演练:调试 C++ AMP 应用程序
本文演示如何对使用 C++ Accelerated Massive Parallelism (C++ AMP) 来利用图形处理单元 (GPU) 的应用程序进行调试。 它使用总结大整数数组的并行缩减程序。 本演练阐释了以下任务:
- 启动 GPU 调试器。
- 在“GPU 线程”窗口中检查 GPU 线程。
- 使用“并行堆栈”窗口来同时查看多个 GPU 线程调用堆栈。
- 使用“并行监视”窗口来同时检查单个表达式在多个线程中的值。
- 标记、冻结、解冻和组合 GPU 线程。
- 将 Tile 的所有线程执行到代码中的特定位置。
先决条件
在开始本演练之前:
注意
从 Visual Studio 2022 版本 17.0 开始,已弃用 C++ AMP 标头。
包含任何 AMP 标头都会导致生成错误。 应在包含任何 AMP 标头之前定义 _SILENCE_AMP_DEPRECATION_WARNINGS,以使警告静音。
- 阅读 C++ AMP 概述。
- 确保文本编辑器中显示行号。 有关详细信息,请参阅如何:在编辑器中显示行号。
- 确保至少运行的是 Windows 8 或 Windows Server 2012 以支持在软件仿真器上进行调试。
注意
以下说明中的某些 Visual Studio 用户界面元素在计算机上出现的名称或位置可能会不同。 这些元素取决于你所使用的 Visual Studio 版本和你所使用的设置。 有关详细信息,请参阅个性化设置 IDE。
创建示例项目
创建项目的说明因使用的 Visual Studio 版本而异。 确保在此页面上的目录上方选择了正确的文档版本。
在 Visual Studio 中创建示例项目
在菜单栏上,选择“文件”>“新建”>“项目”,打开“创建新项目”对话框 。
在对话框顶部,将“语言”设置为“C++”,将“平台”设置为“Windows”,并将“项目类型”设置为“控制台”。
从筛选的项目类型列表中,选择“控制台应用”,然后选择“下一步” 。 在下一页中的“名称”框内输入
AMPMapReduce以指定项目的名称,如果需要其他名称,请指定项目位置。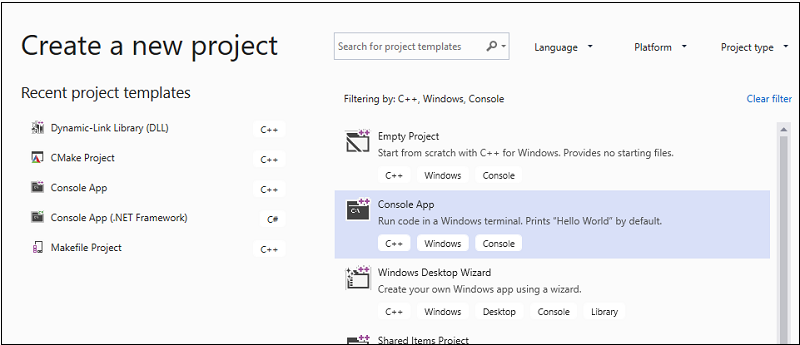
选择“创建”按钮创建客户端项目。
在 Visual Studio 2017 或 Visual Studio 2015 中创建示例项目
启动 Visual Studio。
在菜单栏上,依次选择“文件”>“新建”>“项目”。
在模板窗格的“已安装”下,选择“Visual C++”。
选择“Win32 控制台应用程序”,在“名称”框中键入
AMPMapReduce,然后选择“确定”按钮。选择“下一步”按钮 。
清除“预编译标头”复选框,然后选择“完成”按钮。
在“解决方案资源管理器”中,删除项目中的 stdafx.h、targetver.h 和 stdafx.cpp。
下一步:
打开 AMPMapReduce.cpp 并用下面的代码替换其中的内容。
// AMPMapReduce.cpp defines the entry point for the program. // The program performs a parallel-sum reduction that computes the sum of an array of integers. #include <stdio.h> #include <tchar.h> #include <amp.h> const int BLOCK_DIM = 32; using namespace concurrency; void sum_kernel_tiled(tiled_index<BLOCK_DIM> t_idx, array<int, 1> &A, int stride_size) restrict(amp) { tile_static int localA[BLOCK_DIM]; index<1> globalIdx = t_idx.global * stride_size; index<1> localIdx = t_idx.local; localA[localIdx[0]] = A[globalIdx]; t_idx.barrier.wait(); // Aggregate all elements in one tile into the first element. for (int i = BLOCK_DIM / 2; i > 0; i /= 2) { if (localIdx[0] < i) { localA[localIdx[0]] += localA[localIdx[0] + i]; } t_idx.barrier.wait(); } if (localIdx[0] == 0) { A[globalIdx] = localA[0]; } } int size_after_padding(int n) { // The extent might have to be slightly bigger than num_stride to // be evenly divisible by BLOCK_DIM. You can do this by padding with zeros. // The calculation to do this is BLOCK_DIM * ceil(n / BLOCK_DIM) return ((n - 1) / BLOCK_DIM + 1) * BLOCK_DIM; } int reduction_sum_gpu_kernel(array<int, 1> input) { int len = input.extent[0]; //Tree-based reduction control that uses the CPU. for (int stride_size = 1; stride_size < len; stride_size *= BLOCK_DIM) { // Number of useful values in the array, given the current // stride size. int num_strides = len / stride_size; extent<1> e(size_after_padding(num_strides)); // The sum kernel that uses the GPU. parallel_for_each(extent<1>(e).tile<BLOCK_DIM>(), [&input, stride_size] (tiled_index<BLOCK_DIM> idx) restrict(amp) { sum_kernel_tiled(idx, input, stride_size); }); } array_view<int, 1> output = input.section(extent<1>(1)); return output[0]; } int cpu_sum(const std::vector<int> &arr) { int sum = 0; for (size_t i = 0; i < arr.size(); i++) { sum += arr[i]; } return sum; } std::vector<int> rand_vector(unsigned int size) { srand(2011); std::vector<int> vec(size); for (size_t i = 0; i < size; i++) { vec[i] = rand(); } return vec; } array<int, 1> vector_to_array(const std::vector<int> &vec) { array<int, 1> arr(vec.size()); copy(vec.begin(), vec.end(), arr); return arr; } int _tmain(int argc, _TCHAR* argv[]) { std::vector<int> vec = rand_vector(10000); array<int, 1> arr = vector_to_array(vec); int expected = cpu_sum(vec); int actual = reduction_sum_gpu_kernel(arr); bool passed = (expected == actual); if (!passed) { printf("Actual (GPU): %d, Expected (CPU): %d", actual, expected); } printf("sum: %s\n", passed ? "Passed!" : "Failed!"); getchar(); return 0; }在菜单栏上,依次选择“文件”>“全部保存”。
在“解决方案资源管理器”中,打开“AMPMapReduce”的快捷菜单,然后选择“属性”。
在“属性页”对话框中的“配置属性”下,选择“C/C++”>“预编译标头”。
对于“预编译标头”属性,选择“不使用预编译标头”,然后选择“确定”按钮。
在菜单栏上,依次选择“生成”>“生成解决方案” 。
调试 CPU 代码
在此过程中,将使用本地 Windows 调试器,以确保此应用程序中的 CPU 代码是正确的。 在此应用程序中,特别值得关注的 CPU 代码段是 for 函数中的 reduction_sum_gpu_kernel 循环。 它控制运行在 GPU 上的基于树的并行缩减。
调试 CPU 代码
在“解决方案资源管理器”中,打开“AMPMapReduce”的快捷菜单,然后选择“属性”。
在“属性页”对话框中的“配置属性”下,选择“调试”。 在“要启动的调试器”列表中,确认选择了“本地 Windows 调试器”。
返回到“代码编辑器”。
在下图所示的代码行上设置断点(大约第 67 和 70 行)。

CPU 断点在菜单栏上,依次选择“调试”>“开始调试”。
在“局部变量”窗口中,观察
stride_size的值,直至到达第 70 行的断点。在菜单栏上,依次选择“调试”>“停止调试”。
调试 GPU 代码
本部分说明如何调试 GPU 代码,即 sum_kernel_tiled 函数包含的代码。 GPU 代码为每个“块”并行计算整数和。
调试 GPU 代码
在“解决方案资源管理器”中,打开“AMPMapReduce”的快捷菜单,然后选择“属性”。
在“属性页”对话框中的“配置属性”下,选择“调试”。
在“要启动的调试器”列表中,选择“本地 Windows 调试器” 。
在“调试器类型”列表中,确认选择了“自动”。
“自动”是默认值。 在 Windows 10 之前的版本中,“仅限 GPU”是所需的值,而不是“自动”。
选择 “确定” 按钮。
如下图所示,在第 30 行处设置一个断点。

GPU 断点在菜单栏上,依次选择“调试”>“开始调试”。 CPU 代码中第 67 行和第 70 行的断点在 GPU 调试期间不会执行,因为这些代码行在 CPU 上运行。
使用“GPU 线程”窗口
若要打开“GPU 线程”窗口,请在菜单栏上选择“调试”>“窗口”>“GPU 线程”。
在出现的“GPU 线程”窗口中,可以检查 GPU 线程的状态。
将“GPU 线程”窗口停靠在 Visual Studio 底部。 选择“展开线程切换”按钮以显示图块和线程文本框。 如下图所示,“GPU 线程”窗口显示活动和受阻的 GPU 线程的总数。

“GPU 线程”窗口为此计算分配了 313 个图块。 每个 Tile 包含 32 个线程。 由于本地 GPU 调试在软件模拟器中进行,因此有四个活动的 GPU 线程。 四个线程同时执行指令,然后一起移动到下一条指令。
在“GPU 线程”窗口,有四个 GPU 线程处于活动状态,大约第 21 行 (
t_idx.barrier.wait();) 定义的 tile_barrier::wait 语句处有 28 个 GPU 线程受阻。 所有这 32 个GPU 线程都属于第一个 Tiletile[0]。 当前线程所在的行由箭头指示。 若要切换到其他线程,请使用下列方法之一:在“GPU 线程”窗口中要切换到的线程所在的行中,打开快捷菜单,然后选择“切换到线程”。 如果该行代表多个线程,将按线程坐标切换到第一个线程。
在相应的文本框中输入线程的图块和线程值,然后选择“切换线程”按钮。
“调用堆栈”窗口将显示当前 GPU 线程的调用堆栈。
使用“并行堆栈”窗口
若要打开“并行堆栈”窗口,请在菜单栏上依次选择“调试”>“窗口”>“并行堆栈”。
可以使用“并行堆栈”窗口同时检查多个 GPU 线程的堆栈帧。
将“并行堆栈”窗口停靠在 Visual Studio 底部。
确保在左上角的列表中选择“线程”。 在下图中,“并行堆栈”窗口显示了你在“GPU 线程”窗口看到的 GPU 线程的调用堆栈集中视图。

“并行堆栈”窗口32 个线程从
_kernel_stub执行到parallel_for_each函数调用中的 lambda 语句,随后执行到sum_kernel_tiled函数,再从这里进行并行缩减。 在这 32 个线程中,28 个线程前进到tile_barrier::wait语句并在第 22 行处保持受阻状态,而其他 4 个线程则在第 30 行处的sum_kernel_tiled函数中保持活动状态。可以检查 GPU 线程的属性。 它们位于“并行堆栈”窗口的丰富数据提示中的“GPU 线程”窗口中。 若要查看它们,请将指针悬停在
sum_kernel_tiled的堆栈帧上。 下图显示了数据提示。
GPU 线程数据提示有关“并行堆栈”窗口的详细信息,请参阅使用“并行堆栈”窗口。
使用“并行监视”窗口
若要打开“并行监视”窗口,请在菜单栏上依次选择“调试”>“窗口”>“并行监视”>“并行监视 1”。
可以使用“并行监视”窗口来检查某表达式在多个线程中的值。
将“并行监视 1”窗口停靠在 Visual Studio 底部。 “并行监视”窗口的表中有 32 行。 每个行对应于同时出现在“GPU 线程”窗口和“并行堆栈”窗口的 GPU 线程。 现在,可以输入所需的表达式,以检查其在所有这 32 个 GPU 线程中的值。
选择“添加监视”列标题,输入
localIdx,然后按 Enter 键。再次选择“添加监视”列标题,输入
globalIdx,然后按 Enter 键。再次选择“添加监视”列标题,输入
localA[localIdx[0]],然后按 Enter 键。您可以通过选择相应的列标题来按指定表达式排序。
选择“localA[localIdx[0]]”列标题对列排序。 下图显示了按“localA[localIdx[0]]”排序的结果。

排序结果通过选择“Excel”按钮并选择“在 Excel 中打开”,可将“并行监视”窗口中的内容导出到 Excel。 如果开发计算机上安装有 Excel,该按钮将打开包含该内容的 Excel 工作表。
“并行监视”窗口的右上角有一个筛选器控件,可用于通过布尔表达式来筛选内容。 在筛选器控件文本框中输入
localA[localIdx[0]] > 20000,然后按 Enter 键。该窗口现在只包含
localA[localIdx[0]]值大于 20000 的线程。 内容仍按localA[localIdx[0]]列排序,这是之前选择的排序操作。
标记 GPU 线程
通过在“GPU 线程”窗口、“并行监视”窗口或“并行堆栈”窗口的数据提示中进行标记,可以标记特定的 GPU 线程。 如果“GPU 线程”窗口中的某一行包含多个线程,则通过标记该行,可标记该行中包含的所有线程。
标记 GPU 线程
在“并行监视 1”窗口中选择“[线程]”列标题,以按图块索引和线程索引进行排序。
在菜单栏上,依次选择“调试”>“继续”,将使处于活动状态的四个线程前进到下一个屏障(在 AMPMapReduce.cpp 的第 32 行处定义)。
在当前处于活动状态的四个线程所在行的左侧,选择标志符号。
下图显示了“GPU 线程”窗口中经过标记的四个活动线程。

GPU 线程窗口中的活动线程“并行监视”窗口和“并行堆栈”窗口的数据提示都会指示已标记的线程。
如果要关注所标记的四个线程,可以选择仅显示标记的线程。 它限制了在“GPU 线程”、“并行监视”和“并行堆栈”窗口中看到的内容。
在上述任一窗口或在“调试位置”工具栏中,选择“仅显示已标记项”按钮。 下图显示了“调试位置”工具栏中的“仅显示已标记项”按钮。

“仅显示已标记项”按钮现在,“GPU 线程”、“并行监视”和“并行堆栈”窗口将仅显示标记的线程。
冻结和解冻 GPU 线程
可以从“GPU 线程”窗口或“并行监视”窗口冻结(挂起)和解冻(恢复)GPU 线程。 可以通过相同的方法冻结和解冻 CPU 线程;有关信息,请参阅如何:使用“线程”窗口。
冻结和解冻 GPU 线程
选择“仅显示已标记项”按钮,以显示所有线程。
在菜单栏上,依次选择“调试”>“继续”。
打开活动行的快捷菜单,然后选择“冻结”。
下图中的“GPU 线程”窗口显示,所有四个线程均已冻结。

“GPU 线程”窗口中的已冻结线程同样,“并行监视”窗口也显示,所有四个线程均已冻结。
在菜单栏上,依次选择“调试”>“继续”,让下面四个 GPU 线程通过第 22 行处的屏障并到达第 30 行处的断点。 “GPU 线程”窗口显示,之前冻结的四个线程仍被冻结并处于活动状态。
在菜单栏上,依次选择“调试”和“继续”。
从“并行监视”窗口中,还可以单独解冻一个或同时解冻多个 GPU 线程。
对 GPU 线程分组
在“GPU 线程”窗口中任一线程的快捷菜单上,依次选择“分组依据”和“地址”。
“GPU 线程”窗口中的线程随即按地址分组。 该地址对应于每组线程所在的反汇编指令。 24 个线程位于第 22 行处,这里执行 tile_barrier::wait 方法。 12 个线程位于第 32 行屏障的指令处。 其中 4 个线程经过标记。 8 个线程位于第 30 行的断点处。 其中 4 个线程已冻结。 下图显示了“GPU 线程”窗口中经过分组的线程。

“GPU 线程”窗口中经过分组的线程还可以通过打开“并行监视”窗口的数据网格的快捷菜单来执行“分组依据”操作。 选择“分组依据”,然后选择与要如何对线程进行分组相对应的菜单项。
将所有线程运行到代码中的特定位置
通过使用“将当前图块运行到光标处”,可将给定图块中的所有线程运行到光标所在的行。
将所有线程运行到光标指示的位置
在冻结线程的快捷菜单上,选择“解冻”。
在“代码编辑器”中,将光标置于第 30 行内。
在“代码编辑器”的快捷菜单中,选择“将当前图块运行到光标处”。
之前在第 21 行处受阻的 24 个线程将继续运行到第 32 行。 “GPU 线程”窗口显示了这一过程。
另请参阅
C++ AMP 概述
调试 GPU 代码
如何:使用“GPU 线程”窗口
如何:使用“并行监视”窗口
使用并发可视化工具分析 C++ AMP 代码