连接到 Azure Data Lake Storage 中的 Common Data Model 表
备注
Azure Active Directory 现已更名为 Microsoft Entra ID。 了解更多
使用 Azure Data Lake Storage 帐户使用 Common Data Model 表将数据引入 Dynamics 365 Customer Insights - Data。 数据引入可以是完整的或增量的。
先决条件
Azure Data Lake Storage 帐户必须已启用分层命名空间。 数据必须以分层文件夹格式存储,该格式定义根文件夹,每个表都有子文件夹。 子文件夹可以有完整数据或增量数据文件夹。
要使用 Microsoft Entra 服务主体进行身份验证,请确保已在您的租户中配置它。 有关详细信息,请参阅使用 Microsoft Entra 服务主体连接到 Azure Data Lake Storage 帐户。
要连接到受防火墙保护的存储,请设置 Azure 专用链接。
如果数据湖当前有任何专用链接连接到它, Customer Insights - Data 则无论网络访问设置如何,也必须使用专用链接进行连接。
您要从其连接和引入数据的 Azure Data Lake Storage 必须与 Dynamics 365 Customer Insights 环境位于同一 Azure 区域中,并且订阅必须在同一租户中。 不支持从不同的 Azure 区域中的 Data Lake 连接到 Common Data Model 文件夹。 要了解该环境的 Azure 区域,请在 Customer Insights - Data 中转到设置>系统>关于。
联机服务中存储的数据可以存储在与处理或存储数据不同的位置。 导入或连接到联机服务中存储的数据即表示您同意传输数据。 在 Microsoft 信任中心了解更多信息。
Customer Insights - Data 服务主体必须具有以下角色之一才能访问存储帐户。 有关详细信息,请参阅向服务主体授予访问存储帐户的权限。
- 存储 Blob 数据读取器
- 存储 Blob 数据负责人
- 存储 Blob 数据参与者
使用 Azure 订阅选项连接到 Azure 存储时,设置数据源连接的用户至少需要存储帐户的存储 Blob 数据参与者权限。
使用 Azure 资源选项连接到 Azure 存储时,设置数据源连接的用户至少需要存储帐户的 Microsoft.Storage/storageAccounts/read 操作权限。 包含此操作的 Azure 内置角色是读者角色。 要限制仅访问必要的操作,创建仅包含此操作的 Azure 自定义角色。
为了获得最佳性能,分区的大小应小于或等于 1 GB,并且文件夹中的分区文件数不能超过 1000。
Data Lake Storage 中的数据应遵循 Common Data Model 标准来存储数据,并应具有 Common Data Model 清单来表示数据文件的架构(*.csv 或 *.parquet)。 清单必须提供表的详细信息,如表列和数据类型,以及数据文件位置和文件类型。 有关详细信息,请参阅 Common Data Model 清单。 如果清单不存在,具有存储 Blob 数据负责人或存储 Blob 数据参与者访问权限的管理员用户可以在引入数据时定义架构。
备注
如果 .parquet 文件中的任何字段的数据类型为 Int96,这些数据可能不会在表页面上显示。 我们建议使用标准数据类型,如 Unix 时间戳格式(它将时间表示为自 1970 年 1 月 1 日午夜 (UTC) 以来的秒数)。
限制
- Customer Insights - Data 不支持精度大于 16 的小数类型列。
连接到 Azure Data Lake Storage
数据连接名称、数据路径(如容器中的文件夹)和表名称必须使用以字母开头的名称。 名称只能包含字母、数字和下划线 (_)。 不支持使用特殊字符。
转到数据>数据源。
选择添加数据源。
选择 Azure Data Common Data Model 表。

输入数据源名称和说明(可选)。 此名称将在下游流程中引用,在创建数据源后无法更改。
为连接存储使用的是选择以下选项之一。 有关详细信息,请参阅使用 Microsoft Entra 服务主体连接到 Azure Data Lake Storage 帐户。
- Azure 资源:输入资源 ID。
- Azure 订阅:选择订阅,然后选择资源组和存储帐户。
备注
您需要容器的以下角色之一来创建数据源:
- 存储 Blob 数据读取器足以从存储帐户读取数据并将数据引入 Customer Insights - Data。
- 如果您要直接在 Customer Insights - Data 中编辑清单文件,则必须是存储 Blob 数据参与者或负责人。
在存储帐户中具有此角色将在其所有容器上提供相同的角色。
选择包含要从中导入数据的数据和架构(model.json 或 manifest.json 文件)的容器的名称。
备注
与环境中其他数据源相关联的任何 model.json 或 manifest.json 文件都不会显示在列表中。 但是,相同的 model.json 或 manifest.json 文件可用于多个环境中的数据源。
或者,如果要通过 Azure 专用链接从存储帐户引入数据,选择启用专用链接。 有关详细信息,请转到专用链接。
要创建新架构,请转到创建新架构文件。
要使用现有架构,请导航到包含 model.json 或 manifest.cdm.json 文件的文件夹。 您可以在目录中搜索来查找该文件。
选择 json 文件,然后选择下一步。 可用表列表将显示。
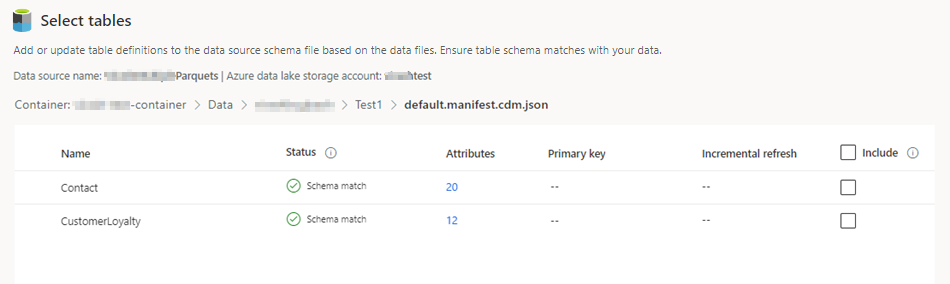
选择要包括的表。
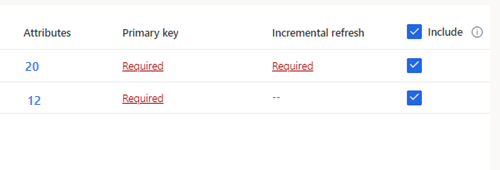
小费
要在 JSON 编辑界面中编辑表,选择表,然后选择编辑架构文件。 进行更改,然后选择保存。
对于未定义主键的选定表,主键下将显示必需。 对于每个表:
- 选择必需。 编辑表面板将显示。
- 选择主键。 主键是表所特有的属性。 若要使属性成为有效主键,它不应包括重复值、缺少值或 null 值。 支持将字符串、整数和 GUID 数据类型属性作为主键。
- 或者,更改分区模式。
- 选择关闭保存并关闭面板。
为每个包含的表选择列数量。 管理属性页面将显示。
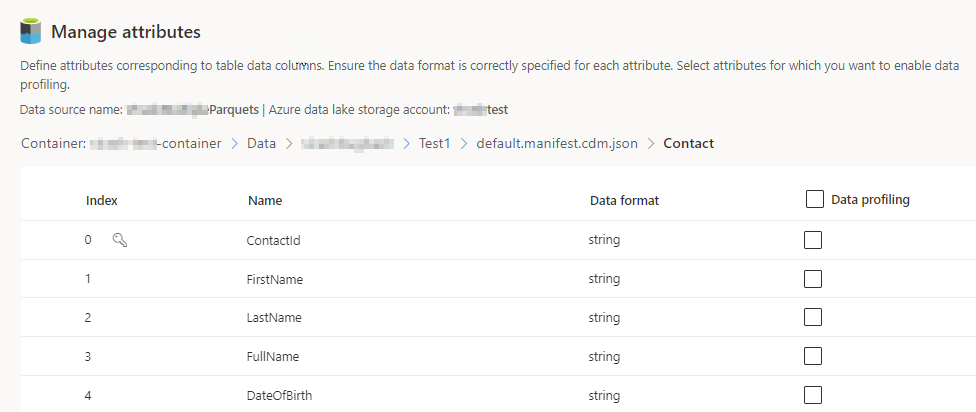
- 创建新列,编辑或删除现有列。 您可以更改名称、数据格式或添加语义类型。
- 要启用分析和其他功能,为整个表或特定列选择数据分析。 默认情况下,不会为数据分析启用任何表。
- 选择完成。
选择保存。 数据源页面将打开,显示处于正在刷新状态的新数据源。

加载数据可能需要一些时间。 成功刷新后,可以从表页查看引入的数据。
创建新架构文件
选择创建架构文件。
为文件输入名称,然后选择保存。
选择新建表。 新建表面板将显示。
输入表名称并选择数据文件位置。
- 多个 .csv 或 .parquet 文件:浏览到根文件夹,选择模式类型,然后输入表达式。
- 单个 .csv 或 .parquet 文件:浏览到 .csv 或 .parquet 文件,选择该文件。
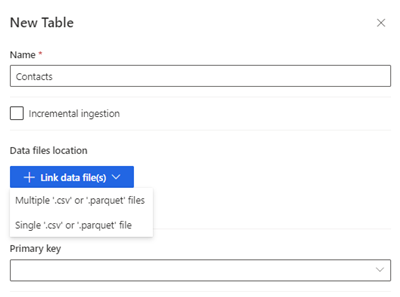
选择保存。
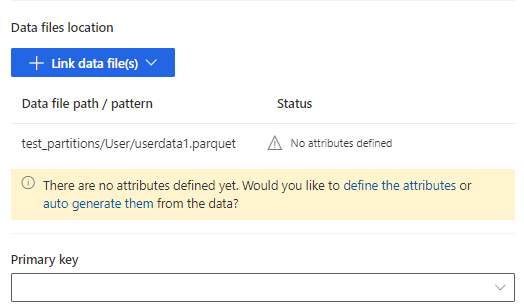
选择定义属性手动添加属性,或选择自动生成属性。 要定义属性,输入名称,然后选择数据格式和可选语义类型。 对于自动生成的属性:
属性自动生成后,选择查看属性。 管理属性页面将显示。
确保每个属性的数据格式都是正确的。
要启用分析和其他功能,为整个表或特定列选择数据分析。 默认情况下,不会为数据分析启用任何表。
选择完成。 选择表页面将显示。
继续添加表和列(如果适用)。
添加所有表后,选择包括在数据源引入中包括表。
对于未定义主键的选定表,主键下将显示必需。 对于每个表:
- 选择必需。 编辑表面板将显示。
- 选择主键。 主键是表所特有的属性。 若要使属性成为有效主键,它不应包括重复值、缺少值或 null 值。 支持将字符串、整数和 GUID 数据类型属性作为主键。
- 或者,更改分区模式。
- 选择关闭保存并关闭面板。
选择保存。 数据源页面将打开,显示处于正在刷新状态的新数据源。
加载数据可能需要一些时间。 成功刷新后,可以从数据>表页查看引入的数据。
编辑 Azure Data Lake Storage 数据源
您可以更新连接存储帐户使用的是选项。 有关详细信息,请参阅使用 Microsoft Entra 服务主体连接到 Azure Data Lake Storage 帐户。 若要连接到除存储帐户之外的容器,或更改帐户名称,应创建新的数据源连接。
转到数据>数据源。 在要更新的数据源旁边,选择编辑。
更改以下任一信息:
Description
连接存储使用的是和连接信息。 在更新连接时,无法更改容器信息。
备注
必须将以下角色之一分配给存储帐户或容器:
- 存储 Blob 数据读取器
- 存储 Blob 数据负责人
- 存储 Blob 数据参与者
如果要通过 Azure 专用链接从存储帐户引入数据,启用专用链接。 有关详细信息,请转到专用链接。
选择下一步。
更改以下任一信息:
导航到具有来自容器的不同表集的不同 model.json 或 manifest.json 文件。
要添加将要引入的其他表,选择新建表。
如果没有依赖关系,要删除任何已选择的表,选择该表,然后选择删除。
重要提示
如果现有 model.json 或 manifest.json 文件以及表集上存在依赖项,则会看到错误消息,并且无法选择其他 model.json 或 manifest.json 文件。 在更改 model.json 或 manifest.json 文件或使用想要避免删除依赖项的 model.json 或 manifest.json 文件创建新数据源之前,请删除这些依赖项。
要更改数据文件位置或主键,选择编辑。
仅更改表名称以匹配 .json 文件中的表名称。
备注
引入后,始终将表名称与 model.json 或 manifest.json 文件中的表名称保持相同。 Customer Insights - Data 会在每次系统刷新期间使用 model.json 或 manifest.json 验证所有表名称。 如果表名称发生变化,将发生错误,因为 Customer Insights - Data 在 .json 文件中找不到新的表名称。 如果引入的表名称被意外更改,应编辑表名称以与 .json 文件中的名称保持一致。
选择列添加或更改列,或启用数据分析。 然后选择完成。
选择保存应用您的更改并返回到数据源页面。