你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
在 Azure AI 搜索中为了矢量搜索解决方案而对大型文档进行分块
将大型文档分区成较小的区块有助于保持嵌入模型的最大令牌输入限制。 例如,Azure OpenAI text-embedding-ada-002 模型输入文本的最大长度为 8,191 个标记。 鉴于常见 OpenAI 模型的每个标记约为 4 个文本字符,此最大限制相当于大约 6000 个文本单词。 如果使用这些模型来生成嵌入项,则输入文本保持在限制以内至关重要。 将内容分区成区块可确保数据可由嵌入模型处理,并且不会由于截断而丢失信息。
建议将集成矢量化用于内置数据分块和嵌入。 集成矢量化依赖于索引器、技能组、文本拆分技能和嵌入技能,例如 Azure OpenAI 嵌入 技能。 如果无法使用集成矢量化,请参阅本文来了解一些用于对内容进行分块的方法。
常用分块技术
仅当源文档对于模型施加的最大输入大小来说太大时,才需要进行分块。
下面是一些常用分块技术(从最广泛使用的方法开始):
固定大小的块:定义一个足以容纳语义上有意义的段落(例如 200 个单词)并允许一定程度的重叠(例如内容的 10-15%)的固定大小就可以生成良好的块,作为嵌入矢量生成器的输入。
基于内容的可变大小的区块:根据内容特征(例如句尾标点符号、行尾标记或使用自然语言处理 (NLP) 库中的功能)对数据进行分区。 Markdown 语言结构也可以用来拆分数据。
对上述技术之一进行自定义或迭代。 例如,在处理大型文档时,可以使用可变大小的区块,但也可以将文档标题附加到文档中间的区块中,以防止上下文丢失。
内容重叠注意事项
对数据进行分块时,在区块之间重叠少量文本有助于保留上下文。 建议从大约 10% 的重叠开始。 例如,如果固定区块大小为 256 个标记,则一开始可以使用 25 个标记的重叠进行测试。 实际重叠程度因数据类型和具体用例而异,但我们发现 10-15% 适用于许多场景。
数据分块的因素
涉及到数据分块时,请考虑以下因素:
文档的形状和密度。 如果需要完整的文本或段落,则那些保留句子结构的较大区块和可变区块可以产生更好的结果。
用户查询:较大区块和重叠策略有助于保留针对特定信息的查询的上下文和语义丰富性。
大型语言模型 (LLM) 有针对区块大小的性能准则。 你需要设置一个最适合正在使用的所有模型的区块大小。 例如,如果将模型用于摘要和嵌入项,请选择适用于两者的最佳区块大小。
分块如何适应工作流
如果你有大型文档,则必须将分块步骤插入索引和查询工作流,以分解大型文本。 使用集成矢量化时,会应用使用文本拆分技能的默认分块策略。 还可以使用自定义技能应用自定义分块策略。 一些提供分块功能的库包括:
大部分库都提供针对固定大小、可变大小或其组合的常见分块技术。 你还可以指定重叠,在每个区块中复制少量内容以保留上下文。
分块示例
以下示例展示了如何将分块策略应用于 NASA 的《地球之夜》电子书 PDF 文件:
文本拆分技能示例
通过文本拆分技能进行集成数据分块的功能已正式发布。
本部分介绍如何通过技能驱动方法和文本拆分技能参数使用内置数据分块。
azure-search-vector-samples 存储库中提供了此示例的示例笔记本。
设置 textSplitMode 以将内容分解为较小的区块:
pages(默认)。 区块由多个句子组成。sentences。 区块由单个句子组成。 构成一个“句子”的内容因语言而异。 在英语中,标准句子适用的结束标点符号为.或!。 语言由defaultLanguageCode参数控制。
该 pages 参数会添加额外的参数:
maximumPageLength定义了每个区块中的最大字符 1 或标记 2 数。 文本拆分器可避免拆分句子,因此实际字符计数取决于内容。pageOverlapLength定义下一页开头包含上一页末尾的字符数。 如果已设置,则必须小于最大页面长度的一半。maximumPagesToTake定义要从文档获取的页数/区块数。 默认值为 0,这意味着从文档获取所有页面或区块。
1 个字符与令牌的定义不一致。 LLM 测量出的令牌数可能与文本拆分技能测量出的字符大小不同。
2 标记分块在 2024-09-01-preview 中提供,并包括用于指定 tokenizer 的额外参数以及不应在分块期间拆分的任何标记。
下表显示了参数的选择如何影响《地球之夜》电子书中总区块计数:
textSplitMode |
maximumPageLength |
pageOverlapLength |
区块总数 |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
空值 | 空值 | 13361 |
使用 pages 的 textSplitMode 会导致大多数区块具有接近 maximumPageLength 的字符总数。 区块字符计数取决于句子边界位于区块内的位置差异。 区块令牌长度取决于区块内容差异。
以下直方图显示了 gpt-35-turbo 在《地球之夜》电子书中使用 pages 的 textSplitMode、2000 的 maximumPageLength 和 500 的 pageOverlapLength时,区块字符长度与区块令牌长度的分布比较情况:
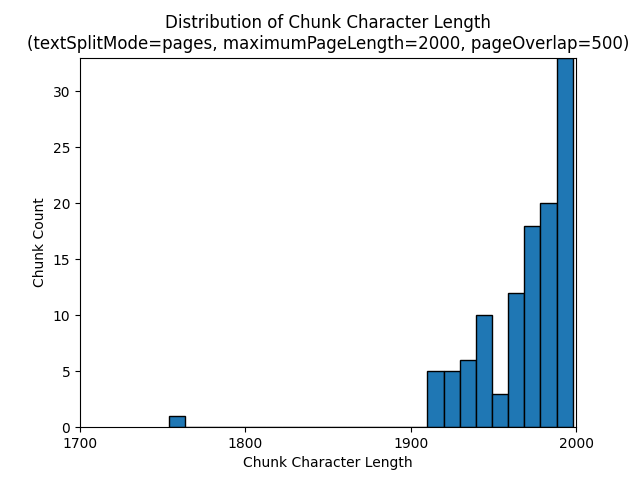
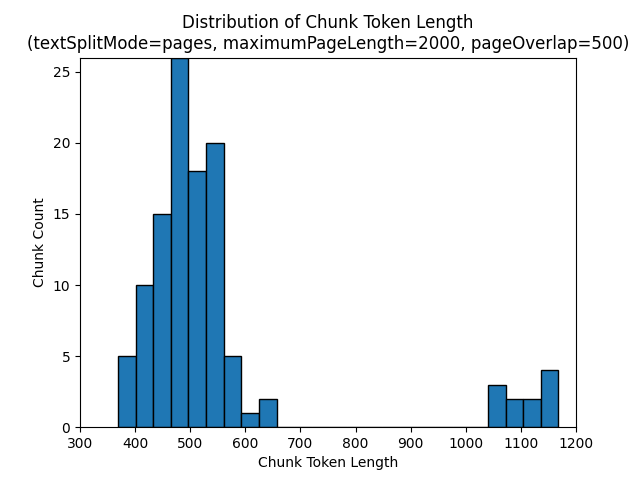
使用 sentences 的 textSplitMode 会导致大量包含单个句子的区块。 这些区块明显小于 pages 生成的区块,区块的令牌计数与字符计数更匹配。
以下直方图显示了 gpt-35-turbo 在《地球之夜》电子书中使用 sentences 的 textSplitMode时,区块字符长度与区块令牌长度的分布比较情况:
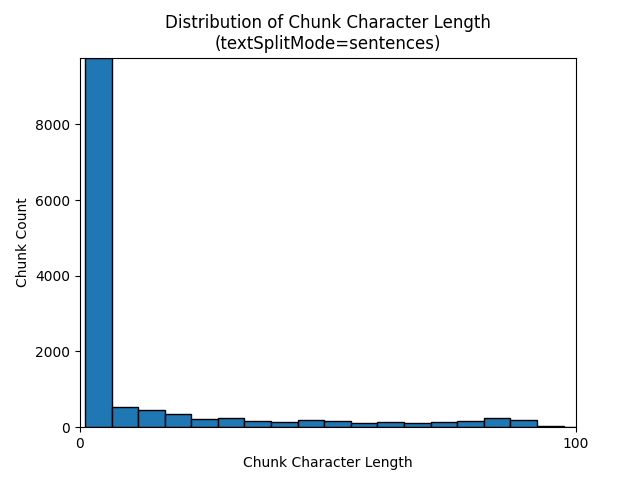
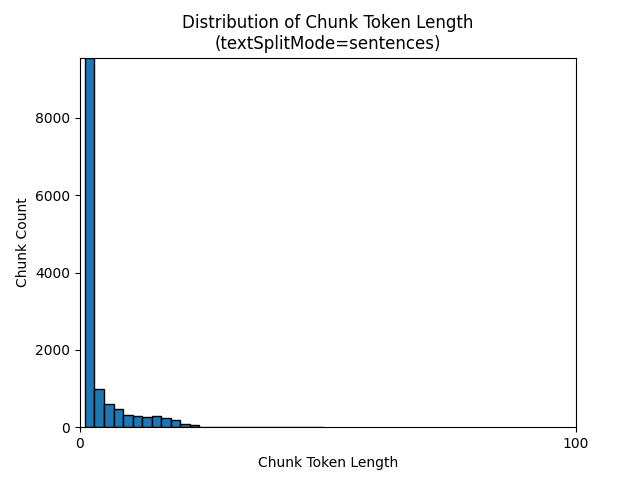
参数的最佳选择取决于区块的使用方式。 对于大多数应用程序,建议从以下默认参数开始:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
LangChain 数据分块示例
LangChain 提供文档加载器和文本拆分器。 此示例演示如何加载 PDF、获取令牌计数和设置文本拆分器。 获取令牌计数有助于就区块大小做出明智的决策。
azure-search-vector-samples 存储库中提供了此示例的示例笔记本。
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
输出指示 PDF 中有 200 个文档或页面。
若要获取这些页面的估计令牌计数,请使用 TikToken。
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
输出指示没有页具有零个标记,每个页面的平均令牌长度为 189 个令牌,任何页面的最大令牌计数为 1583。
了解平均令牌大小和最大令牌大小可让你深入了解如何设置区块大小。 尽管可以使用 2000 个字符与 500 个字符重叠的标准建议,但鉴于示例文档的令牌计数较低,在这种情况下这样做是有意义的。 事实上,设置太大的重叠值可能会导致完全不出现重叠。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
连续两个区块的输出显示第一个区块中的文本重叠到第二个区块上。 为提高可读性,输出内容略经编辑。
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
自定义技能
固定大小的分块和嵌入生成示例演示了如何使用 Azure OpenAI 嵌入模型进行分块和矢量嵌入生成。 此示例使用 Power Skills 存储库中的 Azure AI 搜索自定义技能来包装分块步骤。