你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
教程:云工作站上的模型开发
了解如何在 Azure 机器学习云工作站上使用笔记本开发训练脚本。 本教程涵盖入门所需的基础知识:
- 设置和配置云工作站。 云工作站由 Azure 机器学习计算实例提供支持,该实例预配置了环境以支持各种模型开发需求。
- 使用基于云的开发环境。
- 使用 MLflow 跟踪模型指标,所有都是在笔记本中完成的。
先决条件
要使用 Azure 机器学习,你需要一个工作区。 如果没有工作区,请完成创建开始使用所需的资源以创建工作区并详细了解如何使用它。
重要
如果 Azure 机器学习工作区配置了托管虚拟网络,则可能需要添加出站规则以允许访问公共 Python 包存储库。 有关详细信息,请参阅应用场景:访问公共机器学习包。
开始学习计算
可以通过工作区中的“计算”部分创建计算资源。 计算实例是一个由 Azure 机器学习完全托管的基于云的工作站。 本教程系列使用计算实例。 还可以使用它来运行自己的代码,以及开发和测试模型。
- 登录到 Azure 机器学习工作室。
- 选择你的工作区(如果它尚未打开)。
- 在左侧导航栏中,选择“计算”。
- 如果没有计算实例,屏幕中间会显示“新建”。 选择“新建”并填写表单。 可以使用所有默认值。
- 如果有计算实例,请从列表中选择它。 如果已停止,请选择“启动”。
打开 Visual Studio Code (VS Code)
拥有正在运行的计算实例后,便可以通过各种方式访问它。 本教程演示如何使用 VS Code 中的计算实例。 VS Code 提供了一个完整的集成开发环境 (IDE),可以使用 Azure 机器学习资源的强大功能。
在计算实例列表中,为要使用的计算实例选择“VS Code(网页版)”或“VS Code(桌面版)”链接。 如果选择“VS Code(桌面版)”,则可能会看到一个弹出窗口,询问是否要打开该应用程序。

此 VS Code 实例附加到计算实例和工作区文件系统。 即使在桌面上打开它,你看到的文件也是工作区中的文件。
设置用于原型制作的新环境(可选)
为使脚本运行,需要在配置了代码所需的依赖项和库的环境中工作。 本部分可帮助你创建适合代码的环境。 若要创建笔记本连接到的新 Jupyter 内核,请使用定义依赖项的 YAML 文件。
上传文件。
上传的文件存储在 Azure 文件共享中,这些文件将装载到每个计算实例并在工作区中共享。
使用右上角的下载原始文件按钮,将此 conda 环境文件 workstation_env.yml 下载到计算机。
将文件从计算机拖到 VS Code 窗口。 文件将上传到工作区。
将文件移到用户名文件夹下。
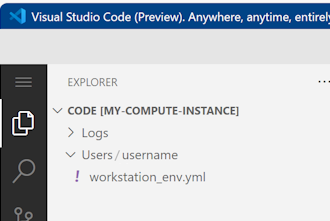
选择此文件以进行预览,并查看它指定的依赖项。 你将看到如下所示的内容:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlib创建内核。
现在,使用终端基于 workstation_env.yml 文件创建新的 Jupyter 内核。
在顶部菜单栏上,选择“终端”>“新终端”。
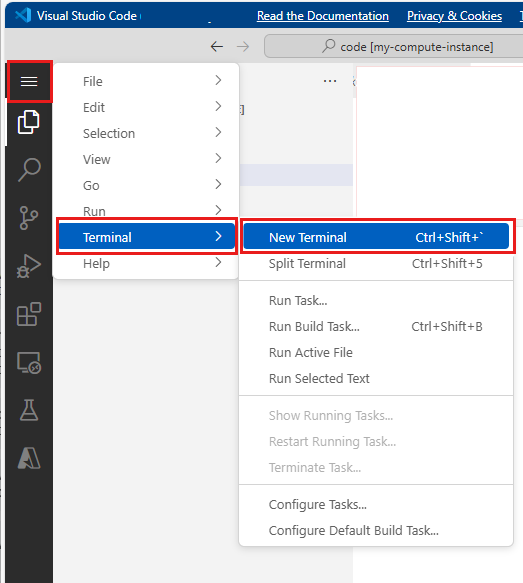
查看当前的 conda 环境。 活动环境标有 *。
conda env listcd到你上传 workstation_env.yml 文件的文件夹。 例如,如果你将它上传到了用户文件夹:cd Users/myusername确保 workstation_env.yml 在此文件夹中。
ls根据提供的 conda 文件创建环境。 构建此环境需要几分钟时间。
conda env create -f workstation_env.yml激活新环境。
conda activate workstation_env注意
如果看到 CommandNotFoundError,请按照说明运行
conda init bash,关闭终端并打开一个新终端。 然后重试conda activate workstation_env命令。验证正确的环境是否处于活动状态,再次查找标有 * 的环境。
conda env list基于活动环境创建新的 Jupyter 内核。
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"关闭终端窗口。
你现在有了一个新内核。 接下来,你将打开一个笔记本并使用此内核。
创建笔记本
- 在菜单栏中选择“文件”>“新建文件”。
- 将新文件命名为 develop-tutorial.ipynb(或输入首选名称)。 请确保使用 .ipynb 扩展。
设置内核
- 在右上角,选择“选择内核”。
- 选择“Azure ML 计算实例 (computeinstance-name)”。
- 选择创建的内核,即“教程 Workstation Env”。 如果尚未看到它,请选择右上角的“刷新”工具。
开发训练脚本
在本部分中,你将使用 UCI 数据集中准备好的测试和训练数据集开发一个 Python 训练脚本,用于预测信用卡默认付款。
此代码使用 sklearn 进行训练,使用 MLflow 来记录指标。
从可导入将在训练脚本中使用的包和库的代码开始。
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split接下来,加载并处理此试验的数据。 在本教程中,将从 Internet 上的一个文件读取数据。
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )准备好数据进行训练:
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.values添加代码以使用
MLflow开始自动记录,以便可以跟踪指标和结果。MLflow具有模型开发的迭代性质,可帮助你记录模型参数和结果。 请回顾这些运行,比较并了解模型的性能。 这些日志还为你准备好从 Azure 机器学习中工作流的开发阶段转到训练阶段提供上下文。# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()训练模型。
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()注意
可以忽略 mlflow 警告。 你仍将获得需要跟踪的所有结果。
迭代
现在你已经有了模型结果,可能需要更改某些内容,然后重试。 例如,请尝试其他分类器技术:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()注意
可以忽略 mlflow 警告。 你仍将获得需要跟踪的所有结果。
检查结果
现在,你已尝试两个不同的模型,请使用 MLFfow 跟踪的结果来确定哪个模型更好。 可以引用准确性等指标,或者引用对方案最重要的其他指标。 可以通过查看 MLflow 创建的作业来更详细地了解这些结果。
返回到 Azure 机器学习工作室中的工作区。
在左侧导航栏中,选择“作业”。
选择“在云上开发教程”的链接。
显示了两个不同的作业,每个已尝试的模型对应一个。 这些名称是自动生成的。 将鼠标悬停在某个名称上时,如果要重命名该名称,请使用名称旁边的铅笔工具。
选择第一个作业的链接。 名称显示在顶部。 还可以在此处使用铅笔工具重命名它。
该页显示作业的详细信息,例如属性、输出、标记和参数。 在“标记”下,你将看到 estimator_name,其描述模型的类型。
选择“指标”选项卡以查看
MLflow记录的指标。 (预期结果会有所不同,因为训练集不同。)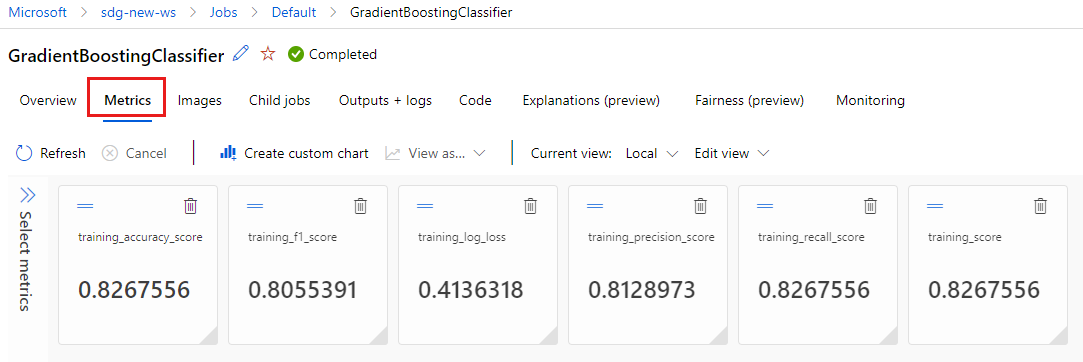
选择“图像”选项卡以查看
MLflow生成的图像。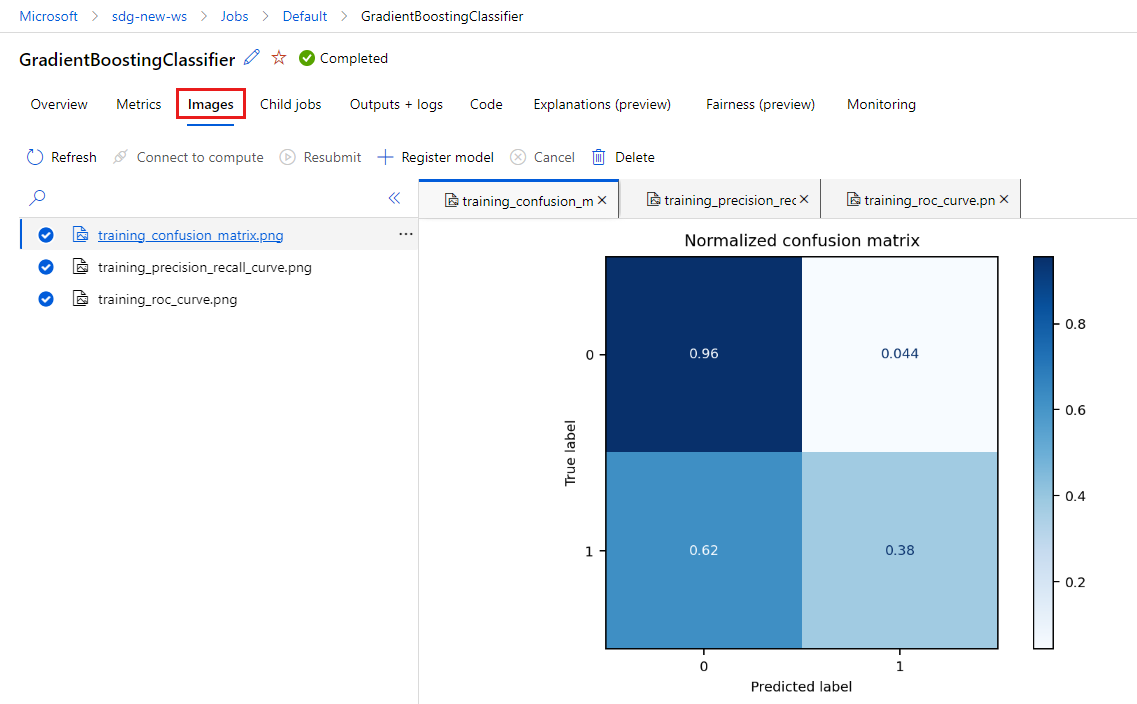
返回并查看其他模型的指标和图像。
创建 Python 脚本
现在,从笔记本创建 Python 脚本来用于模型训练。
在 VS Code 窗口中,右键单击笔记本文件名,然后选择“将笔记本导入脚本”。
使用菜单“文件”>“保存”以保存此新脚本文件。 将它命名为 train.py。
浏览此文件并删除训练脚本中不需要的代码。 例如,保留要使用的模型的代码,并删除不需要的模型的代码。
- 确保保留启动自动记录的代码 (
mlflow.sklearn.autolog())。 - 当以交互方式运行 Python 脚本时(如此处所示),可以保留定义试验名称的行 (
mlflow.set_experiment("Develop on cloud tutorial"))。 或者甚至为其指定一个不同名称,以将其视为“作业”部分中的不同条目。 但是,在为训练作业准备脚本时,该行不起作用,应省略;作业定义包括试验名称。 - 训练单个模型时,开始和结束运行的行(
mlflow.start_run()和mlflow.end_run())也没有必要(它们不起作用),但可以根据需要保留。
- 确保保留启动自动记录的代码 (
完成编辑后,请保存文件。
现在,你有一个 Python 脚本用于训练首选模型。
运行 Python 脚本
现在,你将在计算实例(即 Azure 机器学习开发环境)上运行此代码。 “教程:训练模型”介绍如何在更强大的计算资源上以更可缩放的方式运行训练脚本。
选择在本教程前面创建的环境作为 Python 版本 (workstations_env)。 笔记本右下角将显示环境名称。 选择它,然后选择屏幕中间的环境。
现在运行 Python 脚本。 使用右上角的“运行 Python 文件”工具。
注意
可以忽略 mlflow 警告。 你仍将从自动记录中获取所有指标和图像。
检查脚本结果
返回到 Azure 机器学习工作室工作区中的“作业”,查看训练脚本的结果。 请记住,每次拆分时训练数据都会更改,因此各运行的结果也不同。
清理资源
如果打算继续学习其他教程,请跳到后续步骤。
停止计算实例
如果不打算现在使用它,请停止计算实例:
- 在工作室的左侧导航区域中,选择“计算”。
- 在顶部选项卡中,选择“计算实例”
- 在列表中选择该计算实例。
- 在顶部工具栏中,选择“停止”。
删除所有资源
重要
已创建的资源可用作其他 Azure 机器学习教程和操作方法文章的先决条件。
如果你不打算使用已创建的任何资源,请删除它们,以免产生任何费用:
在 Azure 门户的搜索框中输入“资源组”,然后从结果中选择它。
从列表中选择你创建的资源组。
在“概述”页面上,选择“删除资源组”。
输入资源组名称。 然后选择“删除”。
后续步骤
了解有关以下方面的详细信息:
本教程介绍了在代码所在的计算机上创建模型、原型制作的早期步骤。 对于生产训练,了解如何在更强大的远程计算资源上使用该训练脚本: