你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Apache Spark 池进行数据整理(已停用)

警告
Python SDK v1 中 Azure Synapse Analytics 与 Azure 机器学习的集成已停用。 用户仍然可以使用在 Azure 机器学习中注册为链接服务的 Synapse 工作区。 但新的 Synapse 工作区不能再在 Azure 机器学习中注册为链接服务。 建议使用 CLI v2 和 Python SDK v2 中提供的无服务器 Spark 计算和附加的 Synapse Spark 池。 有关详细信息,请访问 https://aka.ms/aml-spark。
本文介绍如何在 Jupyter 笔记本中以交互方式执行专用 Synapse 会话中的数据整理任务,该会话由 Azure Synapse Analytics 提供支持。 这些任务依赖于 Azure 机器学习 Python SDK。 有关 Azure 机器学习管道的详细信息,请访问如何在机器学习管道中使用由 Azure Synapse Analytics 提供支持的 Apache Spark(预览版)。 有关如何将 Azure Synapse Analytics 与 Synapse 工作区配合使用的详细信息,请访问 Azure Synapse Analytics 入门系列。
Azure 机器学习与 Azure Synapse Analytics 的集成
通过 Azure Synapse Analytics 与 Azure 机器学习的集成(预览版),你可以附加由 Azure Synapse 提供支持的 Apache Spark 池,以进行交互式数据探索和准备。 借助这种集成,你可在用于训练机器学习模型的同一 Python 笔记本中,使用专用计算资源大规模进行数据整理。
先决条件
配置开发环境以安装 Azure 机器学习 SDK,或使用已经安装了该 SDK 的 Azure 机器学习计算实例
使用以下代码安装
azureml-synapse包(预览版):pip install azureml-synapse使用 Azure 机器学习 Python SDK 或 Azure 机器学习工作室链接 Azure 机器学习工作区和 Azure Synapse Analytics 工作区
将 Synapse Spark 池附加为计算目标
启动 Synapse Spark 池以执行数据整理任务
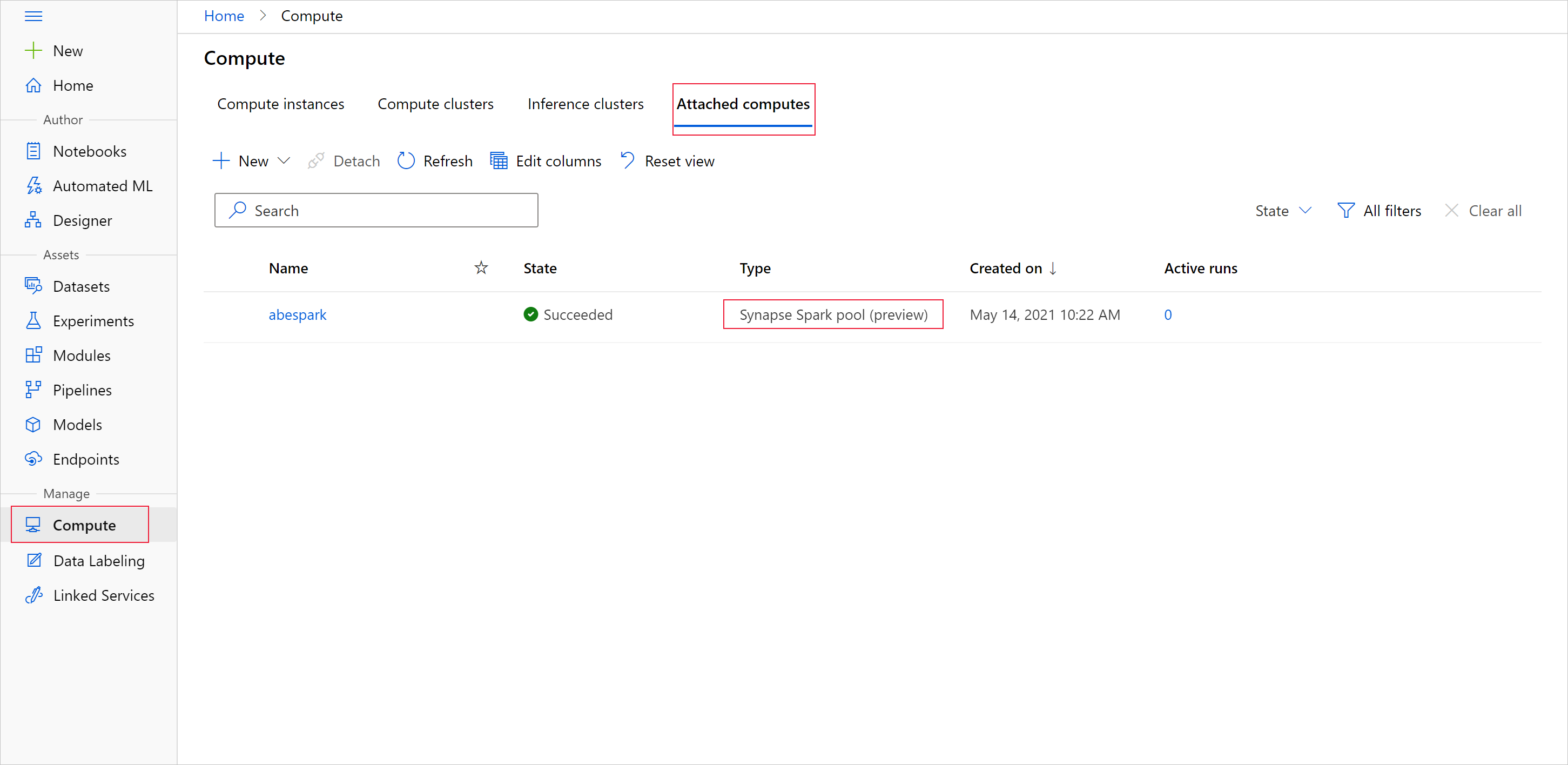
若要开始通过 Apache Spark 池进行数据准备,请指定附加的 Spark Synapse 计算的名称。 可以通过 Azure 机器学习工作室在“附加的计算”选项卡下找到此名称。
重要
若要继续使用 Apache Spark 池,必须指示要在整个数据整理任务中使用的计算资源。 将 %synapse 用于单行代码,将 %%synapse 用于多行代码:
%synapse start -c SynapseSparkPoolAlias
会话启动后,可以检查会话的元数据:
%synapse meta
你可以指定要在 Apache Spark 会话期间使用的 Azure 机器学习环境。 只有在环境中指定的 Conda 依赖项才会生效。 不支持 Docker 映像。
警告
Apache Spark 池不支持在环境 Conda 依赖项中指定的 Python 依赖项。 目前,脚本中仅支持 sys.version_info 中包含的固定 Python 版本以检查你的 Python 版本
下面的代码用于创建环境 myenv,以在会话开始之前安装 azureml-core 版本 1.20.0 和 numpy 版本 1.17.0。 然后,你可以将此环境包含在 Apache Spark 会话 start 语句中。
from azureml.core import Workspace, Environment
# creates environment with numpy and azureml-core dependencies
ws = Workspace.from_config()
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core==1.20.0")
env.python.conda_dependencies.add_conda_package("numpy==1.17.0")
env.register(workspace=ws)
若要在自定义环境中通过 Apache Spark 池开始数据准备,请指定 Apache Spark 池名称和在 Apache Spark 会话期间使用的环境。 可以提供订阅 ID、机器学习工作区资源组和机器学习工作区的名称。
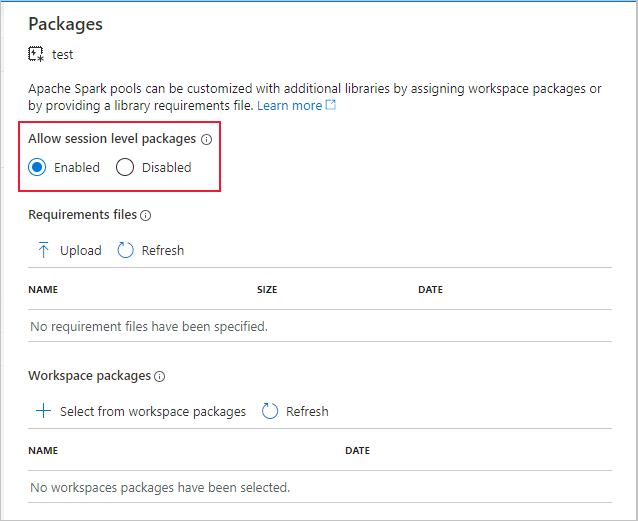
%synapse start -c SynapseSparkPoolAlias -e myenv -s AzureMLworkspaceSubscriptionID -r AzureMLworkspaceResourceGroupName -w AzureMLworkspaceName
从存储加载数据
Apache Spark 会话启动后,请读取要准备的数据。 Azure Blob 存储和 Azure Data Lake Storage Gen 1 和 Gen 2 支持数据加载。
可以通过两种方法从这些存储服务加载数据:
使用 Hadoop 分布式文件系统 (HDFS) 路径直接从存储中加载数据
从现有 Azure 机器学习数据集中读取数据
若要访问这些存储服务,需要具有“存储 Blob 数据读取者”权限。 如果要将数据写回这些存储服务,则需要具有“存储 Blob 数据参与者”权限。 详细了解存储权限和角色。
使用 Hadoop 分布式文件系统 (HDFS) 路径加载数据
要使用相应的 HDFS 路径从存储中加载和读取数据,你需要具有现成的数据访问身份验证凭据。 这些凭据因存储类型而异。 以下代码示例演示如何使用共享访问签名 (SAS) 令牌或访问密钥将数据从 Azure Blob 存储读取到 Spark 数据帧中:
%%synapse
# setup access key or SAS token
sc._jsc.hadoopConfiguration().set("fs.azure.account.key.<storage account name>.blob.core.windows.net", "<access key>")
sc._jsc.hadoopConfiguration().set("fs.azure.sas.<container name>.<storage account name>.blob.core.windows.net", "<sas token>")
# read from blob
df = spark.read.option("header", "true").csv("wasbs://demo@dprepdata.blob.core.windows.net/Titanic.csv")
以下代码示例演示如何使用服务主体凭据从 Azure Data Lake Storage Generation 1 (ADLS Gen 1) 中读取数据:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.access.token.provider.type","ClientCredential")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.client.id", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.credential", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.refresh.url",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("adl://<storage account name>.azuredatalakestore.net/<path>")
以下代码示例演示如何使用服务主体凭据从 Azure Data Lake Storage Generation 2 (ADLS Gen 2) 中读取数据:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<storage account name>.dfs.core.windows.net","OAuth")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<storage account name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<storage account name>.dfs.core.windows.net", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<storage account name>.dfs.core.windows.net", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<storage account name>.dfs.core.windows.net",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("abfss://<container name>@<storage account>.dfs.core.windows.net/<path>")
从已注册的数据集中读取数据
如果将现有的已注册数据集转换为 Spark 数据帧,还可以将其放置在工作区中,并对该数据集执行数据准备。 以下示例在通过工作区身份验证后,获取一个已注册的 TabularDataset -blob_dset,该数据集引用 Blob 存储中的文件,并将该 TabularDataset 转换为 Spark 数据帧。 将数据集转换为 Spark 数据帧时,你可以使用 pyspark 数据探索和准备库。
%%synapse
from azureml.core import Workspace, Dataset
subscription_id = "<enter your subscription ID>"
resource_group = "<enter your resource group>"
workspace_name = "<enter your workspace name>"
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
dset = Dataset.get_by_name(ws, "blob_dset")
spark_df = dset.to_spark_dataframe()
执行数据整理任务
检索并探索数据之后,即可以执行数据整理任务。 以下代码示例扩展了上一部分中的 HDFS 示例。 基于“幸存者”列,它按 Spark 数据帧 df 中的数据以及按“年龄”列出的组进行筛选:
%%synapse
from pyspark.sql.functions import col, desc
df.filter(col('Survived') == 1).groupBy('Age').count().orderBy(desc('count')).show(10)
df.show()
将数据保存到存储并停止 Spark 会话
数据探索和准备工作完成后,将准备好的数据存储在 Azure 上的存储帐户中,以供以后使用。 在以下示例中,会将准备好的数据写回到 Azure Blob 存储,并覆盖 training_data 目录中的原始 Titanic.csv 文件。 若要写回到存储,需要具有“存储 Blob 数据参与者”权限。 有关详细信息,请访问分配用于访问 Blob 数据的 Azure 角色。
%% synapse
df.write.format("csv").mode("overwrite").save("wasbs://demo@dprepdata.blob.core.windows.net/training_data/Titanic.csv")
完成数据准备并将准备好的数据保存到存储后,请使用以下命令结束 Apache Spark 池的使用:
%synapse stop
创建用于表示准备好的数据的数据集
可以使用准备好的数据进行模型训练后,请使用 Azure 机器学习数据存储连接到存储,并指定要与 Azure 机器学习数据集一起使用的文件。
此代码示例
- 假设你已经创建了一个数据存储,该数据存储可连接到保存了准备好的数据的存储服务
- 使用 get() 方法从工作区
ws检索该现有数据存储mydatastore。 - 创建一个 FileDataset
train_ds,以引用位于mydatastoretraining_data目录中已准备好的数据文件 - 创建变量
input1。 该变量可在以后用于使train_ds数据集的数据文件可供计算目标用于训练任务。
from azureml.core import Datastore, Dataset
datastore = Datastore.get(ws, datastore_name='mydatastore')
datastore_paths = [(datastore, '/training_data/')]
train_ds = Dataset.File.from_files(path=datastore_paths, validate=True)
input1 = train_ds.as_mount()
使用 ScriptRunConfig 将试验运行提交到 Synapse Spark 池
如果数据整理任务的自动化和生产化已准备就绪,可利用 ScriptRunConfig 对象将试验运行提交到附加的 Synapse Spark 池。 同样,如果有 Azure 机器学习管道,则可使用 SynapseSparkStep 将 Synapse Spark 池指定为管道中数据准备步骤的计算目标。 数据对 Synapse Spark 池可用性取决于数据集类型。
- 对于 FileDataset,可以使用
as_hdfs()方法。 提交运行后,数据集将作为 Hadoop 分布式文件系统 (HFDS) 提供给 Synapse Spark 池 - 对于 TabularDataset,可以使用
as_named_input()方法
以下代码示例
- 从上一个代码示例中创建的 FileDataset
train_ds中创建变量input2 - 创建类为
HDFSOutputDatasetConfiguration的变量output。 运行完成后,此类允许我们将运行的输入保存为数据存储mydatastore中的数据集test。 在 Azure 机器学习工作区中,test数据集在名称registered_dataset下进行注册 - 配置运行在 Synapse Spark 池上执行应使用的设置
- 定义 ScriptRunConfig 参数,以便
- 使用
dataprep.py脚本运行 - 指定用作输入的数据,以及使数据对 Synapse Spark 池可用的方法
- 指定存储
output输出数据的位置
- 使用
from azureml.core import Dataset, HDFSOutputDatasetConfig
from azureml.core.environment import CondaDependencies
from azureml.core import RunConfiguration
from azureml.core import ScriptRunConfig
from azureml.core import Experiment
input2 = train_ds.as_hdfs()
output = HDFSOutputDatasetConfig(destination=(datastore, "test").register_on_complete(name="registered_dataset")
run_config = RunConfiguration(framework="pyspark")
run_config.target = synapse_compute_name
run_config.spark.configuration["spark.driver.memory"] = "1g"
run_config.spark.configuration["spark.driver.cores"] = 2
run_config.spark.configuration["spark.executor.memory"] = "1g"
run_config.spark.configuration["spark.executor.cores"] = 1
run_config.spark.configuration["spark.executor.instances"] = 1
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-core==1.20.0")
run_config.environment.python.conda_dependencies = conda_dep
script_run_config = ScriptRunConfig(source_directory = './code',
script= 'dataprep.py',
arguments = ["--file_input", input2,
"--output_dir", output],
run_config = run_config)
有关 run_config.spark.configuration 和常规 Spark 配置的详细信息,请访问 SparkConfiguration 类和 Apache Spark 的配置文档。
设置 ScriptRunConfig 对象后,可以提交运行。
from azureml.core import Experiment
exp = Experiment(workspace=ws, name="synapse-spark")
run = exp.submit(config=script_run_config)
run
有关详细信息,包括此示例中使用的 dataprep.py 脚本的信息,请参阅示例笔记本。
准备好数据后,可将其用作训练作业的输入。 在上述代码示例中,将 registered_dataset 指定为训练作业的输入数据。
示例笔记本
有关 Azure Synapse Analytics 和 Azure 机器学习集成功能的更多概念和演示,请参阅以下示例笔记本: