你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Netezza 迁移的设计和性能
本文是一个包含七部分内容的系列的第一部分,提供有关如何从 Netezza 迁移到 Azure Synapse Analytics 的指导。 本文的重点是设计和性能的最佳做法。
概述
由于 IBM 终止支持,Netezza 数据仓库系统的许多现有用户希望利用新式云环境提供的创新。 通过基础结构即服务 (IaaS) 和平台即服务 (PaaS) 云环境,你可以将基础结构维护和平台开发等任务委托给云提供商。
提示
Azure 环境不仅包括数据库,还包括一组全面的功能和工具。
尽管 Netezza 和 Azure Synapse Analytics 都是 SQL 数据库,它们使用大规模并行处理 (MPP) 技术在异常大的数据量上实现高查询性能,不过方法上存在一些基本差异:
旧版 Netezza 系统通常安装在本地并使用专有硬件,而 Azure Synapse 基于云并使用 Azure 存储和计算资源。
升级 Netezza 配置是一项主要任务,涉及额外的物理硬件和可能冗长的数据库重新配置或转储和重新加载。 由于存储和计算资源在 Azure 环境中是分开的,并且具有弹性缩放功能,因此这些资源可以独立纵向扩展或缩减。
可以根据需要暂停或重设 Azure Synapse 的大小,从而降低资源利用率和成本。
Microsoft Azure 是全球可用的、高度安全且可缩放的云环境,其中包括 Azure Synapse 和一个由支持性工具和功能构成的生态系统。 下图汇总了 Azure Synapse 生态系统。
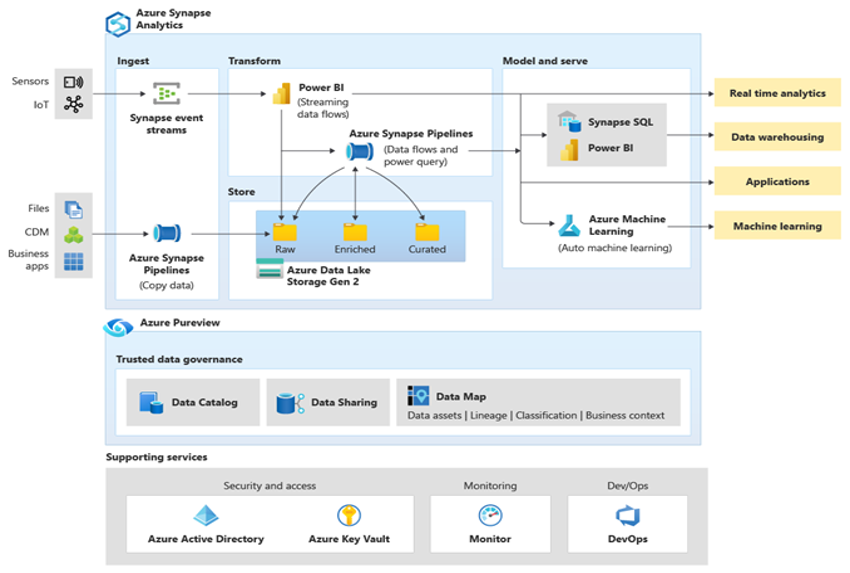
Azure Synapse 通过使用 MPP 等技术和常用数据的多级自动缓存,提供最佳关系数据库性能。 可以在独立基准中查看这些技术的结果,例如 GigaOm 最近运行的基准,它将 Azure Synapse 与其他常见云数据仓库产品/服务进行了比较。 迁移到 Azure Synapse 环境的客户可获得许多好处,包括:
更优的性能和性价比。
提高了灵活性,缩短了价值实现时间。
更快的服务器部署和应用程序开发。
弹性可伸缩性 - 仅为实际使用量付费。
改进的安全性/合规性。
降低了存储和灾难恢复成本。
更低的整体总拥有成本 (TCO)、更好的成本控制和精简的运营支出 (OPEX)。
为了最大限度地发挥这些优势,请将新的或现有的数据和应用程序迁移到 Azure Synapse 平台。 在许多组织中,迁移包括将现有数据仓库从旧的本地平台(例如 Netezza)移动到 Azure Synapse。 大致来说,迁移过程包括以下步骤:
准备工作 🡆
定义范围 - 要迁移的内容。
生成用于迁移的数据和进程的清单。
定义数据模型更改(如果有)。
定义源数据提取机制。
确定要使用的适当的 Azure 和第三方工具及功能。
尽早在新平台上培训员工。
设置 Azure 目标平台。
迁移 🡆
从小规模开始。
尽可能自动化。
利用 Azure 内置工具和功能来减少迁移工作量。
迁移表和视图的元数据。
迁移要维护的历史数据。
迁移或重构存储过程和业务流程。
迁移或重构 ETL/ELT 增量加载流程。
迁移后
监视和记录进程的所有阶段。
使用获得的经验为未来的迁移生成模板。
根据需要,重新设计数据模型(使用新的平台性能和可伸缩性)。
测试应用程序和查询工具。
基准和优化查询性能。
本文提供了将数据仓库从现有 Netezza 环境迁移到 Azure Synapse 时性能优化的一般信息和指南。 性能优化的目标是在架构迁移后,在 Azure Synapse 中实现相同或更好的数据仓库性能。
设计注意事项
迁移范围
准备从 Netezza 环境迁移时,请考虑以下迁移选择。
选择初始迁移的工作负载
通常,旧版的 Netezza 环境随着时间的推移而发展,从而涵盖多个主题领域和混合工作负载。 决定开始迁移项目的位置时,请选择一个可以执行以下操作的区域:
通过快速提供新环境的优势,证明迁移到 Azure Synapse 的可行性。
内部技术人员可以获得在迁移其他领域时使用的流程和工具的相关经验。
为进一步的迁移创建模板,该模板特定于源 Netezza 环境以及当前已经到位的工具和流程。
从 Netezzaa 环境进行初始迁移的良好候选支持上述项,并且:
实现 BI/Analytics 工作负载而不是联机事务处理 (OLTP) 工作负载。
具有数据模型(如星型或雪花型架构),只需最少的修改即可迁移。
提示
创建需要迁移的对象清单,并记录迁移过程。
初始迁移中的迁移数据量应该足够大,能够展示 Azure Synapse 环境的功能和优势,但又不能太大而无法快速展示价值。 大小范围通常介于 1-10 TB 之间。
对于初始迁移项目,请最大程度减少风险、工作量和迁移时间,以便可以快速查看 Azure 云环境的优势。 直接迁移和分阶段迁移方法都将初始迁移的范围限制为仅数据市场,并且不处理有关迁移的更广泛的方面(例如 ETL 迁移和历史数据迁移)。 但是,一旦迁移的数据市场层回填了数据和所需的生成过程,即可在项目的后期阶段处理这些方面。
直接迁移与分阶段方法
通常,无论计划迁移的目的和范围如何,都有两种类型的迁移:直接迁移以及包含更改的分阶段方法。
直接迁移
在直接迁移中,现有数据模型(如星型架构)将按原样迁移到新的 Azure Synapse 平台。 此方法通过减少实现迁移到 Azure 云环境的优势所需的工作,将风险和迁移时间降到最低。 直接迁移非常适合以下场景:
- 具有现有的 Netezza 环境,其中包含单个要迁移的数据市场,或者
- 具有现有的 Netezza 环境,其中的数据已经在精心设计的星型或雪花型架构中,或者
- 面临着迁移到新式云环境的时间和成本压力。
提示
直接迁移是一个很好的起点,即使后续阶段实现了对数据模型的更改也是如此。
包含更改的分阶段方法
如果旧的数据仓库已经发展了很长时间,可能需要对其进行重新设计,从而维持所需的性能级别。 可能还需要重新设计以支持物联网 (IoT) 流等新数据。 作为重新设计过程的一部分,迁移到 Azure Synapse 能获得可缩放云环境的好处。 迁移还包括基础数据模型的更改(如从 Inmon 模型迁移到数据保管库)。
Microsoft 建议将现有数据模型按原样移动到 Azure,并使用 Azure 环境的性能和灵活性来应用重新设计的更改。 这样,可以使用 Azure 的功能进行更改,而不会影响现有的源系统。
使用 Azure 数据工厂实现元数据驱动的迁移
可以使用 Azure 环境的功能来自动执行和协调迁移进程。 此方法将对现有 Netezza 环境的性能影响降至最低,尤其是在该环境已接近运行容量上限时。
Azure 数据工厂是一种基于云的数据集成服务,支持在云中创建数据驱动的工作流,以协调和自动执行数据移动和数据转换。 可以使用数据工厂创建和计划数据驱动工作流(管道),这些工作流从不同的数据存储中引入数据。 数据工厂可使用如 Azure HDInsight Hadoop、Spark、Azure Data Lake Analytics 和 Azure 机器学习等计算服务处理和转换数据。
计划使用数据工厂设施来管理迁移进程时,请创建列出所有要迁移的数据表及其位置的元数据。
Netezza 与 Azure Synapse 之间的设计差异
如前所述,Netezza 和 Azure Synapse Analytics 数据库在方法上存在一些基本差异,接下来将讨论这些差异。
多个数据库与单个数据库和架构
Netezza 环境通常包含多个单独的数据库。 例如,可能有单独的数据库用于:数据引入和临时表、核心仓库表和数据市场(有时称为语义层)。 ETL 或 ELT 管道进程可能会实现跨数据库联接,并在单独的数据库之间移动数据。
相反,Azure Synapse 环境包含单一数据库,并使用架构将表划分为逻辑上独立的组。 我们建议在目标 Azure Synapse 数据库中使用一系列架构来模拟从 Netezza 环境迁移的单独数据库。 如果 Netezza 环境已使用架构,在将现有 Netezza 表和视图移动到新环境时可能需要使用新的命名约定。 例如,可以将现有的 Netezza 架构和表名连接到新的 Azure Synapse 表名中,并在新环境中使用架构名来维护原始的单独数据库名。 如果架构合并命名包含点,Azure Synapse Spark 可能会出现问题。 尽管可以使用基础表上的 SQL 视图来维护逻辑结构,但此方法也有潜在的缺点:
Azure Synapse 中的视图是只读的,因此必须在基础基表上对数据进行任何更新。
可能已经存在一个或多个视图层,添加额外的视图层可能会影响性能和可支持性,因为嵌套视图难以排除故障。
提示
在 Azure Synapse 中将多个数据库合并到单一数据库,并使用架构名在逻辑上分隔表。
表注意事项
在不同环境之间迁移表时,通常只有原始数据和描述它的元数据进行物理迁移。 源系统中的其他数据库元素(例如索引)通常不会迁移,因为在新环境中它们可能是不必要的,或者实现方式不同。
源环境中的性能优化(例如索引)指示可以在新环境中添加性能优化的位置。 例如,如果源 Netezza 环境中的查询经常使用区域映射,表明应在 Azure Synapse 中创建非聚集索引。 表复制等其他原生性能优化技术可能比直接创建同类索引更适用。
提示
现有索引指示已迁移的仓库中的候选索引。
不支持的 Netezza 数据库对象类型
Azure Synapse 功能经常替换特定于 Netezza 的功能。 但 Azure Synapse 不直接支持某些 Netezza 数据库对象。 以下不受支持的 Netezza 数据库对象列表描述了如何在 Azure Synapse 中实现等效功能。
区域映射:在 Netezza 中,会自动为以下列类型创建和维护区域映射,并在查询时用于限制要扫描的数据量:
- 长度不超过 8 字节的
INTEGER列。 - 时态列,例如
DATE、TIME和TIMESTAMP。 CHAR列(如果它们是具体化视图的一部分并在ORDER BY子句中提及)。
可使用 NZ 工具包中的
nz_zonemap实用工具查找哪些列有区域映射。 Azure Synapse 不包括区域映射,但你可使用其他用户定义的索引类型和/或分区来实现类似的结果。- 长度不超过 8 字节的
聚集基表 (CBT):在 Netezza 中,CBT 通常用于事实数据表,这些表可包含数十亿条记录。 扫描如此庞大的表需要相当长的处理时间,因为可能需要进行全表扫描才能获取相关记录。 通过在限制性 CBT 中组织记录,Netezza 可以对相同或邻近盘区内的记录进行分组。 此过程还会创建区域映射,通过减少需要扫描的数据量来提升性能。
在 Azure Synapse 中,可以通过分区和/或使用其他索引来实现类似的效果。
具体化视图:Netezza 支持具体化视图。如果查询中经常使用少数列,建议对具有多列的大型表使用一个或多个具体化视图。 更新基表中的数据时,系统会自动刷新具体化视图。
Azure Synapse 支持具体化视图,其功能与 Netezza 相同。
Netezza 数据类型映射
大多数 Netezza 数据类型在 Azure Synapse 中都有直接的等效项。 下表显示了将 Netezza 数据类型映射到 Azure Synapse 的推荐方法。
| Netezza 数据类型 | Azure Synapse 数据类型 |
|---|---|
| BIGINT | BIGINT |
| BINARY VARYING(n) | VARBINARY(n) |
| BOOLEAN | BIT |
| BYTEINT | TINYINT |
| CHARACTER VARYING(n) | VARCHAR(n) |
| CHARACTER(n) | CHAR(n) |
| DATE | DATE(date) |
| DECIMAL(p,s) | DECIMAL(p,s) |
| DOUBLE PRECISION | FLOAT |
| FLOAT(n) | FLOAT(n) |
| INTEGER | INT |
| INTERVAL | Azure Synapse 目前不直接支持 INTERVAL 数据类型,但可以使用时态函数(例如 DATEDIFF)进行计算 |
| MONEY | MONEY |
| NATIONAL CHARACTER VARYING(n) | NVARCHAR(n) |
| NATIONAL CHARACTER(n) | NCHAR(n) |
| NUMERIC(p,s) | NUMERIC(p,s) |
| REAL | REAL |
| SMALLINT | SMALLINT |
| ST_GEOMETRY(n) | Azure Synapse 目前不支持空间数据类型(如 ST_GEOMETRY),但数据可以作为 VARCHAR 或 VARBINARY 进行存储。 |
| TIME | TIME |
| TIME WITH TIME ZONE | DATETIMEOFFSET |
| TIMESTAMP | DATETIME |
提示
在迁移准备阶段评估不受支持数据类型的数量和类型。
第三方供应商提供工具和服务来自动迁移,包括数据类型的映射。 如果已在 Netezza 环境中使用第三方 ETL 工具,请使用该工具来实现任何所需的数据转换。
SQL DML 语法差异
Netezza SQL 和 Azure Synapse T-SQL 之间存在 SQL DML 语法差异。 最小化 Netezza 迁移的 SQL 问题中详细讨论了这些差异。
STRPOS:在 Netezza 中,STRPOS函数返回字符串中 substring 的位置。 Azure Synapse 中的等效函数是CHARINDEX,参数的顺序颠倒了。 例如,Netezza 中的SELECT STRPOS('abcdef','def')...等效于 Azure Synapse 中的SELECT CHARINDEX('def','abcdef')...。AGE:Netezza 支持AGE运算符,以便在两个时态值(如时间戳或日期)之间提供间隔,例如:SELECT AGE('23-03-1956','01-01-2019') FROM...。 在 Azure Synapse 中,使用DATEDIFF获取间隔,例如:SELECT DATEDIFF(day, '1956-03-26','2019-01-01') FROM...。 记下日期表示形式序列。NOW():Netezza 使用NOW()在 Azure Synapse 中代表CURRENT_TIMESTAMP。
函数、存储过程和序列
从 Netezza 等成熟环境迁移数据仓库时,可能需要迁移简单表和视图以外的元素。 检查 Azure 环境中的工具是否可以替换函数、存储过程和序列的功能,因为使用内置 Azure 工具通常比为 Azure Synapse 重新编码这些元素更高效。
作为准备阶段的一部分,请创建需要迁移的对象清单,定义处理它们的方法,并在迁移计划中分配适当的资源。
数据集成合作伙伴提供可自动迁移函数、存储过程以及序列的工具和服务。
以下部分进一步讨论函数、存储过程和序列的迁移。
函数
与大多数数据库产品一样,Netezza 支持 SQL 实现中的系统和用户定义的函数。 将旧数据库平台迁移到 Azure Synapse 时,通常无需更改即可迁移常用系统函数。 某些系统函数的语法可能略有不同,但任何所需的更改都可以自动化。
对于在 Azure Synapse 中没有等效函数的 Netezza 系统函数或任意用户定义函数,请使用目标环境语言重新编码这些函数。 Netezza 用户定义的函数用 nzlua 或 C++ 语言进行编码。 Azure Synapse 使用 Transact-SQL 语言来实现用户定义的函数。
存储过程
大多数新式数据库产品都支持在数据库中存储过程。 为此,Netezza 提供了基于 Postgres PL/pgSQL 的 NZPLSQL 语言。 存储过程通常包含 SQL 语句和过程逻辑,并返回数据或状态。
Azure Synapse 支持使用 T-SQL 的存储过程,因此需要使用该语言重新编码任何迁移的存储过程。
序列
在 Netezza 中,序列是使用 CREATE SEQUENCE 创建的命名数据库对象。 序列通过 NEXT VALUE FOR 方法提供唯一的数值。 可以使用生成的唯一编号作为主键的代理键值。
Azure Synapse 未实现 CREATE SEQUENCE,但你可以使用 IDENTITY 列或 SQL 代码来实现序列,以生成系列中的下一个序列号。
从 Netezza 环境提取元数据和数据
数据定义语言 (DDL) 生成
ANSI SQL 标准定义了数据定义语言 (DDL) 命令的基本语法。 某些 DDL 命令,例如 CREATE TABLE 和 CREATE VIEW,对 Netezza 和 Azure Synapse 都是通用的,但已扩展为提供特定于实现的功能。
可以编辑现有的 Netezza CREATE TABLE 和 CREATE VIEW 脚本,用于在 Azure Synapse 中实现等效定义。 为此,可能需要使用修改后的数据类型,并删除或修改特定于 Netezza 的子句,例如 ORGANIZE ON。
在 Netezza 环境中,系统目录表指定当前表和视图定义。 与用户维护的文档不同,系统目录信息始终是完整的并与当前表定义同步。 通过使用 nz_ddl_table 等实用工具,可以访问系统目录信息来生成 CREATE TABLE DDL 语句,该语句能在 Azure Synapse 中创建等效表。
还可以使用处理系统目录信息的第三方迁移和 ETL 工具来实现类似结果。
从 Netezza 提取数据
可以使用 nzsql 和 nzunload 等标准 Netezza 实用工具或通过外部表将原始表数据从 Netezza 表提取到带分隔符的平面文件,例如 CSV 文件。 然后,可以使用 gzip 压缩带分隔符的平面文件,并使用 AzCopy 或 Azure Data Box 等 Azure 数据传输工具将压缩文件上传到 Azure Blob 存储。
尽可能高效地提取表数据。 使用外部表方法,因为它是最快的提取方法。 并行执行多个提取可将数据提取吞吐量最大化。 以下 SQL 语句执行外部表提取:
CREATE EXTERNAL TABLE '/tmp/export_tab1.csv' USING (DELIM ',') AS SELECT * from <TABLENAME>;
如果提供有足够的网络带宽,可以将数据从本地 Netezza 系统直接提取到 Azure Synapse 表或 Azure Blob 数据存储中。 为此,请使用数据工厂进程或第三方数据迁移或 ETL 产品。
提示
使用 Netezza 外部表进行最高效的数据提取。
提取的数据文件应包含 CSV、优化行纵栏表 (ORC) 或 Parquet 格式的带分隔符的文本。
有关从 Netezza 环境迁移数据和 ETL 的详细信息,请参阅 Netezza 迁移的数据迁移、ETL 和加载。
有关 Netezza 迁移的性能建议
性能优化的目标是:迁移到 Azure Synapse 后,数据仓库性能未变或更好。
性能优化方法概念的相似性
Netezza 数据库的许多性能优化概念适用于 Azure Synapse 数据库。 例如:
使用数据分发将要联接的数据并置在同一处理节点上。
对给定列使用最小数据类型可节省存储空间,并加速查询处理。
确保要联接的列具有同一数据类型,以便优化联接处理并减少对数据转换的需求。
为了帮助优化器生成最佳执行计划,请确保统计信息是最新的。
使用内置数据库功能监视性能可确保有效使用资源。
提示
在迁移开始时,优先熟悉 Azure Synapse 中的优化选项。
性能优化方法的差异
此部分重点介绍 Netezza 和 Azure Synapse 之间的低级别性能优化实现差异。
数据分发选项
在性能方面,Azure Synapse 采用多节点体系结构设计并使用并行处理。 若要优化表性能,可以使用 Azure Synapse 中的 DISTRIBUTION 和 Netezza 中的 DISTRIBUTE ON 在 CREATE TABLE 语句中定义数据分发选项。
与 Netezza 不同,Azure Synapse 支持通过小型表复制在小型表和大型表之间进行本地联接。 例如,考虑星型架构模型中的小型维度表和大型事实数据表。 Azure Synapse 可以跨所有节点复制较小的维度表,以确保大型表的任何联接键的值都具有匹配的本地可用的维度行。 对于小型维度表,维度表复制的开销相对较低。 对于大型维度表,哈希分发方法更适用。 有关数据分发选项的详细信息,请参阅使用复制表的设计指南和设计分布式表的指南。
数据索引
Azure Synapse 支持多个用户可定义的索引选项,与 Netezza 中的系统托管区域映射相比,这些选项具有不同的操作和用法。 有关 Azure Synapse 中不同索引选项的详细信息,请参阅专用 SQL 池表上的索引。
源 Netezza 环境中的现有系统托管区域映射提供了数据使用情况的有用指示和 Azure Synapse 环境中用于索引的候选列。
数据分区
在企业数据仓库中,事实数据表可以包含数十亿行。 分区通过将这些表拆分为单独的部件来减少已处理的数据量,从而优化了这些表的维护和查询性能。 在 Azure Synapse 中,CREATE TABLE 语句定义表的分区规范。
每个表只能使用一个字段进行分区。 该字段通常是日期字段,因为许多查询是按日期或日期范围筛选的。 可以在初始加载后更改表的分区,方法是使用 CREATE TABLE AS (CTAS) 语句重新创建具有新分布的表。 有关 Azure Synapse 中分区的详细讨论,请参阅专用 SQL 池中的分区表。
数据表统计信息
应该通过在 ETL/ELT 作业中生成统计信息步骤来确保数据表的统计信息是最新的。
用于数据加载的 PolyBase 或 COPY INTO
PolyBase 使用并行加载流来支持将大量数据高效加载到数据仓库。 有关详细信息,请参阅 PolyBase 数据加载策略。
COPY INTO 也支持高吞吐量数据引入及:
从文件夹和子文件夹中的所有文件中检索数据。
从同一存储帐户中的多个位置检索数据。 可以使用逗号分隔的路径指定多个位置。
Azure Data Lake Storage (ADLS) 和 Azure Blob 存储。
CSV、PARQUET 和 ORC 文件格式。
工作负荷管理
运行混合工作负荷会给繁忙的系统带来资源挑战。 成功的工作负载管理方案能够有效地管理资源,确保高效的资源利用,并将投资回报率 (ROI) 最大化。 工作负载分类、工作负荷重要性和工作负荷隔离可以更好地控制工作负荷利用系统资源的方式。
工作负荷管理指南介绍了用于分析工作负荷、管理和监视工作负荷重要性的技术,以及将资源类转换为工作负载组的步骤。 使用 Azure 门户和 DMV 上的 T-SQL 查询来监视工作负载,确保有效利用适用的资源。
后续步骤
若要了解 Netezza 迁移的 ETL 和加载,请参阅本系列中的下一篇文章:Netezza 迁移的数据迁移、ETL 和加载。