你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
将机器学习模型部署到 Azure
适用于: Azure CLI ml 扩展 v1Python SDK azureml v1
Azure CLI ml 扩展 v1Python SDK azureml v1
了解如何将机器学习或深度学习模型作为 Web 服务部署在 Azure 云中。
注意
Azure 机器学习终结点 (v2) 提供了经过改进的简化部署体验。 终结点同时支持实时和批量推理场景。 终结点提供了一个统一的接口,以用于跨计算类型调用和管理模型部署。 请参阅什么是 Azure 机器学习终结点?。
用于部署模型的工作流
无论你在何处部署模型,工作流都是类似的:
- 注册模型。
- 准备入口脚本。
- 准备推理配置。
- 在本地部署模型以确保一切正常运作。
- 选择计算目标。
- 将模型部署到云端。
- 测试生成的 Web 服务。
若要详细了解机器学习部署工作流中涉及的概念,请参阅使用 Azure 机器学习来管理、部署和监视模型。
先决条件
重要
本文中的一些 Azure CLI 命令使用适用于 Azure 机器学习的 azure-cli-ml 或 v1 扩展。 对 v1 扩展的支持将于 2025 年 9 月 30 日结束。 在该日期之前,你将能够安装和使用 v1 扩展。
建议在 2025 年 9 月 30 日之前转换为 ml 或 v2 扩展。 有关 v2 扩展的详细信息,请参阅 Azure ML CLI 扩展和 Python SDK v2。
连接到工作区
若要查看你有权访问的工作区,请使用以下命令:
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
注册模型
已部署的机器学习服务会遇到的典型情况是需要以下组件:
- 表示要部署的特定模型的资源(例如:pytorch 模型文件)。
- 将在服务中运行的代码(可针对给定输入执行模型)。
Azure 机器学习允许你将部署分成两个单独的部分以便保留相同代码,但只限更新模型。 我们将上传模型与代码“分开”的这种机制定义为“注册模型”。
当你注册模型时,我们会将该模型上传到云端(位于工作区的默认存储帐户中),然后将其装载到运行 Web 服务的相同计算机中。
以下示例演示如何注册模型。
重要
应仅使用自己创建的或从受信任源获得的模型。 应将序列化模型视为代码,因为在许多常用格式中都发现了安全漏洞。 此外,可能有人恶意将模型训练为提供有偏差或不准确的输出。
以下命令可下载模型,然后将它注册到 Azure 机器学习工作区:
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
将 -p 设为要注册的文件夹或文件的路径。
有关 az ml model register 的详细信息,请查看参考文档。
通过 Azure 机器学习训练作业注册一个模型
如果需要注册之前通过 Azure 机器学习训练作业创建的模型,可以指定试验、运行和模型路径:
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
--asset-path 参数表示模型的云位置。 本示例使用的是单个文件的路径。 若要在模型注册中包含多个文件,请将 --asset-path 设置为包含文件的文件夹的路径。
有关 az ml model register 的详细信息,请查看参考文档。
注意
还可以通过工作区 UI 门户从本地文件注册模型。
目前,可通过两个选项在 UI 中上传本地模型文件:
- “从本地文件”,用于注册 v2 模型。
- “从本地文件(基于框架)”,用于注册 v1 模型。
请注意,只有通过“从本地文件(基于框架)”入口(称为 v1 模型)注册的模型才能通过 SDKv1/CLIv1 部署为 Web 服务。
定义虚拟入口脚本
入口脚本接收提交到已部署 Web 服务的数据,并将此数据传递给模型。 然后,其将模型的响应返回给客户端。 该脚本特定于你的模型。 入口脚本必须能够理解模型期望和返回的数据。
需要在入口脚本中完成以下两项操作:
- 加载模型(使用名为
init()的函数) - 对输入数据运行模型(使用名为
run()的函数)
对于初始部署,请使用虚拟入口脚本来打印接收到的数据。
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
将此文件以 echo_score.py 形式保存到名为 source_dir 的目录中。 此虚拟脚本返回发送给它的数据,因此不使用模型。 但是,它可用于测试评分脚本是否正在运行。
定义推理配置
推理配置描述了初始化 Web 服务时要使用的 Docker 容器和文件。 在部署 Web 服务时,源目录(包括子目录)中的所有文件都将经过压缩并上传到云端。
下方的推理配置指定机器学习部署将使用 ./source_dir 目录中的 echo_score.py 文件来处理传入的请求,并将搭配使用 Docker 映像与 project_environment 环境中指定的 Python 包。
创建项目环境时,可以使用任何 Azure 机器学习的推理特选环境作为基础 Docker 映像。 我们会在顶层安装所需的依赖项,并将生成的 Docker 映像存储在与工作区关联的存储库中。
注意
Azure 机器学习推理源目录上传不遵循 .gitignore 或 .amlignore
最小推理配置可以编写为:
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
使用 dummyinferenceconfig.json 名称保存此文件。
有关推理配置的更详细讨论,请参阅此文。
定义部署配置
部署配置指定运行 webservice 所需的内存和核心数。 它还提供基础 webservice 的配置详细信息。 例如,可以使用部署配置来指定服务需要 2GB 内存、2 个 CPU 核心和 1 个 GPU 核心,并且想要启用自动缩放。
适用于部署配置的选项因所选计算目标而异。 在本地部署中,只能指定将在哪个端口上提供 Web 服务。
deploymentconfig.json 文档中的条目对应于 LocalWebservice.deploy_configuration 的参数。 下表描述了 JSON 文档中的实体与方法参数之间的映射:
| JSON 实体 | 方法参数 | 说明 |
|---|---|---|
computeType |
不可用 | 计算目标。 对于本地目标,值必须是 local。 |
port |
port |
用于公开服务的 HTTP 终结点的本地端口。 |
此 JSON 是用于 CLI 的部署配置示例:
{
"computeType": "local",
"port": 32267
}
将此 JSON 保存为名为 deploymentconfig.json 的文件。
有关详细信息,请参阅部署配置架构。
部署机器学习模型
现在已准备好部署模型。
将 bidaf_onnx:1 替换为模型的名称及其版本号。
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
调用模型
我们来检查一下是否已成功部署回显模型。 你应该能够执行简单的运行情况探知请求以及评分请求:
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
定义入口脚本
现在可以实际加载模型了。 首先,修改入口脚本:
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
将此文件保存为 source_dir 内的 score.py。
请注意,应使用 AZUREML_MODEL_DIR 环境变量定位已注册的模型。 现在你已添加一些 pip 包。
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
将此文件保存为 inferenceconfig.json
再次部署并调用服务
再次部署服务:
将 bidaf_onnx:1 替换为模型的名称及其版本号。
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
然后,确保可以向该服务发送 post 请求:
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
选择计算目标
用于托管模型的计算目标将影响部署的终结点的成本和可用性。 使用此表选择合适的计算目标。
| 计算目标 | 用途 | GPU 支持 | 说明 |
|---|---|---|---|
| 本地 Web 服务 | 测试/调试 | 用于有限的测试和故障排除。 硬件加速依赖于本地系统中库的使用情况。 | |
| Azure 机器学习 Kubernetes | 实时推理 | 是 | 在云中运行推理工作负载。 |
| Azure 容器实例 | 实时推理 建议仅用于开发/测试目的。 |
用于需要小于 48 GB RAM 的基于 CPU 的小规模工作负载。 不需要你管理群集。 只适合小于 1 GB 的模型。 在设计器中受支持。 |
注意
选择群集 SKU 时,请先纵向扩展,然后横向扩展。从其 RAM 是模型所需量的 150% 的计算机开始,然后分析结果,找到具有所需性能的计算机。 了解这一信息后,增加计算机的数量,使其满足你的并发推理需求。
注意
Azure 机器学习终结点 (v2) 提供了经过改进的简化部署体验。 终结点同时支持实时和批量推理场景。 终结点提供了一个统一的接口,以用于跨计算类型调用和管理模型部署。 请参阅什么是 Azure 机器学习终结点?。
部署到云端
一旦确认服务可在本地工作并选取了远程计算目标,便可准备部署到云端了。
更改部署配置,使其与所选的计算目标相对应(本例中为 Azure 容器实例):
适用于部署配置的选项因所选计算目标而异。
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
将此文件保存为 re-deploymentconfig.json。
有关详细信息,请参阅此参考。
再次部署服务:
将 bidaf_onnx:1 替换为模型的名称及其版本号。
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
若要查看服务日志,请使用以下命令:
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
调用远程 Web 服务
远程部署时,可能会启用密钥身份验证。 下方示例介绍了如何使用 Python 获取服务密钥以发出推理请求。
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())请参阅使用 Web 服务的客户端应用程序主题文章,了解使用其他语言的更多示例客户端。
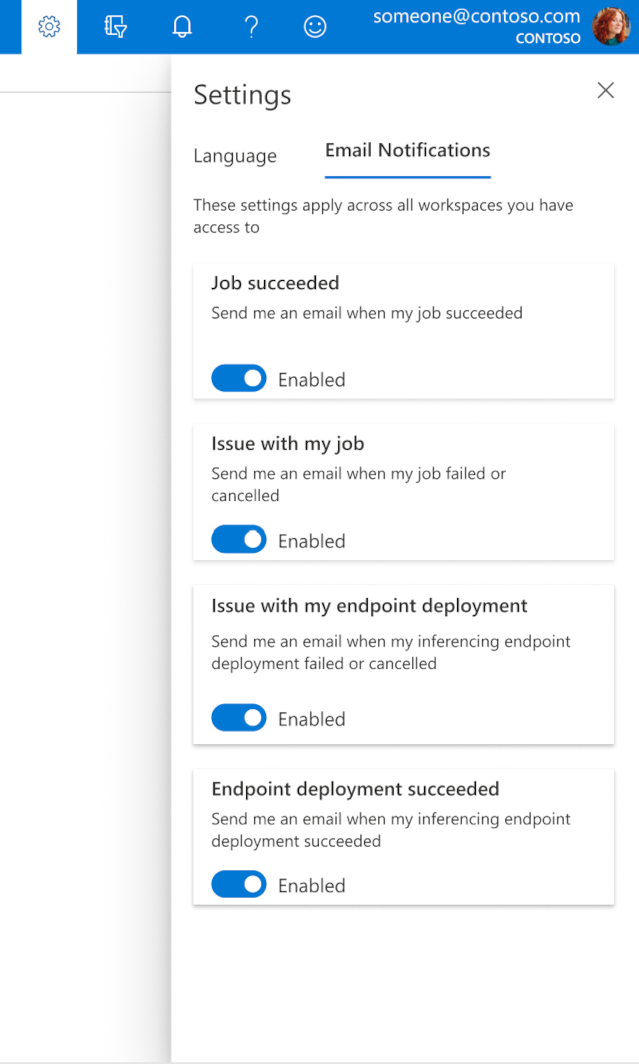
如何在工作室中配置电子邮件
若要开始在作业、联机终结点或批处理终结点完成时或者在出现问题(失败、取消)的情况下接收电子邮件,请按照以下步骤操作:
- 在 Azure ML 工作室中,通过选择齿轮图标来转到设置。
- 选择“电子邮件通知”选项卡。
- 切换开关,为某个特定事件启用或禁用电子邮件通知。
了解服务状态
在模型部署期间,当模型完全部署时,你可能会看到服务状态发生更改。
下表描述了各种服务状态:
| Webservice 状态 | 说明 | 最终状态? |
|---|---|---|
| 正在转换 | 此服务正在进行部署。 | 否 |
| 不正常 | 此服务已部署,但当前无法访问。 | 否 |
| 不可安排 | 由于缺少资源,此时无法部署此服务。 | 否 |
| 已失败 | 由于出现错误或崩溃,服务未能部署。 | 是 |
| 正常 | 服务正常,终结点可用。 | 是 |
提示
在部署时,会从 Azure 容器注册表 (ACR) 生成并加载用于计算目标的 Docker 映像。 在默认情况下,Azure 机器学习会创建一个使用“基本”服务层级的 ACR。 将工作区的 ACR 更改为“标准”或“高级”层级可能会减少生成映像并将其部署到计算目标所花费的时间。 有关详细信息,请参阅 Azure 容器注册表服务层级。
注意
如果要将模型部署到 Azure Kubernetes 服务 (AKS),建议为该群集启用 Azure Monitor。 这将帮助你了解总体群集运行状况和资源使用情况。 以下资源也可能有用:
如果尝试将模型部署到运行不正常或重载的群集,应该会遇到问题。 如果需要帮助排查 AKS 群集问题,请联系 AKS 支持。
删除资源
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
若要删除已部署的 webservice,请使用 az ml service delete <name of webservice>。
若要从工作区中删除已注册的模型,请使用 az ml model delete <model id>
详细了解如何删除 webservice 和删除模型。