缓存是一种常见的技术,目标是提高系统的性能和伸缩性。 为缓存数据,它会暂时会经常访问的数据复制到位置靠近应用程序的快速存储。 如果这种快速数据存储比原始源更靠近应用程序,则缓存可以通过更快速提供数据,大幅改善客户端应用程序的响应时间。
如果客户端实例重复读取同一数据,则缓存是最有效的方式,尤其是原始数据存储存在以下情况时:
- 保持相对静态。
- 相对于缓存速度而言较慢时。
- 受限于激烈的资源争用。
- 由于距离遥远,网络延迟会造成访问速度缓慢。
分布式应用程序中的缓存
在缓存数据时,分布式应用程序通常会实施以下一种或两种策略:
- 它们使用专用缓存,其中的数据保存在运行应用程序或服务实例的计算机本地。
- 它们使用共享缓存,充当可由多个进程和计算机访问的公用源。
在这两种情况下,缓存可在客户端和服务器端执行。 通过为系统提供用户界面(例如 Web 浏览器或桌面应用程序)的进程来实现客户端缓存。 通过远程运行的提供业务服务的进程来实现服务器端缓存。
专用缓存
最基本类型的缓存是内存中存储。 这种缓存保留在单个进程的地址空间中,可由该进程中运行的代码直接访问。 这种类型的缓存可快速访问。 它还可以提供存储少量静态数据的有效方法。 缓存的大小通常受托管进程的计算机上的可用内存量的约束。
如果缓存的信息需要超过内存中实际可用的信息,可以将缓存数据写入本地文件系统。 此进程比访问保留在内存中的数据更慢,但应该仍比通过网络检索数据更快速且更可靠。
如果有多个并行运行的、使用此模型的应用程序实例,则每个应用程序实例将有自身的独立缓存用于保存自身的数据副本。
应该将缓存视为过去某个时间点原始数据的快照。 如果此数据不是静态的,则有可能不同的应用程序实例会在其缓存中保存不同版本的数据。 因此,这些实例执行的同一查询可能会返回不同的结果,如图 1 所示。
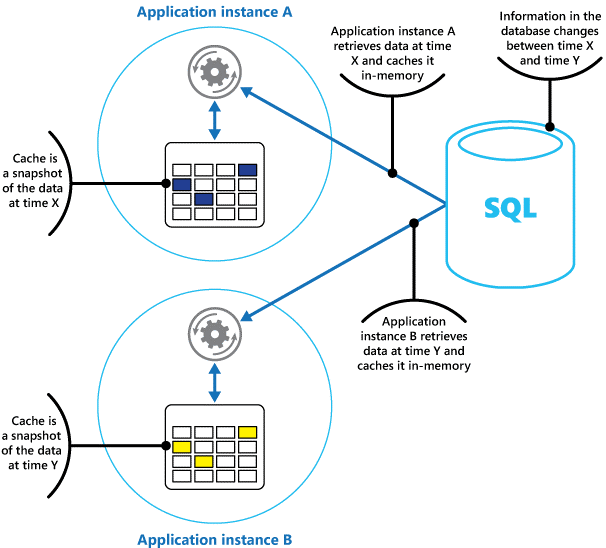
图 1:在不同的应用程序实例中使用内存中缓存。
共享缓存
如果使用共享缓存,则有助于缓解每个缓存中可能存在不同数据的忧虑,这种情况可能会发生于内存中缓存。 共享缓存可确保不同的应用程序实例看到同一缓存数据视图。 将缓存定位在不同的位置,通常作为不同服务的一部分托管,如图 2 所示。
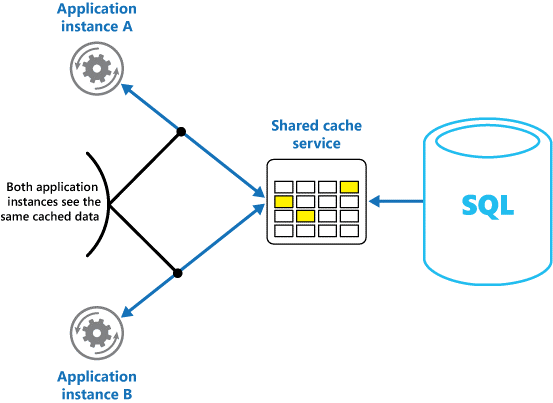
图 2:使用共享缓存。
伸缩性是共享缓存的一个重要优势。 许多共享缓存服务是使用服务器群集实现的,并使用软件以透明方式将数据分布到群集。 应用程序实例只会将请求发送到缓存服务。 缓存数据在群集中的位置由底层基础结构确定。 可以轻松地通过添加更多服务器来扩展缓存。
共享缓存方法有两个主要缺点:
- 缓存的访问速度较慢,因为它不再保留在每个应用程序实例的本地。
- 为了满足实施不同缓存服务的要求,可能会增大解决方案的复杂性。
使用缓存时的注意事项
以下部分更详细地说明了设计和使用缓存时的注意事项。
确定何时缓存数据
缓存可大幅提高性能、伸缩性和可用性。 当数据越多且需要访问此数据的用户越多,缓存的优点也就越大。 在原始数据存储中处理大量并发请求时,可以减少相关的延迟和争用。
例如,数据库可以支持有限数目的并发连接。 但从共享缓存而不是底层数据库检索数据可让客户端应用程序访问此数据,即使当前可用的连接数已用尽。 此外,如果数据库变得不可用,客户端应用程序也许可以使用缓存中保存的数据继续运行。
考虑使用经常读取但很少修改的缓存(数据读取操作的比例要高于写入操作)。 但是,不应将缓存用作关键信息的权威存储。 应确保应用程序不可丢失的所有更改始终存储到永久性数据存储中。 如果缓存不可用,应用程序仍可以使用数据存储继续操作,用户不会丢失重要信息。
确定如何有效缓存数据
有效使用缓存的关键在于确定最适合缓存的数据,以及最适合缓存的时间。 数据可能在第一次由应用程序检索时随选添加到缓存。 应用程序仅需从数据存储检索一次数据,而后续访问可通过使用缓存来满足。
或者,可以事先在缓存中部分或完全填充数据,这通常发生在应用程序启动时(此方法称为种子设定)。 但是,不建议对大型缓存实施种子设定,因为这种方法在应用程序开始运行时,可能会在原始数据存储上造成突发性的高负载。
使用模式分析通常可以帮助确定是否要完整或部分预先填充缓存,以及选择要缓存的数据。 例如,对于定期(也许是每天)使用应用程序的客户,你可以通过静态用户配置文件数据设定缓存种子,但不适用于一周仅使用一次应用程序的客户。
缓存通常适用于不会变化或很少变化的数据。 示例包含引用信息,例如电子商务应用程序中的产品和价格信息,或构建成本高昂的共享静态资源。 此数据的部分或全部可在应用程序启动时加载到缓存,以便将资源需求降到最低并提高性能。 你可能还希望有一个后台进程定期更新缓存中的引用数据,以确保它是最新的。 或者,当引用数据发生更改时,后台进程可以刷新缓存。
缓存可能较不适合动态数据,但这种考虑因素有一些例外情况(请参阅本文后面的“缓存高动态数据”部分以了解详细信息)。 如果原始数据定期更改,缓存的信息可能很快就会过时,或者为了保持与原始数据存储的缓存同步而产生开销,导致降低缓存的效率。
缓存中不一定会包含实体的完整数据。 例如,如果数据项代表多值对象(例如具有名称、地址和帐户余额的银行客户),则其中某些元素可以保持静态(例如名称和地址)。 其他元素(例如帐户余额)则可能更加动态。 在这种情况下,缓存数据的静态部分,并只在需要时检索(或计算)剩余信息可能相当有用。
建议执行性能测试和使用情况分析来确定预先填充和/或按需加载缓存是否适当。 这种判断应该基于数据易变性和使用模式。 在会遇到重度负载且必须高度可缩放的应用程序中,缓存利用和性能分析很重要。 例如,在高度可缩放的方案中,可以设定缓存种子,以在高峰期降低数据存储的负载。
缓存还可用于在应用程序运行时避免重复计算。 如果操作会转换数据或执行复杂计算,则可以在缓存中保存操作的结果。 如果后续需要相同的计算,应用程序只需从缓存中检索结果。
应用程序可以修改保存在缓存中的数据。 但是,我们建议将缓存视为可能随时消失的暂时性数据存储。 请勿只在缓存中存储重要数据,而是确保同时在原始数据存储中保留信息。 这意味着,当缓存不可用时,可以最大程度地减少数据丢失。
缓存高动态数据
在永久性数据存储中存储快速变化的信息时,可能会给系统造成开销。 例如,假设有一个会持续报告状态或其他度量的设备。 在缓存信息几乎一直处于过期状态的情况下,如果应用程序选择不要缓存此数据,则在数据存储中存储和检索此信息时,同样存在这种考虑因素。 在保存和提取此数据时它可能已经更改。
在这种情况下,请考虑直接在缓存而不是永久性数据存储中存储动态信息的优点。 如果数据不太重要且不需要审核,则丢失偶尔发生的更改也问题不大。
管理缓存中的数据过期
在大多数情况下,缓存中保存的数据是保存在原始数据存储中的数据的副本。 原始数据存储中的数据可能在缓存后更改,导致缓存的数据过时。 许多缓存系统允许将缓存配置为使数据过期,以及减少数据可以过期的时间长短。
过期的缓存数据将从缓存中删除,应用程序必须从原始数据存储中检索数据(它可以将新提取的信息放回缓存中)。 在配置缓存时,可以设置默认的过期策略。 在许多缓存服务中,当以编程方式将单个对象存储在缓存中时,还可以规定这些对象的过期时间。 某些缓存可让你将过期时间指定为绝对值,或者,如果并未在指定的时间内访问,则从缓存中删除项的滑动值。 此设置将重写任何缓存范围的过期策略,但只适用于指定的对象。
注意
请慎重考虑缓存的过期时段及其包含的对象。 如果设置的时段太短,则对象很快就会过期,因此就减少了使用缓存带来的优势。 如果设置的时段太长,则会面临数据过时的风险。
此外,如果允许数据长时间驻留,则缓存有可能会填满。 在此情况下,将新项添加到缓存的任何请求可能会导致某些项被强行删除,这个过程称为逐出。 缓存服务通常按最近最少使用 (LRU) 原则逐出数据,但通常可以替代此策略并防止逐出项。 但是,如果采用这种方法,则会面临缓存超过可用内存。 应用程序尝试将项添加到缓存时会失败并发生异常。
某些缓存的实施可能会提供其他逐出策略。 有多种类型的逐出策略。 其中包括:
- 最近使用的策略(预期不再需要数据)。
- 先进先出策略(先逐出最旧的数据)。
- 或基于触发事件显式删除(例如,正在修改数据)。
使客户端缓存中的数据失效
保存在客户端缓存中的数据通常被视为不受向客户端提供数据的服务的支持。 服务不能直接强制客户端添加或删除来自客户端缓存的信息。
这意味着,使用配置不当的缓存的客户端可能继续使用过时的本地缓存信息。 例如,如果未正确实施过期策略,当原始数据源中的信息已更改时,客户端可能使用本地缓存的已过时信息。
如果要构建通过 HTTP 连接提供数据的 Web 应用程序,可以隐式强制 Web 客户端(例如浏览器或 Web 代理)提取最新的信息。 当资源通过更改该资源的 URI 更新时,可以执行此操作。 Web 客户端通常使用资源的 URI 作为客户端缓存中的键,因此更改 URI 会导致 Web 客户端忽略任何先前缓存的资源版本,并改为提取新的版本。
管理缓存中的并发
缓存通常设计为由应用程序的多个实例共享。 每个应用程序实例可以读取和修改缓存中的数据。 因此,任何共享数据存储中会出现的并发问题,在缓存中同样也会出现。 在应用程序需要修改缓存中保存的数据的情况下,可能需要确保应用程序的一个实例所做的更新不会盲目地覆盖另一个实例所做的更改。
根据数据的性质和冲突的可能性,可以采用以下两种并发方式之一:
- 乐观并发。 应用程序检查以确定缓存中的数据自检索之后、更新之前是否已更改。 如果数据保持相同,则可以进行更改。 否则,应用程序必须确定是否要进行更新。 (驱动此决策的业务逻辑将是特定于应用程序的。)这种方法适用于更新不频繁或不太可能发生冲突的情况。
- 悲观并发。 应用程序在检索缓存中的数据时锁定数据,以避免另一个实例更改数据。 此过程可确保不发生冲突,但可能阻止其他需要处理同一数据的实例。 悲观并发可能会影响解决方案的伸缩性,建议只对短期操作使用。 这种方法可能适用于很可能发生冲突的情况,特别是当应用程序更新缓存中的多个项,且必须确保这些更改一致应用时。
实现高可用性和伸缩性并提高性能
避免使用缓存作为数据的主存储库;主存储库应该是从中填充缓存的原始数据存储的角色。 原始数据存储负责确保数据的持久性。
请小心不要将共享缓存服务可用性的重要依赖性引入解决方案。 如果提供共享缓存的服务不可用,应用程序应能继续工作。 在等待缓存服务恢复时,应用程序应该不会停止响应或失败。
因此,应用程序必须准备好检测缓存服务的可用性,并在无法访问缓存时回退到原始数据存储。 断路器模式可用于处理这种情况。 提供缓存的服务可以恢复,当该服务可用后,缓存会在从原始数据存储读取数据时,遵循缓存端模式等策略重新填充。
但是,如果应用程序在缓存暂时不可用时回退到原始数据存储,系统的伸缩性可能会受影响。 在恢复数据存储时,原始数据存储可能忙于处理数据请求,导致超时和连接失败。
考虑在每个应用程序实例中实施本地专用缓存,以及所有应用程序实例访问的共享缓存。 当应用程序检索项时,可能会先后在本地缓存、共享缓存和原始数据存储中检查。 共享缓存不可用时,本地缓存可以使用共享缓存或数据库中的数据来填充。
采用此方法需要经过慎重的配置,以防止本地缓存相对于共享缓存而言太过时。 但在无法访问共享缓存时,它可以充当缓冲区。 图 3 显示了此结构。
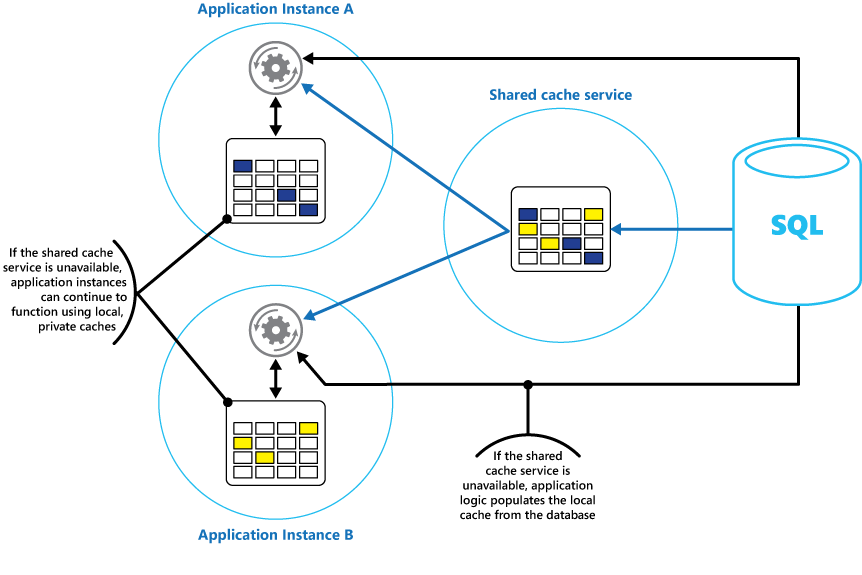
图 3:将本地专用缓存与共享缓存配合使用。
为了支持保存相对长期数据的大型缓存,某些缓存服务在缓存不可用时,提供实施自动故障转移的高可用性选项。 这种方法通常涉及到将存储在主缓存服务器上的缓存数据复制到辅助缓存服务器,并在主服务器故障或断开连接时切换到辅助服务器。
为了减少与写入多个目标相关的延迟,当数据写入主服务器上的缓存时,复制到辅助服务器的操作可以异步发生。 此方法可能会导致某些缓存的信息在发生故障时丢失,但是此数据的比例应该小于缓存的总体大小。
如果共享缓存很大,则在节点上分区缓存数据可能很有帮助,这可减少争用的可能性,并提高伸缩性。 许多共享缓存支持动态添加(与删除)节点,以及重新平衡分区之间的数据的功能。 这种方法可能涉及到群集,其中,节点集合将作为无缝单一缓存向客户端应用程序呈现。 但在内部,数据分散在节点之间并遵循某种预定义的分配策略,以便平均地平衡负载。 有关可能的分区策略的详细信息,请参阅 Data partitioning guidance(数据分区指南)。
群集还可以提高缓存的可用性。 如果节点发生故障,仍可访问缓存的剩余部分。 群集经常与复制和故障转移结合使用。 每个节点都可复制且副本在节点故障时可快速联机。
许多读取和写入操作可能会涉及到单个数据值或对象。 但是,有时可能需要快速存储或检索大量数据。 例如,设定缓存种子可能涉及到将数百或数千个项写入到缓存。 应用程序还可能需要从缓存中检索属于同一请求的大量相关项。
许多大型缓存针对这些目的提供了批处理操作。 这样,客户端应用程序便可以将大量的项打包成单个请求,并减少执行大量小型请求时的相关开销。
缓存和最终一致性
要使缓存端模式正常工作,填充缓存的应用程序实例必须有权访问最新且一致的数据版本。 在实施最终一致性的系统(例如复制的数据存储)中,情况可能不是这样。
应用程序的一个实例可以修改数据项,使该项的缓存版本失效。 应用程序的另一个实例可以尝试从导致缓存未命中的缓存读取此项,因此它将从数据存储中读取数据,并将它添加到缓存。 但是,如果数据存储没有完全与其他副本同步,则应用程序实例可能会使用旧值来读取并填充缓存。
有关处理数据一致性的详细信息,请参阅 Data consistency primer(数据一致性入门)。
保护缓存的数据
无论使用的缓存服务为何,都应该考虑如何防范缓存中保存的数据遭到未经授权的访问。 有两个主要考虑因素:
- 缓存中数据的隐私性。
- 数据在缓存与使用缓存的应用程序之间流动时的隐私性。
若要保护缓存中的数据,缓存服务可以实施一种身份验证机制,要求应用程序指定:
- 哪些标识可以访问缓存中的数据。
- 允许这些标识执行的操作(读取和写入)。
为了减少读取和写入数据时的相关开销,当标识已获得写入或读取缓存的权限时,该标识可以使用缓存中的任何数据。
如果需要限制对缓存数据子集的访问权限,可以执行以下操作之一:
- 将缓存拆分成分区(使用不同的缓存服务器),并只向标识授予他们有权使用的分区的访问权限。
- 使用不同的密钥来加密每个子集中的数据,并只向应该具有每个子集访问权限的标识提供加密密钥。 客户端应用程序可能仍然能够检索缓存中的所有数据,但它只能够解密具有密钥的数据。
还必须在数据流入或流出缓存时保护数据。 为此,可以依赖于客户端应用程序用来连接缓存的网络基础结构所提供的安全功能。 如果在托管客户端应用程序的同一组织中使用现场服务器来实施缓存,则网络本身的隔离可能不需要你采取其他措施。 如果缓存位于远程,且需要基于公共网络(例如 Internet)的 TCP 或 HTTP 连接,请考虑实施 SSL。
在 Azure 中实现缓存的注意事项
Azure Cache for Redis 是开源 Redis 缓存的一种实现,可作为服务在 Azure 数据中心运行。 它提供可从任何 Azure 应用程序访问的缓存服务,无论应用程序是实施为云服务、网站,还是在 Azure 虚拟机中。 拥有适当访问密钥的客户端应用程序可以共享缓存。
Azure Cache for Redis 是一个高性能缓存解决方案,提供可用性、可伸缩性和安全性。 它通常作为分散在一个或多个专用计算机上的服务运行, 并尝试在内存中存储尽量多的信息以确保快速访问。 这种体系结构旨在通过减少执行缓慢 I/O 操作的需要,提供低延迟和高吞吐量。
Azure Cache for Redis 与客户端应用程序使用的多种 API 兼容。 如果现有应用程序已使用在本地运行的 Azure Cache for Redis,Azure Cache for Redis 可为在云中缓存提供一个快速迁移路径。
Redis 的功能
Redis 不仅是简单的缓存服务器。 它还提供分布式内存中数据库,其中包含用于支持许多常见方案的广泛命令集。 本文档后面的“使用 Redis 缓存”部分会进行相关介绍。 本部分汇总了 Redis 提供的一些重要功能。
Redis 用作内存中数据库
Redis 支持读取和写入操作。 在 Redis 中,写入操作会定期存储在本地快照文件或仅限附加的日志文件中,因此可在系统故障时得到保护。 在许多缓存中情况并非如此,这些缓存应被视为暂时性数据存储。
所有写入都是异步的,不会阻止客户端读取和写入数据。 当 Redis 开始运行时,将从快照或日志文件中读取数据,并使用它来构建内存中缓存。 有关详细信息,请参阅 Redis 网站上的 Redis persistence(Redis 持久性)。
注意
Redis 不保证所有写入在发生灾难性故障时都会得到保存,但在最糟的情况下,只会丢失几秒钟的数据。 请记住,缓存并不适合用作权威数据源,应用程序负责使用缓存来确保成功将关键数据保存到适当的数据存储。 有关详细信息,请参阅缓存端模式。
Redis 数据类型
Redis 属于键-值存储,其中的值可以包含简单类型或复杂数据结构,例如哈希、列表和集。 Redis 支持对这些数据类型执行原子操作。 键可以是永久性的,或者标记了一个有限的生存时间,到了该时间后,键及其对应的值会自动从缓存中删除。 有关 Redis 键和值的详细信息,请访问 Redis 网站上的 An introduction to Redis data types and abstractions(Redis 数据类型和抽象简介)页。
Redis 复制和群集
Redis 支持主/从复制,以帮助确保可用性并保持吞吐量。 向 Redis 主节点的写入操作将复制到一个或多个从属节点。 读取操作可由主节点或任何从属节点提供。
如果具有网络分区,从属节点可以继续提供数据,并在重新建立连接时以透明方式与主节点重新同步。 有关详细信息,请访问 Redis 网站上的 Replication(复制)页。
Redis 还提供群集,让你以透明方式在服务器之间将数据分区成分片并分散负载。 此功能提高了伸缩性,因为可以添加新 Redis 服务器,并且随着缓存大小的增加,数据将重新分区。
此外,可以使用主/从复制来复制群集中的每台服务器。 这可确保整个群集中每个节点的可用性。 有关群集和分片的详细信息,请访问 Redis 网站上的 Redis 群集教程页。
Redis 内存使用
Redis 缓存具有有限的大小,具体取决于主机计算机上可用的资源。 在配置 Redis 服务器时,可以指定服务器可使用的最大内存量。 可为 Redis 缓存中的键配置过期时间,到时它会自动从缓存中删除。 此功能可帮助避免内存中缓存填满陈旧或过时的数据。
当内存填满时,Redis 可以遵循一些策略自动逐出键及其值。 默认策略是 LRU(最近最少使用),但你也可以选择其他策略,例如,随机逐出键,或完全关闭逐出(在此情况下,当缓存已满时,尝试将项添加到缓存会失败)。 Using Redis as an LRU cache(使用 Redis 作为 LRU 缓存)页提供了详细信息。
Redis 事务和批处理
Redis 可让客户端应用程序提交一系列的操作,用于在缓存中以原子事务的形式读取和写入数据。 保证事务中的所有命令按顺序运行,其他并发客户端所发出的命令将不在两者之间交互编排。
但是,这不是真正的事务,因为关系数据库将执行这些事务。 事务处理包括两个阶段 -- 在第一个阶段将命令排队,在第二个阶段运行命令。 在命令排队阶段,客户端将提交构成事务的命令。 如果此时发生某种形式的错误(例如语法错误,或参数数目不正确),Redis 将拒绝处理整个事务并将其丢弃。
在运行阶段,Redis 将按顺序执行每个队列中的命令。 如果在此阶段命令失败,Redis 将继续执行下一个队列中的命令,且它不会回滚任何已运行命令的结果。 这种简化的事务形式有助于保持性能,并避免争用所造成的性能问题。
Redis 实施某种形式的乐观锁定,以帮助保持一致性。 有关事务和使用 Redis 进行锁定的详细信息,请访问 Redis 网站上的事务页。
Redis 还支持请求的非事务性批处理。 客户端用于将命令发送到 Redis 服务器的 Redis 协议可让客户端以同一请求的一部分来发送一系列操作。 这有助于减少网络上的数据包分段。 处理批时,将执行每个命令。 如果其中任一命令的格式不当,则将遭到拒绝(对于事务不会发生这种情况),但会执行剩余的命令。 此外,不保证批中命令的处理顺序。
Redis 安全性
Redis 专门注重于提供数据快速访问,设计为在受信任的环境中运行,且只能由受信任的客户端访问。 Redis 支持基于密码身份验证的有限安全模型。 (可以完全删除身份验证,但不建议这样做。)
所有已经过身份验证的客户端共享同一个全局密码,并有权访问相同的资源。 如果需要更全面的登录安全性,必须在 Redis 服务器前面实施自己的安全层,并且所有客户端请求应通过此附加层。 不应直接向不受信任或未经身份验证的客户端公开 Redis。
可以通过禁用命令或重命名命令(仅提供有权限的客户端使用新的名称)来限制对命令的访问。
Redis 不直接支持任何形式的数据加密,因此所有编码必须由客户端应用程序执行。 此外,Redis 不提供任何形式的传输安全性。 如果数据在网络上流动时需要保护数据,建议实施 SSL 代理。
有关详细信息,请访问 Redis 网站上的 Redis security(Redis 安全性)页。
注意
Azure Cache for Redis 通过提供自己的安全层,客户端通过该层建立连接。 底层 Redis 服务器不向公共网络公开。
Azure Redis 缓存
Azure Cache for Redis 提供对托管在 Azure 数据中心的 Redis 服务器的访问。 它充当提供访问控制与安全性的机制。 可以使用 Azure 门户来预配缓存。
此门户提供了许多预定义的配置。 这些配置包括支持 SSL 通信(适用于隐私性)以及主/从复制配合 99.9% 可用性的服务级别协议 (SLA) 的作为专用服务运行的 53 GB 缓存,以及共享硬件上运行不含复制(无可用性保证)的 250 MB 缓存。
使用 Azure 门户还可以配置缓存的逐出策略,并通过将用户添加到提供的角色来控制缓存的访问权限。 这些角色包括所有者、参与者和读者,可以定义成员能够执行的操作。 例如,所有者角色成员拥有缓存(包含安全性)及其内容的完全控制权,参与者角色成员可以在缓存中读取和写入信息,而读取者角色成员只能从缓存检索数据。
大多数管理任务可通过 Azure 门户来执行。 出于此原因,许多 Redis 标准版中的管理命令都不可用,包括以编程方式修改配置、关闭 Redis 服务器、配置其他从属服务器,或强制将数据存储到磁盘等功能。
Azure 门户拥有便利的图形显示,可通过它监视缓存性能。 例如,可以查看创建的连接数、执行的请求数、读取和写入次数,以及缓存命中与缓存未命中次数。 可以使用此信息来确定缓存的效率,并可根据需要切换到不同的配置,或更改逐出策略。
此外,如果一个或多个关键度量值超过预期范围,可以创建将电子邮件消息发送给管理员的警报。 例如,如果缓存失误次数在最后一小时超过指定的值,则可能要提醒管理员,因为这意味着缓存可能太小或数据可能逐出得太快。
还可以监视缓存的 CPU、内存和网络使用量。
有关说明如何创建和配置 Azure Cache for Redis 的更多信息和示例,请访问 Azure 博客上的 Lap around Azure Cache for Redis(了解 Azure Cache for Redis)页面。
缓存会话状态和 HTML 输出
如果要构建使用 Azure Web 角色运行的 ASP.NET Web 应用程序,可以将会话状态信息和 HTML 输出保存在 Azure Cache for Redis 中。 Azure Cache for Redis 的会话状态提供程序使用户能够在 ASP.NET Web 应用程序的不同实例之间共享会话信息,且它在以下 Web 场情况中十分有用:客户端与服务器的相关性不可用且在内存中缓存会话数据并不适当。
将会话状态提供程序与 Azure Cache for Redis 结合使用可带来几个好处,包括:
- 在 ASP.NET Web 应用程序的大量实例之间共享会话状态。
- 提供更高的伸缩性。
- 针对多个读取者和单个写入者的同一会话状态数据支持受控的并发访问权限。
- 使用压缩来节省内存,并提高网络性能。
有关详细信息,请参阅 Azure Cache for Redis 的 ASP.NET 会话状态提供程序。
注意
不要针对在 Azure 环境外部运行的 ASP.NET 应用程序使用 Azure Cache for Redis 的会话状态提供程序。 从 Azure 外部访问缓存的延迟会抵消缓存数据带来的性能优势。
同样地,Azure Cache for Redis 的输出缓存提供程序使用户能够保存由 ASP.NET Web 应用程序生成的 HTTP 响应。 将输出缓存提供程序与 Azure Cache for Redis 结合使用可以缩短呈现复杂 HTML 输出的应用程序的响应时间。 生成类似响应的应用程序实例可以使用缓存中的共享输出片段,而不必重新生成此 HTML 输出。 有关详细信息,请参阅 Azure Cache for Redis 的 ASP.NET 输出缓存提供程序。
构建自定义 Redis 缓存
Azure Cache for Redis 充当基础 Redis 服务器的门面。 如果需要 Azure Redis 缓存未涵盖的高级配置(例如大于 53 GB 的缓存),可以使用 Azure 虚拟机来构建和托管自己的 Redis 服务器。
你在实现复制时可能需要创建多个 VM 作为主节点和从属节点,这可能是一个复杂的过程。 此外,如果要创建群集,则需要多个主服务器和从属服务器。 一个可提供较高的可用性和可伸缩性的最简单群集复制拓扑包含至少六个 VM(它们组织成三对主服务器/从属服务器,一个群集必须包含至少三个主节点)。
每个主/从对应彼此靠近以降低延迟。 但如果想要找出靠近的应用程序(该应用程序很可能会使用缓存数据),每一组对可以在位于不同区域的不同 Azure 数据中心运行。 有关生成和配置作为 Azure VM 运行的 Redis 节点的示例,请参阅 Running Redis on a CentOS Linux VM in Azure(在 Azure 中的 CentOS Linux VM 上运行 Redis)。
注意
如果以这种方式实现自己的 Redis 缓存,你需要负责监视、管理和保护服务。
将 Redis 缓存分区
将缓存分区涉及到在多台计算机之间拆分缓存。 此结构使用单个缓存服务器,可以提供多种优势,包括:
- 创建的缓存比单个服务器上存储的缓存要大得多。
- 将数据分散到多个服务器,从而提高可用性。 如果一台服务器发生故障或不可访问,该服务器保存的数据将不可用,但剩余服务器上的数据仍可访问。 对于缓存而言这并不重要,因为缓存数据只是数据库中暂时保存的数据副本。 不可访问的服务器上的缓存数据可以改为在不同的服务器上缓存。
- 在服务器之间分散负载,从而提高性能和伸缩性。
- 将数据放置在靠近用户访问的地理位置以降低延迟。
对于缓存,最常见的分区形式是分片。 在此策略中,每个分区(或分片)本身是一个 Redis 缓存。 数据使用分片逻辑定向到特定的分区,该逻辑可以使用各种方法来分布数据。 Sharding pattern(分片模式)提供了有关实施分片的详细信息。
若要在 Redis 缓存中实施分区,可以采用以下方法之一:
- 服务器端查询路由。 使用此方法时,客户端应用程序会将请求发送到构成缓存的任何 Redis 服务器(可能是最靠近的服务器)。 每个 Redis 服务器将存储用于描述它所保存的分区的元数据,同时还包含有关哪些分区位于其他服务器上的信息。 Redis 服务器检查客户端请求。 如果可以在本地解决,则执行请求的操作。 否则将请求转发到相应的服务器。 此模型是通过 Redis 群集实施的,Redis 网站上的 Redis 群集教程页上提供了更详细的说明。 Redis 群集对客户端应用程序而言是透明的,其他 Redis 服务器可以添加到群集(数据将重新分区),而无需重新配置客户端。
- 客户端分区。 在此模型中,客户端应用程序包含将请求路由到适当 Redis 服务器的逻辑(可能以库的形式)。 此方法可用于 Azure Cache for Redis。 创建多个 Azure Cache for Redis(每个数据分区各一个),并实现将请求路由到正确缓存的客户端逻辑。 如果分区方案发生更改(例如,如果已创建其他 Azure Cache for Redis),则可能需要重新配置客户端应用程序。
- 代理辅助分区。 在此方案中,客户端应用程序将请求发送到一个知道如何数据分区方式的中间代理服务,然后将请求路由到适当的 Redis 服务器。 此方法也可用于 Azure Cache for Redis;代理服务可以实现为 Azure 云服务。 使用此方法实施服务需要提高复杂性,并且执行请求的时间可能比使用客户端分区更长。
Redis 网站上的 Partitioning: how to split data among multiple Redis instances(分区:如何在多个 Redis 实例之间拆分数据)页提供了有关使用 Redis 实施分区的更多信息。
实施 Redis 缓存客户端应用程序
Redis 支持以多种编程语言编写的客户端应用程序。 如果要使用.NET Framework 构建新的应用程序,建议使用 StackExchange.Redis 客户端库。 此库提供 .NET Framework 对象模型,用于抽象连接到 Redis 服务器连接、发送命令和接收响应所需的详细信息。 在 Visual Studio 中,它以 NuGet 包的形式提供。 可以使用同一个库连接到 Azure Cache for Redis,或连接到 VM 上托管的自定义 Redis 缓存。
若要连接到 Redis 服务器,可以使用 ConnectionMultiplexer 类的静态 Connect 方法。 此方法创建的连接可在客户端应用程序的整个生存期内使用,同一个连接可由多个并发线程使用。 每次执行 Redis 操作时,请不要重新连接和断开连接,因为这可能会降低性能。
可以指定连接参数,例如 Redis 主机的地址和密码。 如果使用 Azure Cache for Redis,密码可能是使用 Azure 管理门户为 Azure Cache for Redis 生成的主密钥或辅助密钥。
在已连接到 Redis 服务器后,可以在用作缓存的 Redis 数据库上获取句柄。 Redis 连接提供了 GetDatabase 方法来执行此操作。 然后,可以使用 StringGet 和 StringSet 方法,从缓存中检索项并在缓存中存储数据。 这些方法需要将键用作参数,并返回缓存中具有匹配值的项 (StringGet),或者将项添加到具有此键的缓存 (StringSet)。
根据 Redis 服务器的位置,在将请求传输到服务器以及将响应返回给客户端时,许多操作可能会造成一些延迟。 StackExchange 库公开了许多方法的异步版本,用于帮助客户端应用程序保持响应。 这些方法支持 .NET Framework 中的基于任务的异步模式。
以下代码片段显示了名为 RetrieveItem 的方法。 其中演示了基于 Redis 和 StackExchange 库的缓存端模式的实现。 该方法采用字符串键值,并通过调用 StringGetAsync 方法(StringGet 的异步版本)尝试从 Redis 缓存中检索相应的项。
如果找不到该项,则使用 GetItemFromDataSourceAsync 方法(这是一个本地方法,它不是 StackExchange 库的一部分)从底层数据源提取该项。 然后,使用 StringSetAsync 方法将该项添加到缓存,以便下一次可以更快地检索。
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
StringGet 和 StringSet 方法不是只能检索或存储字符串值。 它们可以采用任何序列化为字节数组的项。 如果需要保存 .NET 对象,可以将它序列化为字节流,然后使用 StringSet 方法将它写入缓存。
同样地,可以使用 StringGet 方法从缓存中读取对象,并将其反序列化为 .NET 对象。 以下代码演示了 IDatabase 接口的一组扩展方法(Redis 连接的 GetDatabase 方法返回 IDatabase 对象),使用这些方法的某些示例代码可以在缓存中读取和写入 BlogPost 对象:
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
以下代码演示了一个名为 RetrieveBlogPost 的方法,该方法使用这些扩展方法,遵循缓存端模式在缓存中读取和写入可序列化的 BlogPost 对象:
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
如果客户端应用程序发送了多个异步请求,Redis 将支持命令管道。 Redis 可以使用同一连接来多路复用请求,而不是按照严格的顺序来接收和响应命令。
此方法可以更有效地使用网络来帮助降低延迟。 以下代码段演示了并行检索两个客户的详细信息的示例。 该代码将提交两个请求,再执行其他某种处理(未显示),然后等待接收结果。 缓存对象的 Wait 方法类似于 .NET Framework Task.Wait 方法:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
有关如何编写可使用 Azure Cache for Redis 的客户端应用程序的其他信息,请参阅 Azure Cache for Redis 文档。 请在 StackExchange.Redis 处查看详细信息。
同一网站上的 Pipelines and multiplexers(管道与多路复用器)页提供了有关使用 Redis 和 StackExchange 库执行异步操作和管道传输的详细信息。
使用 Redis 缓存
Redis 缓存的最简单用法包括存储键-值对,其中的值是未解释的字符串,该字符串具有任意长度,可以包含任何二进制数据。 (本质上是可视为字符串的字节数组)。 本文前面的“实施 Redis 缓存客户端应用程序”部分中已演示这种方案。
请注意,键还包含未解释的数据,因此,可以使用任何二进制信息作为键。 但键越长,存储花费的空间就越多,执行查找操作所需的时间也越长。 为了实现可用性和易维护性,请认真设计键空间并使用有意义(但非详细)的键。
例如,使用类似于“customer:100”的结构化键来表示 ID 为 100 的客户的键,而不是简单地使用“100”。 使用此方案可以轻松区分存储不同数据类型的值。 例如,也可以使用键“orders:100”来表示 ID为 100 的订单的键。
除了一维二进制字符串以外,Redis 键-值对中的值还可以包含更结构化的信息,包括列表、集(已排序和未排序)和哈希。 Redis 提供全面的命令集用于处理这些类型,其中的许多命令可以通过 StackExchange 等客户端库用于 .NET Framework 应用程序。 Redis 网站上的 An introduction to Redis data types and abstractions(Redis 数据类型和抽象简介)页更详细地概述了这些类型以及可用于处理这些类型的命令。
本部分汇总了这些数据类型和命令的一些常见用例。
执行原子操作和批处理操作
Redis 支持对字符串值执行一系列原子性“获取和设置”操作。 这些操作将删除使用单独的 GET 和 SET 命令时可能发生的争用风险。 可用的操作包括:
INCR、INCRBY、DECR和DECRBY,用于对整数数字数据值执行原子递增和递减操作。 StackExchange 库提供了IDatabase.StringIncrementAsync和IDatabase.StringDecrementAsync方法的重载版本,用于执行这些操作并返回存储在缓存中的结果值。 以下代码段演示了如何使用这些方法:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSET用于检索与键关联的值,并将其更改为新值。 StackExchange 库通过IDatabase.StringGetSetAsync方法使此操作可供使用。 以下代码段演示了此方法的示例。 此代码从前一示例返回与键 "data:counter" 关联的当前值。 然后将此键的值重置为零,这些都是同一操作的一部分:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGET和MSET可以作为单个操作返回或更改一组字符串值。IDatabase.StringGetAsync和IDatabase.StringSetAsync已重载以支持此功能,如以下示例中所示:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
也可以将多个操作合并成单个 Redis 事务,如本文前面的“Redis 事务和批处理”部分中所述。 StackExchange 库通过 ITransaction 接口提供事务支持。
使用 IDatabase.CreateTransaction 方法创建 ITransaction 对象。 使用 ITransaction 对象提供的方法调用对事务的命令。
ITransaction 接口可用于访问 IDatabase 接口所访问的类似一组方法,不过,所有方法是异步的。 这意味着,这些方法仅在调用 ITransaction.Execute 方法时执行。 ITransaction.Execute 方法返回的值指示事务创建是成功 (true) 还是失败 (false)。
以下代码段显示的示例会在执行同一事务期间递增和递减两个计数器:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
请记住,Redis 事务不同于关系数据库中的事务。 Execute 方法只是将构成运行事务的所有命令排入队列,如果其中任何一个命令格式不当,则停止事务。 如果已成功将所有命令排入队列,以异步方式运行每个命令。
如果任何命令失败,其他命令仍将继续处理。 如果需要验证命令是否已成功完成,必须使用相应任务的 Result 属性来提取命令的结果,如上述示例中所示。 读取 Result 属性会阻塞调用线程,直到任务完成。
有关详细信息,请参阅 Transactions in Redis(Redis 中的事务)。
执行批处理操作时,可以使用 StackExchange 库的 IBatch 接口。 此接口可用于访问 IDatabase 接口所访问的类似一组方法,不过,所有方法是异步的。
可以使用 IDatabase.CreateBatch 方法来创建 IBatch 对象,并使用 IBatch.Execute 方法来运行批处理,如以下示例所示。 这段代码仅设置字符串值,递增和递减前面示例中使用的相同计数器,并显示结果:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
必须知道,这不同于事务,如果因为格式不当而导致批中的命令失败,其他命令仍可运行。 IBatch.Execute 方法不返回成功或失败的任何指示。
执行即发即弃缓存操作
Redis 通过使用命令标志来支持即发即弃操作。 在此情况下,客户端仅启动操作,但不关注结果,且并不会等待命令完成。 以下示例演示了如何以即发即弃操作的形式执行 INCR 命令:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
指定密钥自动过期
在 Redis 缓存中存储项时,可以指定超时,超时过后,会自动从缓存中删除该项。 还可以在密钥过期之前,使用 TTL 命令来查询剩余时间。 StackExchange 应用程序可通过 IDatabase.KeyTimeToLive 方法使用此命令。
以下代码段演示了如何将密钥过期时间设置为 20 秒,并查询密钥剩余生存期:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
还可以使用 StackExchange 库中作为 KeyExpireAsync 方法提供的 EXPIRE 命令将过期时间设置为特定的日期和时间:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
提示
可以使用 DEL 命令手动从缓存中删除项,该命令在 StackExchange 库中作为 IDatabase.KeyDeleteAsync 方法提供。
使用标记来交叉关联项
Redis 集是共享单个键的多个项集合。 可以使用 SADD 命令来创建集。 可以使用 SMEMBERS 命令来检索集中的项。 StackExchange 库通过 IDatabase.SetAddAsync 方法实现 SADD 命令,并使用 IDatabase.SetMembersAsync 方法实现 SMEMBERS 命令。
还可以使用 SDIFF(差集)、SINTER(交集)和 SUNION(并集)命令来合并现有集以创建新的集。 StackExchange 库在 IDatabase.SetCombineAsync 方法中统一了这些操作。 此方法的第一个参数指定要执行的设置操作。
以下代码段演示了如何使用集来快速存储和检索相关项的集合。 此代码使用本文前面的“实施 Redis 缓存客户端应用程序”部分中所述的 BlogPost 类型。
BlogPost 对象包含四个字段:ID、标题、排名分数和标记集合。 以下第一个代码片段演示了用于填充 BlogPost 对象的 C# 列表的示例数据:
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
可以在 Redis 缓存中针对每个 BlogPost 对象将标记存储为集,并将每个集与 BlogPost ID关联。 这样,应用程序便可以快速查找属于特定博客文章的所有标记。 若要启用反向搜索并查找所有共享特定标记的博客文章,可以创建另一个集,用于保存引用键中标记 ID 的博客文章:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
这些结构允许高效执行许多常见查询。 例如,可以按如下所示查找并显示博客文章 1 的所有标记:
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
可以通过执行交集操作,查找博客文章 1 和博客文章 2 公用的所有标记,如下所示:
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
可以查找包含特定标记的所有博客文章:
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
查找最近访问的项
许多应用程序需要执行的常见任务是查找最近访问的项。 例如,博客站点可能要显示有关最近读过的博客文章的信息。
可以使用 Redis 列表来实现此功能。 Redis 列表包含共享同一个键的多个项。 该列表充当双端队列。 可以使用 LPUSH(左推)和 RPUSH(右推)命令将项推送到列表一端。 可以使用 LPOP 和 RPOP 命令从列表的一端检索项。 还可以使用 LRANGE 和 RRANGE 命令返回一组元素。
以下代码段演示了如何使用 StackExchange 库来执行这些操作。 此代码使用前面示例中的 BlogPost 类型。 当用户阅读博客文章时,IDatabase.ListLeftPushAsync 方法将博客文章的标题推送到与 Redis 缓存中的“blog:recent_posts”键关联的列表。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
随着阅读的博客文章越来越多,其标题将推送到同一列表。 列表已根据其添加顺序进行排序。 最近阅读的博客文章靠近列表左端。 (如果同一博客文章阅读了一次以上,则它在列表中有多个条目。)
可以使用 IDatabase.ListRange 方法显示最近阅读的文章的标题。 此方法采用包含列表、起点和终点的键。 以下代码将从列表的最左端检索 10 篇博客文章的标题(项为 0 到 9):
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
请注意,ListRangeAsync 方法不会从列表中删除项。 为此,可以使用 IDatabase.ListLeftPopAsync 和 IDatabase.ListRightPopAsync 方法。
若要防止列表无限增长,可以通过修剪列表来定期删除项。 以下代码段演示了如何只保留列表中位于最左端的 5 个项并删除其他所有项:
await cache.ListTrimAsync(redisKey, 0, 5);
实施排行榜
默认情况下,集中的项不以任何特定顺序保存。 可以使用 ZADD 命令(StackExchange 库中的 IDatabase.SortedSetAdd 方法)来创建排序集合。 系统使用一个名为 score(作为命令的参数提供)的数字值来为项排序。
以下代码段将博客文章的标题添加到排序列表。 在示例中,每篇博客文章还有包含博客文章排名的评分字段。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
可以使用 IDatabase.SortedSetRangeByRankWithScores 方法以评分递增顺序来检索博客文章标题和评分:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
注意
StackExchange 库还提供了 IDatabase.SortedSetRangeByRankAsync 方法,用于以评分顺序返回数据,但不返回评分。
也可以使用评分递减顺序来检索项,并通过将额外参数提供给 IDatabase.SortedSetRangeByRankWithScoresAsync 方法来限制返回项的数目。 以下示例演示了排名前 10 位博客文章的标题和评分:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
以下示例使用了 IDatabase.SortedSetRangeByScoreWithScoresAsync 方法,该方法可用于限制返回给那些处于给定评分范围内的项:
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
使用通道进行消息传送
Redis 服务器除了可用作数据缓存以外,还可通过高性能发布者/订阅者机制提供消息传送。 客户端应用程序可以订阅通道,其他应用程序或服务可以将消息发布到通道。 订阅应用程序随后会接收这些消息,并可以处理消息。
Redis 提供 SUBSCRIBE 命令来让客户端应用程序订阅通道。 此命令需要一个或多个可供应用程序接受消息的通道的名称。 StackExchange 库包含 ISubscription 接口,可让 .NET Framework 应用程序订阅和发布到通道。
使用 Redis 服务器连接的 GetSubscriber 方法创建 ISubscription 对象。 然后使用此对象的 SubscribeAsync 方法在通道上侦听消息。 以下代码示例演示了如何订阅名为“messages:blogPosts”的通道:
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
Subscribe 方法的第一个参数为通道的名称。 此名称遵循缓存中键使用的相同约定。 该名称可以包含任何二进制数据,但建议使用相对较短且有意义的字符串,以帮助确保良好的性能和易维护性。
另请注意,通道使用的命名空间与键使用的不同。 这意味着,通道和键可以同名,不过,这可能会导致更难以维护应用程序代码。
第二个参数是 Action 委派。 每当新的消息出现在通道上时,此委派就会以异步方式运行。 此示例仅显示了控制台上的消息(消息将包含博客文章的标题)。
若要发布到通道,应用程序可以使用 Redis PUBLISH 命令。 StackExchange 库提供了 IServer.PublishAsync 方法来执行此操作。 以下代码片段演示了如何将消息发布到“messages:blogPosts”通道:
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
关于发布/订阅机制,应该了解几个要点:
- 多个订阅者可以订阅同一个通道,他们都将接收发布到该通道的消息。
- 订阅者仅接收订阅后发布的消息。 通道不会缓冲,一旦发布消息,Redis 基础结构就会将消息推送到每个订阅者,然后删除消息。
- 默认情况下,订阅者根据发送顺序来接收消息。 在具有大量消息和许多订阅者与发布者的高度活跃系统中,保证依序传送消息可能会降低系统性能。 如果每个消息各自独立且顺序并不重要,则可以通过 Redis 系统启用并发处理,这有助于提高响应度。 可以在 StackExchange 客户端中,通过将订阅者使用的连接的 PreserveAsyncOrder 设置为 false 来实现此目的:
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
序列化注意事项
选择序列化格式时,请考虑在性能、互操作性、版本控制、与现有系统的兼容性、数据压缩和内存开销之间作出权衡。 评估性能时,请记住基准高度依赖于上下文。 它们可能不反映实际工作负载,也可能不考虑较新的库或版本。 不存在适用于所有方案的“最快”序列化程序。
应考虑的一些选项包括:
Protocol Buffers(也称为 protobuf)是由 Google 开发的序列化格式,用于对结构化数据进行高效序列化。 它使用强类型定义文件来定义消息结构。 然后,将这些定义文件编译为用于对消息进行序列化和反序列化的特定语言代码。 Protobuf 可用于现有的 RPC 机制,还可以生成 RPC 服务。
Apache Thrift 使用类似的方法,即使用强类型定义文件和编译步骤生成序列化代码和 RPC 服务。
Apache Avro 向 Protocol Buffers 和 Thrift 提供类似的功能,但不提供编译步骤。 相反,序列化数据始终包含描述结构的架构。
JSON 是使用可人工读取的文本字段的开放标准。 它提供广泛的跨平台支持。 JSON 不使用消息架构。 它是基于文本的格式,在网络上的效率不高。 但是,在某些情况下,可通过 HTTP 直接向客户端返回缓存项,此时,存储 JSON 可以节省从另一格式反序列化然后再序列化为 JSON 的成本。
二进制 JSON (BSON) 是一种二进制序列化格式,使用的结构与 JSON 类似。 相对于 JSON,BSON 旨在轻量、易于扫描以及可快速进行序列化和反序列化。 其有效负载的大小与 JSON 相当。 BSON 有效负载可能大于或小于 JSON 有效负载,具体取决于数据。 BSON 拥有 JSON 中不支持的一些其他数据类型,尤其是 BinData(用于字节数组)和日期。
MessagePack 是旨在压缩网络传输的二进制序列化格式。 没有消息架构或消息类型检查。
Bond 是用于系统化数据的跨平台框架。 它支持跨语言序列化和反序列化。 此处列出的与其他系统的显著差异包括对继承、类型别名和泛型的支持。
gRPC 是由 Google 开发的开源 RPC 系统。 默认情况下,它将 Protocol Buffers 用作其定义语言和基础消息交换格式。
后续步骤
相关资源
在应用程序中实施缓存时,以下模式也可能与方案相关: