缓存在云原生应用中

缓存的好处很好理解。 此技术的工作原理是暂时将经常访问的数据从后端数据存储复制到离应用程序较近的快速存储。 缓存通常在以下情况下实现...
- 数据保持相对静态。
- 数据访问速度缓慢,尤其是与缓存速度相比。
- 数据受到高级别争用的影响。
为什么?
如 Microsoft 缓存指南中所述,缓存可以提升各个微服务和整个系统的性能、可伸缩性和可用性。 它减少了处理对数据存储的大量并发请求的延迟和争用。 随着数据量和用户数量的增加,缓存的好处变得越大。
客户端反复读取不可变或不经常更改的数据时,缓存最有效。 示例包含引用信息,例如产品和价格信息,或构建成本高昂的共享静态资源。
虽然微服务应该是无状态的,但分布式缓存可以支持在绝对需要时并发访问会话状态数据。
此外,请考虑使用缓存以避免重复计算。 如果操作转换数据或执行复杂的计算,可以缓存结果以供后续请求使用。
缓存体系结构
云原生应用程序通常实现分布式缓存体系结构。 缓存作为基于云的后备服务托管,独立于微服务。 图 5-15 显示了体系结构。
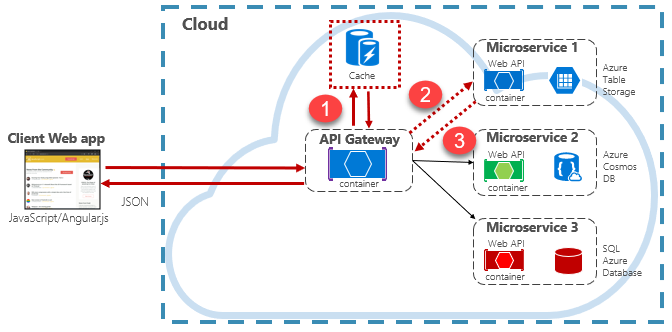
图 5-15:缓存在云原生应用中
在上图中,请注意缓存如何独立于微服务并与其共享。 在此场景中,缓存由 API 网关调用。 如第 4 章所述,网关充当所有传入请求的前端。 分布式缓存通过尽可能返回缓存的数据来增加系统响应能力。 此外,将缓存与服务分开可让缓存纵向扩展或横向扩展,以满足增加的流量需求。
上图显示一种常见的缓存模式,称为旁缓存模式。 对于传入请求,首先查询缓存(步骤 #1)以获得响应。 如果找到,则立即返回数据。 如果缓存中不存在数据(称为 缓存失误),则从下游服务中的本地数据库中检索(步骤 #2)。 然后,它会写入缓存,供将来的请求使用(步骤 #3),并返回到调用方。 定期逐出缓存数据时必须谨慎,确保系统保持及时且一致。
随着共享缓存的增长,将数据分区到多个节点可能会非常有利。 这样做有助于最大程度地减少争用并提高可伸缩性。 许多缓存服务支持动态添加与删除节点,以及重新平衡分区之间的数据的功能。 此方法通常涉及群集。 群集将联合节点的集合公开为无缝的单一缓存。 但在内部,数据按照均衡负载的预定义分发策略分散在节点之间。
用于 Redis 的 Azure 缓存
Azure Cache for Redis 是由 Microsoft 完全管理的安全数据缓存和消息传送代理服务。 它用作平台即服务 (PaaS) 产品/服务,提供对数据的高吞吐量和低延迟访问。 Azure 内部或外部的任何应用程序都可以访问该服务。
Azure Cache for Redis 服务管理对跨 Azure 数据中心的开源 Redis 服务器的访问。 该服务充当提供管理、访问控制和安全性的外观。 该服务原生支持一组丰富的数据结构,包括字符串、哈希、列表和集。 如果应用程序已使用 Redis,它将按原样适用于 Azure Cache for Redis。
Azure Cache for Redis 不仅仅是一个简单的缓存服务器。 它可以支持许多方案来增强微服务体系结构:
- 内存中数据存储
- 分布式非关系数据库
- 消息中转站
- 配置或发现服务器
对于高级方案,缓存数据的副本可以持久保留到磁盘。 如果灾难性事件导致主缓存和副缓存都无法使用,则会通过最新快照重新构造缓存。
Azure Redis Cache 可用于多个预定义的配置和定价层。 高级层具有许多企业级功能,例如群集、数据持久性、异地复制和虚拟网络隔离。