你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
教程:在 Azure 机器学习中训练模型
适用于: Python SDK azure-ai-ml v2(当前版本)
Python SDK azure-ai-ml v2(当前版本)
了解数据科学家如何使用 Azure 机器学习来训练模型。 在此示例中,你使用信用卡数据集来了解如何使用 Azure 机器学习解决分类问题。 目标是预测客户是否有信用卡付款违约的高可能性。 训练脚本负责处理数据准备。 然后,该脚本会训练并注册模型。
本教程将指导你完成提交基于云的训练作业(命令作业)的步骤。
- 获得到 Azure 机器学习工作区的句柄
- 创建计算资源和作业环境
- 创建训练脚本
- 创建并运行命令作业以在计算资源上运行训练脚本
- 查看训练脚本的输出
- 将新训练的模型部署为终结点
- 调用 Azure 机器学习终结点进行推理
若要详细了解如何将数据加载到 Azure,请参阅教程:在 Azure 机器学习中上传、访问和探索数据。
此视频演示如何开始使用 Azure 机器学习工作室,以便你可以按照本教程中的步骤进行操作。 该视频演示如何创建笔记本、创建计算实例和克隆笔记本。 以下各部分中也介绍了这些步骤。
先决条件
-
要使用 Azure 机器学习,你需要一个工作区。 如果没有工作区,请完成创建开始使用所需的资源以创建工作区并详细了解如何使用它。
重要
如果 Azure 机器学习工作区配置了托管虚拟网络,则可能需要添加出站规则以允许访问公共 Python 包存储库。 有关详细信息,请参阅场景:访问公共机器学习包。
-
登录工作室,选择你的工作区(如果尚未打开)。
-
在工作区中打开或创建一个笔记本:
设置内核并在 Visual Studio Code (VS Code) 中打开
在打开的笔记本上方的顶部栏中,创建一个计算实例(如果还没有计算实例)。

如果计算实例已停止,请选择“启动计算”,并等待它运行。

等待计算实例运行。 然后确保右上角的内核为
Python 3.10 - SDK v2。 如果不是,请使用下拉列表选择该内核。
如果没有看到该内核,请验证计算实例是否正在运行。 如果它正在运行,请选择笔记本右上角的“刷新”按钮。
如果看到一个横幅,提示你需要进行身份验证,请选择“身份验证”。
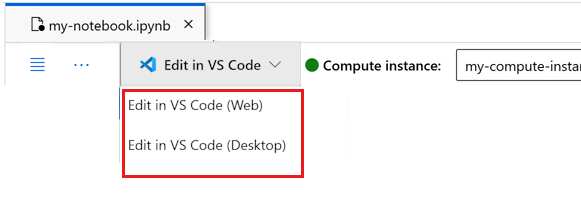
可在此处运行笔记本,或者在 VS Code 中将其打开,以获得具有 Azure 机器学习资源强大功能的完整集成开发环境 (IDE)。 选择“在 VS Code 中打开”,然后选择 Web 或桌面选项。 以这种方式启动时,VS Code 将附加到计算实例、内核和工作区文件系统。




重要
本教程的其余部分包含教程笔记本的单元格。 将其复制并粘贴到新笔记本中,或者立即切换到该笔记本(如果已克隆该笔记本)。
使用命令作业在 Azure 机器学习中训练模型
若要训练模型,需要提交作业。 Azure 机器学习提供了多种不同类型的作业来训练模型。 用户可以根据模型的复杂性、数据大小和训练速度要求来选择其训练方法。 本教程介绍了如何提交命令作业以运行训练脚本。
命令作业是一个函数,可用于提交自定义训练脚本来训练模型。 此作业也可以定义为自定义训练作业。 Azure 机器学习中的命令作业是在指定环境中运行脚本或命令的一种作业。 可以使用命令作业来训练模型、处理数据或要在云中执行的任何其他自定义代码。
本教程重点介绍了如何使用命令作业创建用于训练模型的自定义训练作业。 任何自定义训练作业都需要以下项:
- 环境
- 数据
- 命令作业
- 训练脚本
本教程为示例提供了这些项:创建一个分类器来预测具有信用卡付款违约高可能性的客户。
创建工作区句柄
在深入了解代码之前,需要一种方法来引用工作区。 为工作区句柄创建 ml_client。 然后,使用 ml_client 来管理资源和作业。
在下一个单元格中,输入你的订阅 ID、资源组名称和工作区名称。 若要查找这些值:
- 在右上方的 Azure 机器学习工作室工具栏中,选择你的工作区名称。
- 将工作区、资源组和订阅 ID 的值复制到代码中。 需要复制一个值,关闭区域并粘贴,然后返回继续复制下一个值。
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
注意
创建 MLClient 不会连接到工作区。 客户端初始化不会立即进行, 它会等待第一次需要调用时才进行(这将在下一个代码单元格中发生)。
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
创建作业环境
若要在计算资源上运行 Azure 机器学习作业,需要一个环境。 环境将列出你希望在进行训练的计算资源上安装的软件运行时和库。 它类似于本地计算机上的 Python 环境。 有关详细信息,请参阅什么是 Azure 机器学习环境?
Azure 机器学习提供了许多特选或现成的环境,这些环境对于常见训练和推理方案非常有用。
在此示例中,你使用 conda yaml 文件为作业创建一个自定义 conda 环境。
首先,创建一个目录来存储文件。
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
下一个单元格使用 IPython magic 将 conda 文件写入创建的目录中。
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=1.0.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- mlflow==2.8.0
- mlflow-skinny==2.8.0
- azureml-mlflow==1.51.0
- psutil>=5.8,<5.9
- tqdm>=4.59,<4.60
- ipykernel~=6.0
- matplotlib
该规范包含一些在作业中使用的常用包,例如 numpy 和 pip。
引用此 yaml 文件以在工作区中创建并注册此自定义环境:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
custom_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults job",
tags={"scikit-learn": "1.0.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
custom_job_env = ml_client.environments.create_or_update(custom_job_env)
print(
f"Environment with name {custom_job_env.name} is registered to workspace, the environment version is {custom_job_env.version}"
)
使用命令函数配置训练作业
你需要创建一个 Azure 机器学习命令作业来训练用于信用违约预测的模型。 命令作业在指定计算资源上的指定环境中运行训练脚本。 你已创建环境和计算群集。 下一步是创建训练脚本。 在此情况下,你将训练数据集以使用 GradientBoostingClassifier 模型生成分类器。
训练脚本将处理数据准备、训练和注册已训练模型。 方法 train_test_split 将数据集拆分为测试和训练数据。 在本教程中,你将创建 Python 训练脚本。
可以从 CLI、Python SDK 或工作室界面运行命令作业。 在本教程中,使用 Azure 机器学习 Python SDK v2 创建并运行命令作业。
创建训练脚本
首先,创建训练脚本:main.py Python 文件。 首先为脚本创建源文件夹:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
此脚本将预处理数据,将其拆分为测试和训练数据。 然后,该脚本使用数据来训练基于树的模型并返回输出模型。
MLFlow 用于在此作业过程中记录参数和指标。 MLFlow 包支持跟踪 Azure 训练的每个模型的指标和结果。 使用 MLFlow 为数据获取最佳模型。 然后在 Azure 工作室中查看模型的指标。 有关详细信息,请参阅 MLflow 和 Azure 机器学习。
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
#Split train and test datasets
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
在此脚本中,训练模型后,模型文件将会保存并注册到工作区。 通过模型注册,可在 Azure 云的工作区中存储模型并控制模型版本。 注册模型后,可以在 Azure 工作室中名为“模型注册表”的一个位置找到所有其他已注册的模型。 模型注册表可帮助你组织和跟踪已训练的模型。
配置命令
现在已有一个可执行分类任务的脚本,你将使用可以运行命令行操作的常规用途命令。 此命令行操作可以直接调用系统命令或运行脚本。
创建输入变量来指定输入数据、拆分比、学习速率和注册的模型名称。 命令脚本:
- 使用之前创建的环境。 使用
@latest表示法在运行命令时指示环境的最新版本。 - 配置命令行操作本身,在这种情况下为
python main.py。 可通过使用${{ ... }}表示法访问命令中的输入和输出。 - 由于未指定计算资源,因此该脚本将在自动创建的无服务器计算群集上运行。
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="aml-scikit-learn@latest",
display_name="credit_default_prediction",
)
提交作业
提交要在 Azure 机器学习工作室中运行的作业。 这次在 ml_client 上使用 create_or_update。 ml_client 是一个客户端类,支持使用 Python 连接到 Azure 订阅并与 Azure 机器学习服务交互。 ml_client 支持使用 Python 提交作业。
ml_client.create_or_update(job)
查看作业输出并等待作业完成
要在 Azure 机器学习工作室中查看作业,请选择上一个单元格的输出中的链接。 此作业的输出在 Azure 机器学习工作室中如下所示。 浏览选项卡以获取各种详细信息,例如指标、输出等。完成作业后,它会在工作区中注册一个模型作为训练结果。
重要
等待作业的状态变成“已完成”,然后再返回到此笔记本继续。 该作业需要 2 到 3 分钟才能运行。 如果计算群集已缩减到零个节点,并且自定义环境仍在生成,则可能需要更长时间(最多 10 分钟)。
运行单元格时,笔记本输出会显示指向机器学习工作室上作业详细信息页的链接。 或者,还可以在左侧导航菜单中选择“作业”。
作业是指定脚本或代码段中多个运行的分组。 运行的信息存储在该作业下。 详细信息页概述了作业、运行所花费的时间、创建时间和其他信息。 该页还包含选项卡,用于查看有关作业的其他信息,例如指标、输出 + 日志和代码。 以下是作业详细信息页中的可用选项卡:
- 概述:有关作业的基本信息,包括其状态、开始时间和结束时间,以及运行的作业类型
- 输入:用作作业输入的数据和代码。 本部分可以包括数据集、脚本、环境配置和训练期间使用的其他资源。
- 输出 + 日志:作业运行时生成的日志。 如果训练脚本或模型创建出现问题,此选项卡可帮助进行故障排除。
- 指标:模型的关键性能指标,例如训练分数、f1 分数和精度分数。
清理资源
停止计算实例
如果不打算现在使用它,请停止计算实例:
- 在工作室的左侧导航区域中,选择“计算”。
- 在顶部选项卡中,选择“计算实例”。
- 在列表中选择该计算实例。
- 在顶部工具栏中,选择“停止”。
删除所有资源
重要
已创建的资源可用作其他 Azure 机器学习教程和操作方法文章的先决条件。
如果你不打算使用已创建的任何资源,请删除它们,以免产生任何费用:
在 Azure 门户的搜索框中输入“资源组”,然后从结果中选择它。
从列表中选择你创建的资源组。
在“概述”页面上,选择“删除资源组”。
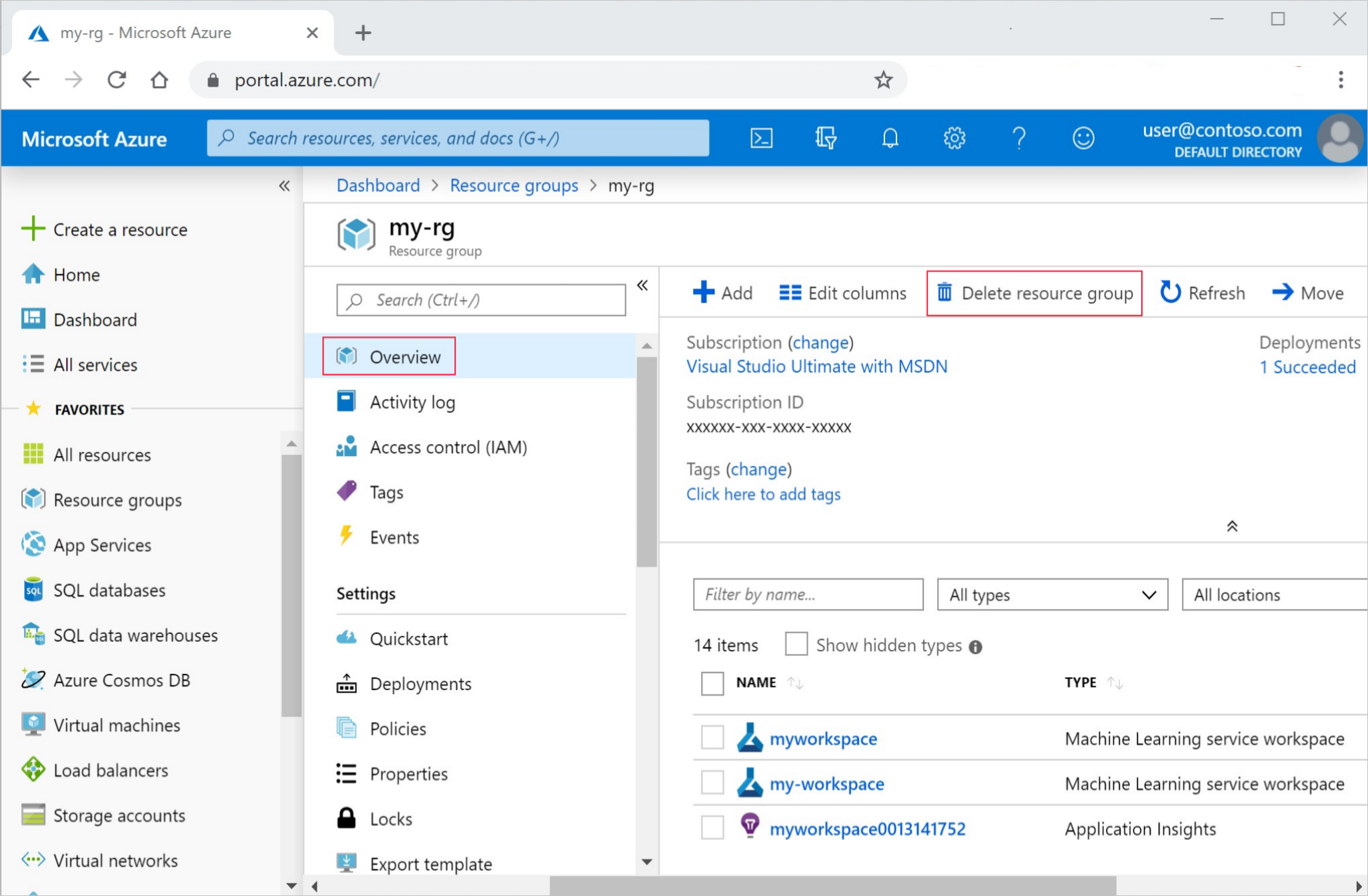
输入资源组名称。 然后选择“删除”。
相关内容
了解如何部署模型:
部署模型。
本教程使用了联机数据文件。 若要详细了解访问数据的其他方法,请参阅教程:在 Azure 机器学习中上传、访问和探索数据。
自动化 ML 是一种补充工具,用于减少数据科学家查找最适合其数据的模型所花费的时间。 有关详细信息,请参阅什么是自动化机器学习。
如果需要更多类似于本教程的示例,请参阅从示例笔记本中学习。 GitHub 示例页提供了这些示例。 这些示例包括可以运行代码并学习训练模型的完整 Python 笔记本。 可以从示例中修改和运行现有脚本,其中包含分类、自然语言处理和异常情况检测等方案。