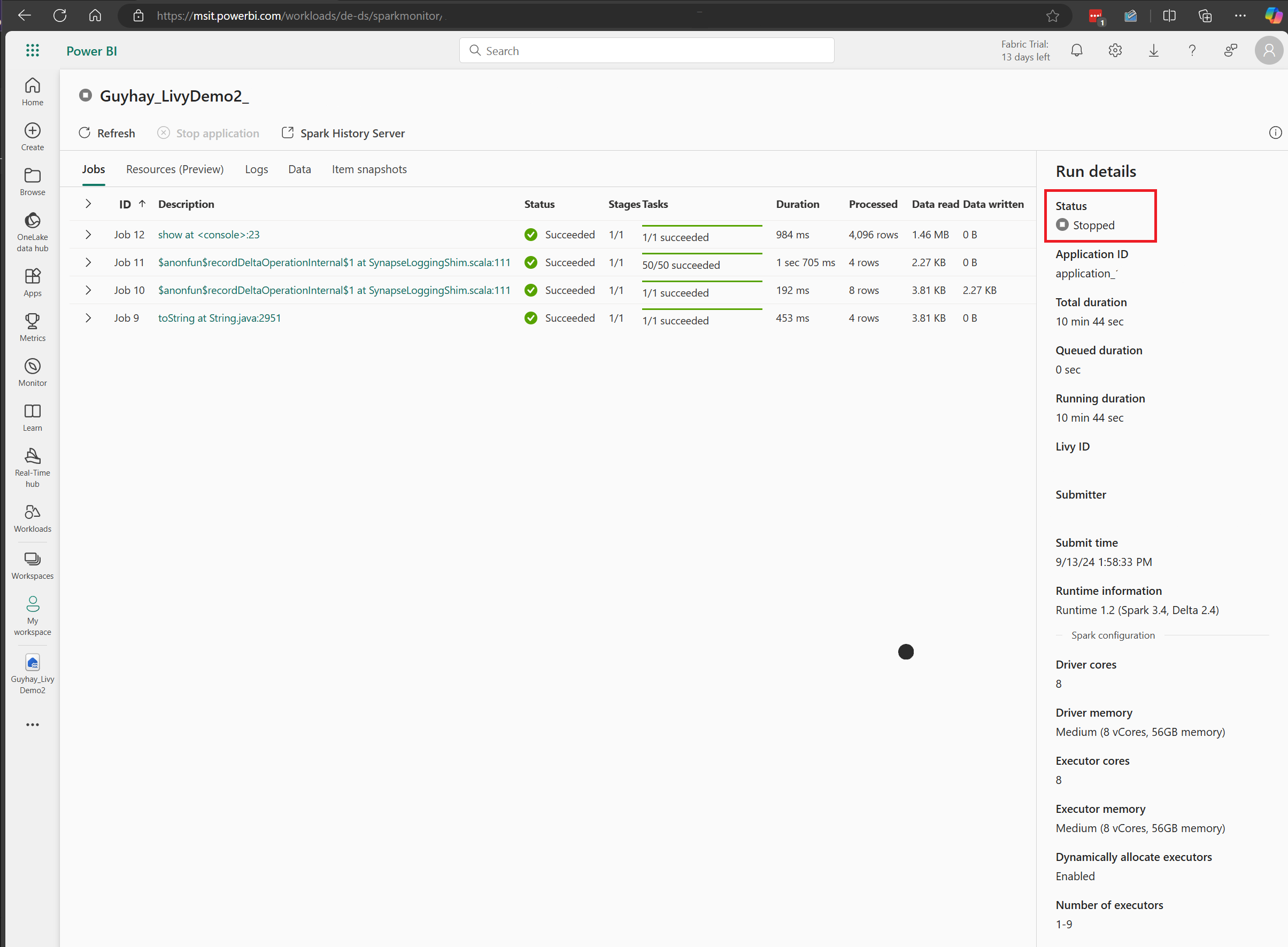
在此 Livy API 会话案例中,可以看到以前的批处理提交、运行详细信息、Spark 版本和配置。 请注意右上角的已停止状态。



若要回顾整个过程,需要一个远程客户端(例如 Visual Studio Code)、Microsoft Entra 应用令牌、Livy API 终结点 URL、针对湖屋的身份验证、湖屋中的 Spark 有效负载以及批处理 Livy API 会话。