你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Service Fabric 运行状况监视简介
Azure Service Fabric 引入了一个运行状况模型,该模型提供丰富、灵活且可扩展的运行状况评估和报告。 使用该模型,可对群集及其中所运行服务的状态进行准实时监视。 可以轻松获取运行状况信息,并在潜在问题级联并造成大规模停机之前予以更正。 在典型模型中,服务基于其本地视图发送报告,并聚合信息,以提供整体的群集级别视图。
Service Fabric 组件使用这种提供丰富信息的运行状况模型报告其当前状态。 可以使用相同的机制报告多个应用程序的运行状况。 只要投入时间规划高质量的运行状况报告来捕获自定义条件,就能更轻松地检测并修复运行中应用程序的问题。
查看此页面以获取说明 Service Fabric 运行状况模型及其使用方式的培训视频:
注意
为应对被监视升级的需求,我们启动了运行状况子系统。 Service Fabric 提供受监视的应用程序和群集升级,可以确保完全可用性、永不停机,且几乎或完全不需要用户介入。 若要实现这些目标,升级将根据配置的升级策略检查运行状况。 仅当运行状况遵从所需阈值时,才可继续升级。 否则,升级会自动回滚或暂停,以便让管理员有机会修复问题。 若要了解有关应用程序升级的详细信息,请参阅此文。
运行状况存储
运行状况存储保留群集中关于实体的运行状况相关信息,以进行轻松的检索和评估。 它作为 Service Fabric 保留的有状态服务进行实现,以确保高度可用性和伸缩性。 运行状况存储是 fabric:/System 应用程序的一部分,并且只要群集已启动并正在运行,即可使用。
运行状况实体和层次结构
运行状况实体采用逻辑层次结构进行组织,该结构会捕获不同实体之间的交互和依赖项。 基于从 Service Fabric 组件收到的报告,运行状况存储自动生成实体和层次结构。
运行状况实体镜像 Service Fabric 实体。 (例如,运行状况应用程序实体匹配群集中部署的应用程序实例,运行状况节点实体匹配 Service Fabric 群集节点。)运行状况层次结构捕获系统实体的交互并且是进行高级运行状况评估的基础。 可以通过 Service Fabric 技术概述了解 Service Fabric 的关键概念。 有关应用程序的详细信息,请参阅 Service Fabric 应用程序模型。
利用运行状况实体和层次结构,可有效报告、调试和监视群集和应用程序。 运行状况模型为群集中许多移动片段的运行状况提供准确而精细的表示。
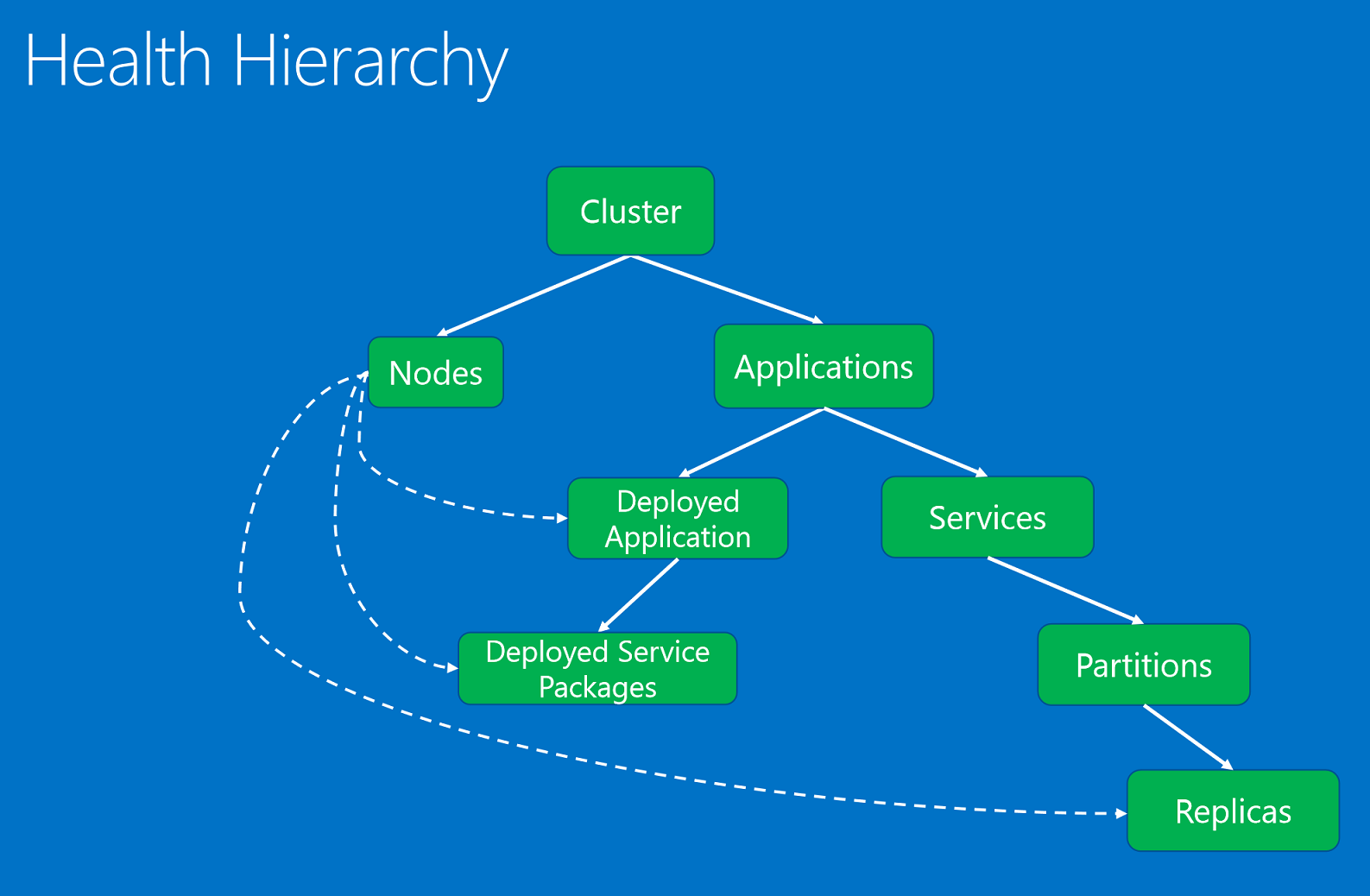 运行状况实体基于父-子关系在层次结构中进行组织。
运行状况实体基于父-子关系在层次结构中进行组织。
运行状况实体有:
- 群集。 表示 Service Fabric 群集的运行状况。 群集运行状况报告说明影响整个群集的条件。 这些条件会影响群集中的多个实体或群集本身。 根据条件,报告者不能将问题缩小到一个或多个不正常子级范围内。 示例包括因网络分区或通信问题导致的群集拆分的中枢部分。
- 节点。 表示 Service Fabric 节点的运行状况。 节点运行状况报告描述影响节点功能的条件。 它们通常会影响在其上运行的所有已部署的实体。 示例包括当节点磁盘空间不足(或其他计算机范围属性,例如内存、连接)以及节点已关闭时。 节点实体由节点名称(字符串)标识。
- 应用程序。 表示在群集中运行的应用程序实例的运行状况。 应用程序运行状况报告描述影响应用程序整体运行状况的条件。 不能将其缩小到单个子项(服务或已部署的应用程序)。 示例包括应用程序中不同服务之间的端到端交互。 应用程序实体由应用程序名称 (URI) 标识。
- 服务。 表示在群集中运行的服务的运行状况。 服务运行状况报告说明影响服务整体运行状况的条件。 报告者不能将问题范围缩小到不正常分区或副本。 示例包括导致全部分区问题的服务配置(如端口或外部文件共享)。 服务实体由服务名称 (URI) 标识。
- 分区。 表示服务分区的运行状况。 分区运行状况报告描述影响整个副本集的条件。 示例包括当副本数目低于目标计数以及分区发生仲裁丢失时的情况。 分区实体由分区 ID (GUID) 标识。
- 副本。 表示有状态服务副本或无状态服务实例的运行状况。 该副本是监视器和系统组件可针对应用程序进行报告的最小单位。 对于有状态服务,示例如下:主要副本不能将操作复制到辅助副本以及复制节奏缓慢。 还包含无状态实例,可在耗尽资源或存在连接问题时进行报告。 副本实体由分区 ID (GUID) 和副本或实例 ID(长型值)标识。
- DeployedApplication。 表示 在节点上运行的应用程序的运行状况。 已部署应用程序运行状况报告描述特定于节点上应用程序的条件,不能将其缩小到部署在相同节点上的服务包。 示例包括无法从该节点下载应用程序包以及在节点上设置应用程序安全主体时出现问题。 已部署应用程序由应用程序名称 (URI) 和节点名称(字符串)标识。
- DeployedServicePackage。 表示在群集中节点上运行的服务包的运行状况。 它描述特定于服务包的条件,该条件不会影响同一应用程序在同一节点上的其他服务包。 示例包括服务包中无法启动的代码包以及无法读取的配置包。 已部署服务包由应用程序名称 (URI)、节点名称(字符串)、服务清单名称(字符串)以及服务包激活 ID(字符串)标识。
利用运行状况模型的精度,可以轻松地检测和更正问题。 例如,如果服务没有响应,则可报告应用程序实例不正常。 该级别的报告不是理想之选,因为该问题可能不会影响该应用程序中的所有服务。 应对不正常的服务或者对特定子分区(如果有更多信息指向该分区)应用报告。 数据通过层次结构自动呈现,会在服务和应用程序级别显示不正常的分区。 这种聚合有助于更快找出问题的根本原因并解决问题。
运行状况层次结构由父-子关系组成。 群集由节点和应用程序组成。 应用程序包含服务和已部署的应用程序。 已部署的应用程序包含已部署的服务包。 服务具有分区,并且每个分区都有一个或多个副本。 节点和已部署实体之间具有特殊关系。 如果节点的机构系统组件(故障转移管理器服务)报告某一节点不正常,则它会影响已部署应用程序、服务包和在其上部署的副本。
运行状况层次结构表示基于最新运行状况报告的系统最新状态,该报告提供近实时信息。 内部和外部的监视器可以根据应用程序特定逻辑或自定义监视条件,对相同实体进行报告。 用户报告可与系统报告共存。
设计大型云服务时,请投入时间规划如何报告和响应运行状况。 有了这种预先投入准备,可以更轻松地调试、监视和操作该服务。
健康状况
Service Fabric 使用三种运行状况状态来说明实体是否正常:“正常”、“警告”和“错误”。 发送到运行状况存储的任何报告都必须指定其中一种状态。 运行状况评估结果是其中一种状态。
可能的运行状况如下:
- 正常。 实体正常。 没有针对它或其子项(如果适用)报告已知问题。
- 警告。 实体存在一些问题,但仍可正常运行。 例如,存在延迟,但尚未造成任何功能性问题。 在某些情况下,警告条件可能无需外部干预即可自行修复。 在这些情况下,运行状况报告可唤醒意识并提供对正在发生的事情的可见性。 在其他情况下,警告条件可能不经用户干预而恶化为严重问题。
- 错误。 实体不正常。 应采取行动修复实体的状态,因为它无法正常工作。
- 未知。 运行状况存储中不存在实体。 此结果可以从合并来自多个组件的结果的分布式查询中获取。 例如,获取节点列表查询发送到 FailoverManager、ClusterManager 和 HealthManager,获取应用程序列表查询发送到 ClusterManager 和 HealthManager 。 这些查询会合并来自多个系统组件的结果。 如果其他系统组件返回运行状况存储中不存在的实体,则合并结果包含未知运行状况。 实体不在存储中,因为运行状况报告尚未得到处理或该实体在删除后已被清理。
运行状况策略
运行状况存储应用运行状况策略,基于实体的报告和子项来确定该实体是否正常运行。
注意
可以在群集清单(适用于群集和节点运行状况评估)或应用程序清单(适用于应用程序评估及其任何子项)中指定运行状况策略。 运行状况评估请求也可以在自定义运行状况评估策略中传递,并且仅用于该评估。
默认情况下,Service Fabric 针对父-子层次结构关系应用严格的规则(所有项都必须正常运行)。 只要其中一个子项具有一个不正常事件,则将父项视为不正常。
群集运行状况策略
群集运行状况策略用于评估群集运行状况状态和节点运行状况状态。 可以在群集清单中对它进行定义。 如果该策略不存在,则会使用默认策略(不容许失败)。
群集运行状况策略包含:
ConsiderWarningAsError。 指定运行状况评估期间是否将警告性运行状况报告视为错误。 默认值:false。
MaxPercentUnhealthyApplications。 指定群集被视为“错误”之前可以容忍的不正常应用程序最大百分比。
MaxPercentUnhealthyNodes。 指定群集被视为“错误”之前可以容忍的不正常节点最大百分比。 在大型群集中,某些节点始终处于关闭或无法修复的状态,因此应配置此百分比以便容忍这种情况。
ApplicationTypeHealthPolicyMap。 群集运行状况评估期间,可使用应用程序类型运行状况策略,描述特殊应用程序类型。 默认情况下,所有应用程序都放入池中,并使用 MaxPercentUnhealthyApplications 进行评估。 如果某些应用程序类型应分别对待,可将其从全局池中提出。 根据与映射中应用程序类型名称关联的百分比来评估这些类型。 例如,群集中有数千个不同类型的应用程序,以及某个特殊应用程序类型的一些应用程序实例。 控制应用程序绝不应出错。 可以将全局 MaxPercentUnhealthyApplications 指定为 20%,以容许一些失败,但对于“ControlApplicationType”应用程序类型,请将 MaxPercentUnhealthyApplications 设为 0。 如此一来,如果众多应用程序中有一些运行不正常,但比例低于全局状况不良百分比,则将群集评估为“警告”。 “警告”健康状况不影响群集升级或“错误”健康状况将触发的其他监视。 但是,即使只有一个控制应用程序出错,也会造成群集运行不正常,根据升级配置,这会触发回滚或暂停群集升级。 对于映射中定义的应用程序类型,所有应用程序实例都从应用程序的全局池中提出。 使用映射中的特定 MaxPercentUnhealthyApplications,根据该应用程序类型的应用程序总数对其进行评估。 所有其他应用程序都保留在全局池中,使用 MaxPercentUnhealthyApplications 进行评估。
以下示例摘自某个群集清单。 若要定义应用程序类型映射中的条目,请在参数名称前面添加“ApplicationTypeMaxPercentUnhealthyApplications-”,后接应用程序类型名称。
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap。 节点类型运行状况策略映射可以在群集运行状况评估期间用于描述特殊的节点类型。 根据映射中的节点类型名称关联的百分比来评估节点类型。 设置此值不会影响用于MaxPercentUnhealthyNodes的节点的全局池。 例如,一个群集具有数百个不同类型的节点和一些托管重要工作的节点类型。 该类型的节点不应关闭。 可以将全局MaxPercentUnhealthyNodes指定为 20% 以容许所有节点的失败,但对于节点类型SpecialNodeType,请将MaxPercentUnhealthyNodes设为 0。 如此一来,如果其中许多节点运行不正常,但低于全局状况不正常的百分比,则将群集的运行状况评估为 Warning。 Warning 运行状况并不影响群集升级或由 Error 运行状况触发的其他监视。 但是,即使是一个处于 Error 运行状况的SpecialNodeType类型的节点也会使群集运行不正常,并根据具体升级配置触发回滚或暂停群集升级。 相反,如果SpecialNodeType类型的其中一个节点处于 error 状态,将全局MaxPercentUnhealthyNodes设置为 0 并将SpecialNodeType最大不正常运行节点的百分比设置为 100,则会让群集处于 error 状态,因为在这种情况下的全局限制更严格。以下示例摘自某个群集清单。 若要定义节点类型映射中的条目,请在参数名称前面添加“NodeTypeMaxPercentUnhealthyNodes-”,后接节点类型名称。
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
应用程序运行状况策略
应用程序运行状况策略说明如何对应用程序及其子项进行事件和子项状态聚合评估。 它可以在应用程序清单(应用程序包中的 ApplicationManifest.xml)中定义。 如果未指定任何策略,则当运行状况报告或子项处于“警告”或“错误”健康状况时,Service Fabric 会假设实体不正常运行。 可配置的策略有:
- ConsiderWarningAsError。 指定运行状况评估期间是否将警告性运行状况报告视为错误。 默认值:false。
- MaxPercentUnhealthyDeployedApplications。 指定将应用程序被视为“错误”之前可以容忍的不正常已部署应用程序的最大百分比。 此百分比的计算方式为:不正常的已部署应用程序数除以群集中目前已部署应用程序的节点数。 计算结果向上进一,以容忍少量节点上出现一次失败。 默认百分比:零。
- DefaultServiceTypeHealthPolicy。 指定默认服务类型运行状况策略,该策略会替换应用程序中所有服务类型的默认运行状况策略。
- ServiceTypeHealthPolicyMap。 针对每个服务类型提供服务运行状况策略的映射。 这些策略将取代每个指定服务类型的默认服务类型运行状况策略。 例如,如果应用程序包含无状态网关服务类型和有状态引擎服务类型,可为其评估分别配置运行状况策略。 按服务类型指定策略时,可以更精细地控制服务的运行状况。
服务类型运行状况策略
服务类型运行状况策略指定如何评估和聚合服务及服务的子项。 该策略包含:
- MaxPercentUnhealthyPartitionsPerService。 指定服务被视为不正常之前不正常分区的最大容忍百分比。 默认百分比:零。
- MaxPercentUnhealthyReplicasPerPartition。 指定分区被视为不正常之前不正常副本的最大容忍百分比。 默认百分比:零。
- MaxPercentUnhealthyServices。 指定应用程序被视为不正常之前不正常服务的最大容忍百分比。 默认百分比:零。
以下示例摘自某个应用程序清单:
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
运行状况评估
用户和自动化服务可以随时评估任何实体的运行状况。 若要评估实体运行状况,运行状况存储聚合实体上的所有运行状况报告,并评估其所有子项(如果适用)。 运行状况聚合算法使用运行状况策略,这类策略指定如何评估运行状况报告以及如何聚合子项健康状况(如果适用)。
运行状况报告聚合
一个实体可以拥有由不同报告器(系统组件或监视器)发送的针对不同属性的多个运行状况报告。 聚合使用关联的运行状况策略,尤其是应用程序或群集运行状况策略的 ConsiderWarningAsError 成员。 ConsiderWarningAsError 指定如何评估警告。
已聚合运行状况状态由实体上 最差 的运行状况报告触发。 如果至少有一个“错误”运行状况报告,则聚合的健康状况为“错误”。
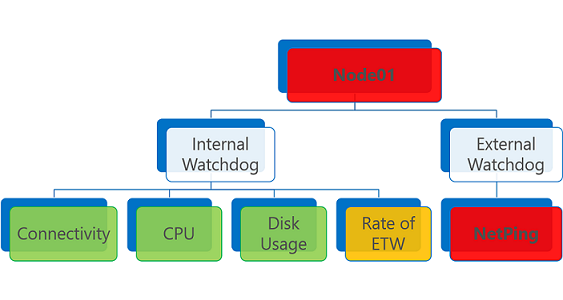
包含一个或多个“错误”运行状况报告的运行状况实体评估为“错误”。 已过期运行状况报告同样如此,无论其健康状况如何。
如果没有任何“错误”报告但有一个或多个“警告”,则聚合的健康状况为“警告”或“错误”,具体取决于 ConsiderWarningAsError 策略标志。
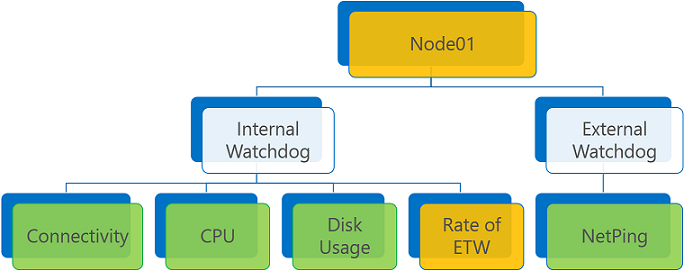
运行状况报告与“警告”报告聚合,ConsiderWarningAsError 设置为 false(默认值)。
子项运行状况聚合
实体的聚合健康状况反映子项健康状况(如果适用)。 用于聚合子项运行状况状态的算法基于实体类型使用适用的运行状况策略。
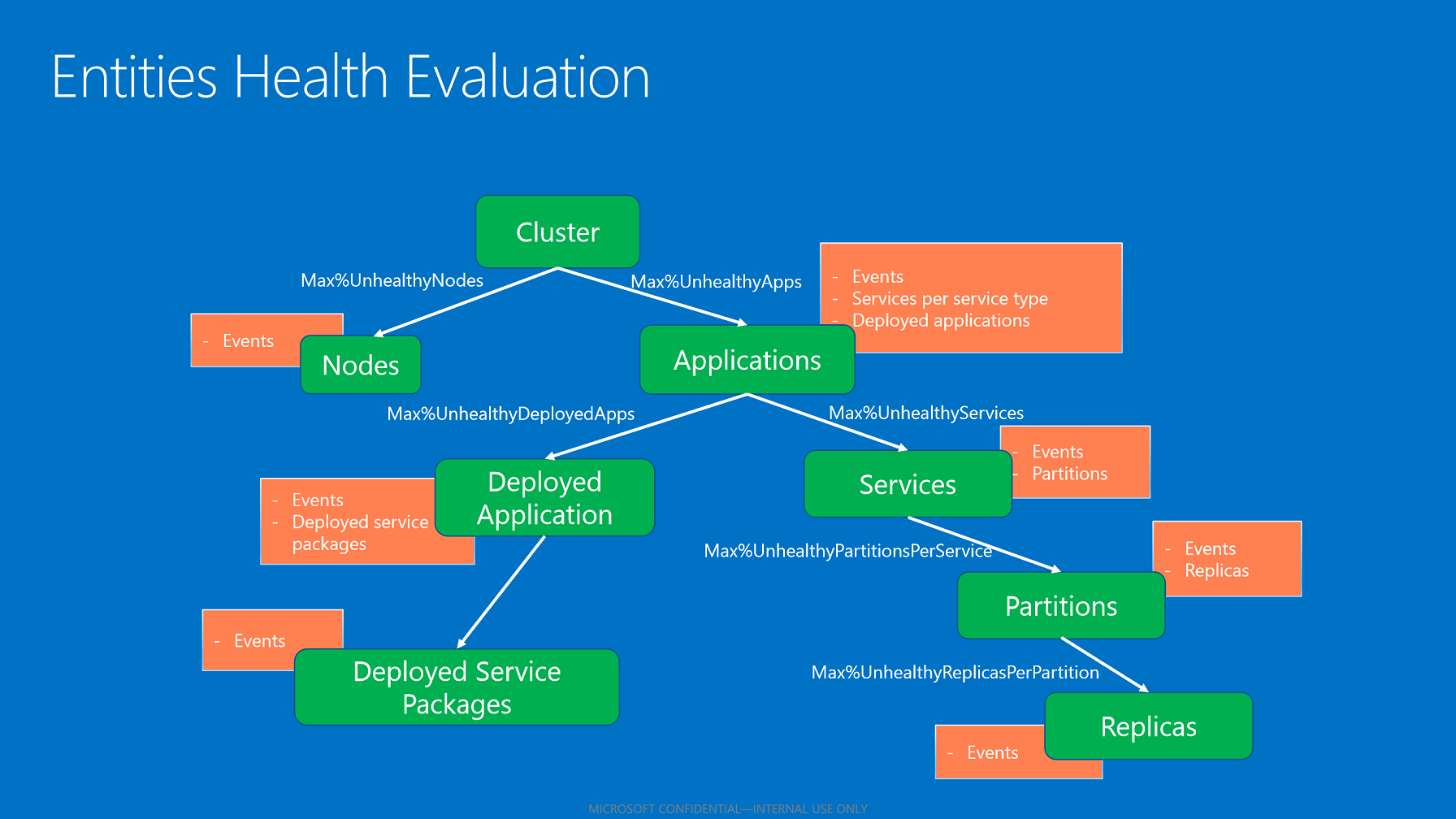
基于运行状况策略的子项聚合。
运行状况存储评估所有子项后,根据针对不正常子项配置的最大百分比来聚合其健康状况。 此百分比取自基于实体和子项类型的策略。
- 如果所有子项的状态都为“正常”,则子项的聚合健康状况为“正常”。
- 如果子项具有“正常”状态和“警告”状态,则子项的聚合健康状况为“警告”。
- 如果具有“错误”状态的子项不遵从不正常子项的最大允许百分比,已聚合父级运行状况状态则为“错误”。
- 如果具有“错误”状态的子项遵从不正常子项的最大允许百分比,已聚合父级运行状况状态则为“警告”。
运行状况报告
系统组件、系统结构应用程序和内部/外部监视器可以针对 Service Fabric 实体进行报告。 报告器基于它们正在监视的条件对监视的实体的运行状况进行 本地 判断。 它们无需查看任何全局状态或聚合数据。 理想行为是使用简单的报告器而不是复杂的有机体,因为后者需要分析许多内容才能推断出要发送的信息。
为将运行状况数据发送到运行状况存储,报告器需要标识受影响的实体并创建运行状况报告。 若要发送报告,请使用 FabricClient.HealthClient.ReportHealth API、Partition 或 CodePackageActivationContext 对象公开的报告运行状况 API、PowerShell cmdlet 或 REST。
运行状况报告
群集中每个实体的运行状况报告都包含以下信息:
SourceId。 唯一标识运行状况事件的报告器的字符串。
实体标识符。 标识对其应用了报告的实体。 它会因实体类型而异:
- Cluster。 无。
- 节点。 节点名称(字符串)。
- 应用程序。 应用程序名称 (URI)。 表示群集中部署的应用程序实例的名称。
- Service。 服务名称 (URI)。 表示群集中部署的服务实例的名称。
- Partition。 分区 ID (GUID)。 表示分区唯一标识符。
- Replica。 有状态服务副本 ID 或无状态服务实例 ID (INT64)。
- DeployedApplication。 应用程序名称 (URI) 和节点名称(字符串)。
- DeployedServicePackage。 应用程序名称 (URI)、节点名称(字符串)和服务清单名称(字符串)。
属性。 允许报告器针对实体的特定属性分类运行状况事件的字符串(不是固定的枚举)。 例如,报告者 A 可以报告 Node01“存储”属性的运行状况,报告者 B 可以报告 Node01“连接”属性的运行状况。 在运行状况存储中,这两个报告被视为 Node01 实体的单独运行状况事件。
说明。 报告器用于提供有关运行状况事件的详细信息的字符串。 SourceId、属性和 HealthState 应完整说明报告。 说明中添加了用户可读的报告相关信息。 该文本可让管理员和用户更容易了解运行状况报告。
HealthState。 说明报告的运行状况状态的枚举。 接受值的值有“正常”、“警告”和“错误”。
TimeToLive。 指示运行状况报告有效时长的时间跨度。 结合 RemoveWhenExpired时,它能够使运行状况存储知道如何评估过期的事件。 默认情况下,此值为无穷大,表示报告永远有效。
RemoveWhenExpired。 布尔值。 如果设置为 true,将从运行状况存储自动删除过期的运行状况报告,并且该报告不会影响实体运行状况评估。 仅当报告在指定的一段时间内有效,报告器不需要将其显式清除时使用。也用于从运行状况存储删除报告(例如,监视器被更改并停止发送包含以前的源和属性的报告)。 它可以发送具有短暂的 TimeToLive 和 RemoveWhenExpired 的报告,以清除运行状况存储中的所有以往状态。 如果该值设置为 false,则运行状况评估中会将过期的报告视为错误。 false 值向运行状况存储指示,源应该对此属性进行定期报告。 如果没有定期报告,则监视器必然存在问题。 通过将事件视为错误来捕获监视器运行状况。
SequenceNumber。 需要不断增加的正整数,它表示报告的顺序。 运行状况存储使用它来检测因网络延迟或其他问题而较晚收到的过时报告。 如果序列号小于或等于实体、源和属性最近应用的序列号,则会拒绝报告。 如果未指定,则会自动生成序列号。 只有在报告状态转换时,才需放入序列号。 在此情况下,源需要记住它所发送的报告,并保留信息以便在故障转移时进行恢复。
每个运行状况报告都需要四条信息(SourceId、ntity identifier、Property 和 HealthState)。 不允许 SourceId 字符串以前缀“System. ”开头,该字符串是为系统报告保留的。 对于相同实体,相同的源和属性只有一个报告。 如果为相同的源和属性生成多个报告,它们会在运行状况客户端(如果按批处理)或在运行状况存储端覆盖彼此。 这种替代按序列号进行:较新的报告(具有更高的序列号)替代较旧的报告。
运行状况事件
在内部,运行状况存储保留运行状况事件,其中包含报告的所有信息以及其他元数据。 元数据包括向运行状况客户端提供报告的时间,以及在服务器端修改该报告的时间。 运行状况事件通过运行状况查询返回。
添加的元数据包含:
- SourceUtcTimestamp。 报告提供给运行状况客户端的时间(协调世界时)。
- LastModifiedUtcTimestamp。 上次在服务器端修改报告的时间(协调世界时)。
- IsExpired。 用于指示运行状况存储执行查询时报告是否过期的标志。 仅当 RemoveWhenExpired 为 false 时,事件才可能过期。 否则,查询不会返回事件,并会将其从存储中删除。
- LastOkTransitionAt、LastWarningTransitionAt、LastErrorTransitionAt。 上一次“正常”/“警告”/“错误”转换的时间。 这些字段提供事件健康状况转换的历史记录。
状态转换字段可用于提供更智能的警报或“历史”运行状况事件信息。 适用的情景如下:
- 属性处于“警告”/“错误”状态超过 X 分钟时发出警报。 在一段时间内检查状态可避免对暂时性状态发起警报。 例如,当运行状况状态处于“警告”状态超过 5 分钟时发出警报,可转换为 (HealthState == Warning and Now - LastWarningTransitionTime > 5 minutes)。
- 仅针对过去 X 分钟内更改的状态发出警报。 如果在指定时间之前,报告已处于“错误”状态,则可以忽略它,因为之前已对其进行标志。
- 如果属性在“警告”和“错误”之间切换,则确定它处于不正常状态(即不为“正常”)的时长。 例如,当属性处于不正常状态超过 5 分钟时发出警报,可转换为 (HealthState != Ok and Now - LastOkTransitionTime > 5 minutes)。
示例:报告和评估应用程序运行状况
下列示例在源 MyWatchdog 中的应用程序 fabric:/WordCount 上通过 PowerShell 发送运行状况报告。 运行状况报告包含有关“错误”运行状况状态下的运行状况属性可用性的信息,含无限 TimeToLive。 然后,它会查询应用程序运行状况,此查询会在运行状况事件列表中返回聚合的健康状况错误和报告的运行状况事件。
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
运行状况模型用法
利用运行状况模型,云服务和基础 Service Fabric 平台可进行缩放,因为监视和运行状况判断分布在群集内的不同监视器中。 其他系统在群集级别具有单个集中式服务,该服务分析服务发出的所有 可能 有用的信息。 此方法会妨碍其可伸缩性。 此外,它不允许使用它们收集具体的信息来帮助识别问题和潜在问题,并尽可能接近根本原因。
运行状况模型大量用于监视和诊断、评估群集和应用程序运行状况以及监视的升级。 其他服务使用运行状况数据执行自动修复、生成群集运行状况历史记录,以及对某些条件发出警报。