你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
如何在机器学习管道中使用由 Azure Synapse Analytics 提供支持的 Apache Spark(已停用)

警告
Python SDK v1 中 Azure Synapse Analytics 与 Azure 机器学习的集成已停用。 用户仍然可以使用在 Azure 机器学习中注册为链接服务的 Synapse 工作区。 但新的 Synapse 工作区不能再在 Azure 机器学习中注册为链接服务。 建议使用 CLI v2 和 Python SDK v2 中提供的无服务器 Spark 计算和附加的 Synapse Spark 池。 有关详细信息,请访问 https://aka.ms/aml-spark。
本文介绍如何使用 Azure Synapse Analytics 提供支持的 Apache Spark 池作为 Azure 机器学习管道中数据准备步骤的计算目标。 你将了解单个管道如何使用适用于特定步骤的计算资源,例如数据准备或训练。 你还将了解 Spark 步骤的数据准备情况,以及数据如何传递到下一步。
先决条件
创建用于保留所有管道资源的 Azure 机器学习工作区
配置开发环境以安装 Azure 机器学习 SDK,或使用已经安装了该 SDK 的 Azure 机器学习计算实例
创建 Azure Synapse Analytics 工作区和 Apache Spark 池。 有关详细信息,请访问快速入门:使用 Synapse Studio 创建无服务器 Apache Spark 池
链接 Azure 机器学习工作区和 Azure Synapse Analytics 工作区
在 Azure Synapse Analytics 工作区中创建和管理 Apache Spark 池。 若要将 Apache Spark 池与 Azure 机器学习工作区集成,必须链接到 Azure Synapse Analytics 工作区。 将 Azure 机器学习工作区和 Azure Synapse Analytics 工作区链接起来后,你可以通过以下方式连接 Apache Spark 池:
Python SDK(稍后会介绍)
Azure 资源管理器 (ARM) 模板。 有关详细信息,请访问示例 ARM 模板
- 可使用此代码示例,通过命令行来遵循 ARM 模板,添加链接服务,并附加 Apache Spark 池:
az deployment group create --name --resource-group <rg_name> --template-file "azuredeploy.json" --parameters @"azuredeploy.parameters.json"
重要
若要成功链接到 Synapse 工作区,你必须获授 Synapse 工作区的“所有者”角色。 查看 Azure 门户中的访问权限。
链接服务将在创建时获取系统分配的托管标识 (SAI)。 必须给此链接服务 SAI 分配 Synapse Studio 中的“Synapse Apache Spark 管理员”角色,使其可以提交 Spark 作业(请参阅如何在 Synapse Studio 中管理 Synapse RBAC 角色分配)。
你还必须通过 Azure 资源管理门户向 Azure 机器学习工作区的用户授予“参与者”角色。
检索 Azure Synapse Analytics 工作区与 Azure 机器学习工作区之间的链接
此代码演示如何检索工作区中的链接服务:
from azureml.core import Workspace, LinkedService, SynapseWorkspaceLinkedServiceConfiguration
ws = Workspace.from_config()
for service in LinkedService.list(ws) :
print(f"Service: {service}")
# Retrieve a known linked service
linked_service = LinkedService.get(ws, 'synapselink1')
首先,Workspace.from_config() 使用 config.json 文件中的配置访问 Azure 机器学习工作区。 (有关详细信息,请访问创建工作区配置文件)。 然后,该代码将输出工作区中所有可用的链接服务。 最后,LinkedService.get() 检索名为 'synapselink1' 的链接服务。
附加 Apache spark 池为 Azure 机器学习的计算目标
若要使用 Apache Spark 池为机器学习管道中的步骤提供支持,则必须将它附加为管道步骤的 ComputeTarget,如此代码示例所示:
from azureml.core.compute import SynapseCompute, ComputeTarget
attach_config = SynapseCompute.attach_configuration(
linked_service = linked_service,
type="SynapseSpark",
pool_name="spark01") # This name comes from your Synapse workspace
synapse_compute=ComputeTarget.attach(
workspace=ws,
name='link1-spark01',
attach_configuration=attach_config)
synapse_compute.wait_for_completion()
代码首先配置 SynapseCompute。 linked_service 参数是在上一步中创建或检索的 LinkedService 对象。 type 参数必须为 SynapseSpark。 SynapseCompute.attach_configuration() 中的参数 pool_name 必须与 Azure Synapse Analytics 工作区中现有池的参数匹配。 有关在 Azure Synapse Analytics 工作区中创建 Apache Spark 池的详细信息,请访问快速入门:使用 Synapse Studio 创建无服务器 Apache Spark 池。 attach_config 类型为 ComputeTargetAttachConfiguration。
创建配置后,创建一个机器学习 ComputeTarget,方法是传入 Workspace 和 ComputeTargetAttachConfiguration 值以及你想要在机器学习工作区中用来指代计算的名称。 对 ComputeTarget.attach() 的调用是异步的,因此在调用完成之前,示例会被阻止。
创建一个使用链接 Apache Spark 池的 SynapseSparkStep
Apache Spark 池上的 Spark 作业示例笔记定义了一个简单的机器学习管道。 首先,此笔记本会定义一个数据准备步骤,由上一步中定义的 synapse_compute 提供支持。 然后,此笔记本会定义一个训练步骤,由更适合用于训练的计算目标提供支持。 示例笔记本使用泰坦尼克幸存者数据库来显示数据输入和输出。 它实际上不会清理数据或生成预测模型。 由于此示例并不真正涉及训练,因此训练步骤使用廉价的基于 CPU 的计算资源。
数据流通过 DatasetConsumptionConfig 对象传递到机器学习管道,这些对象可以容纳表格数据或文件集。 数据通常来自工作区数据存储中 blob 存储中的文件。 此代码示例展示了为机器学习管道创建输入的典型代码:
from azureml.core import Dataset
datastore = ws.get_default_datastore()
file_name = 'Titanic.csv'
titanic_tabular_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, file_name)])
step1_input1 = titanic_tabular_dataset.as_named_input("tabular_input")
# Example only: it wouldn't make sense to duplicate input data, especially one as tabular and the other as files
titanic_file_dataset = Dataset.File.from_files(path=[(datastore, file_name)])
step1_input2 = titanic_file_dataset.as_named_input("file_input").as_hdfs()
代码示例假设文件 Titanic.csv 位于 blob 存储中。 此代码演示如何以 TabularDataset 和 FileDataset 的形式读取文件。 此代码仅用于演示目的,因为重复进行输入或将单个数据源解释为包含表的资源和严格意义上的文件都会让人感到困惑。
重要
若要将 FileDataset 用作输入,azureml-core 需要至少为 1.20.0 版本。 可以使用 Environment 类指定它,如稍后所述。 完成一个步骤后,可以存储输出数据,如此代码示例所示:
from azureml.data import HDFSOutputDatasetConfig
step1_output = HDFSOutputDatasetConfig(destination=(datastore,"test")).register_on_complete(name="registered_dataset")
在此代码示例中,datastore 会将数据存储在名为 test 的文件中。 数据将以 Dataset 的形式在机器学习工作区中可用,名称为 registered_dataset。
除数据外,管道步骤还可以有每个步骤的 Python 依赖项。 此外,单个 SynapseSparkStep 对象还可以指定其精确的 Azure Synapse Apache Spark 配置。 若要显示它,以下代码示例指定 azureml-core 包版本必须至少为 1.20.0。 如前文所述,azureml-core 包的这一要求对于使用 FileDataset 作为输入是必需的。
from azureml.core.environment import Environment
from azureml.pipeline.steps import SynapseSparkStep
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core>=1.20.0")
step_1 = SynapseSparkStep(name = 'synapse-spark',
file = 'dataprep.py',
source_directory="./code",
inputs=[step1_input1, step1_input2],
outputs=[step1_output],
arguments = ["--tabular_input", step1_input1,
"--file_input", step1_input2,
"--output_dir", step1_output],
compute_target = 'link1-spark01',
driver_memory = "7g",
driver_cores = 4,
executor_memory = "7g",
executor_cores = 2,
num_executors = 1,
environment = env)
此代码指定了 Azure 机器学习管道中的单个步骤。 此代码的 environment 值会设置特定的 azureml-core 版本,代码可以根据需要添加其他 conda 或 pip 依赖项。
SynapseSparkStep 会从本地计算机压缩并上传 ./code 子目录。 该目录会在计算服务器上重新创建,该步骤会从该目录运行 dataprep.py 脚本。 该步骤的 inputs 和 outputs 是之前讨论过的 step1_input1、step1_input2、step1_output 对象。 若要在 dataprep.py 脚本中访问这些值,最简单的方法是将它们与命名的 arguments 关联起来。
SynapseSparkStep 构造函数的下一组参数控制 Apache Spark。 compute_target 是之前附加为计算目标的 'link1-spark01'。 其他参数用于指定要使用的内存和核心。
示例笔记本将此代码用于 dataprep.py:
import os
import sys
import azureml.core
from pyspark.sql import SparkSession
from azureml.core import Run, Dataset
print(azureml.core.VERSION)
print(os.environ)
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--tabular_input")
parser.add_argument("--file_input")
parser.add_argument("--output_dir")
args = parser.parse_args()
# use dataset sdk to read tabular dataset
run_context = Run.get_context()
dataset = Dataset.get_by_id(run_context.experiment.workspace,id=args.tabular_input)
sdf = dataset.to_spark_dataframe()
sdf.show()
# use hdfs path to read file dataset
spark= SparkSession.builder.getOrCreate()
sdf = spark.read.option("header", "true").csv(args.file_input)
sdf.show()
sdf.coalesce(1).write\
.option("header", "true")\
.mode("append")\
.csv(args.output_dir)
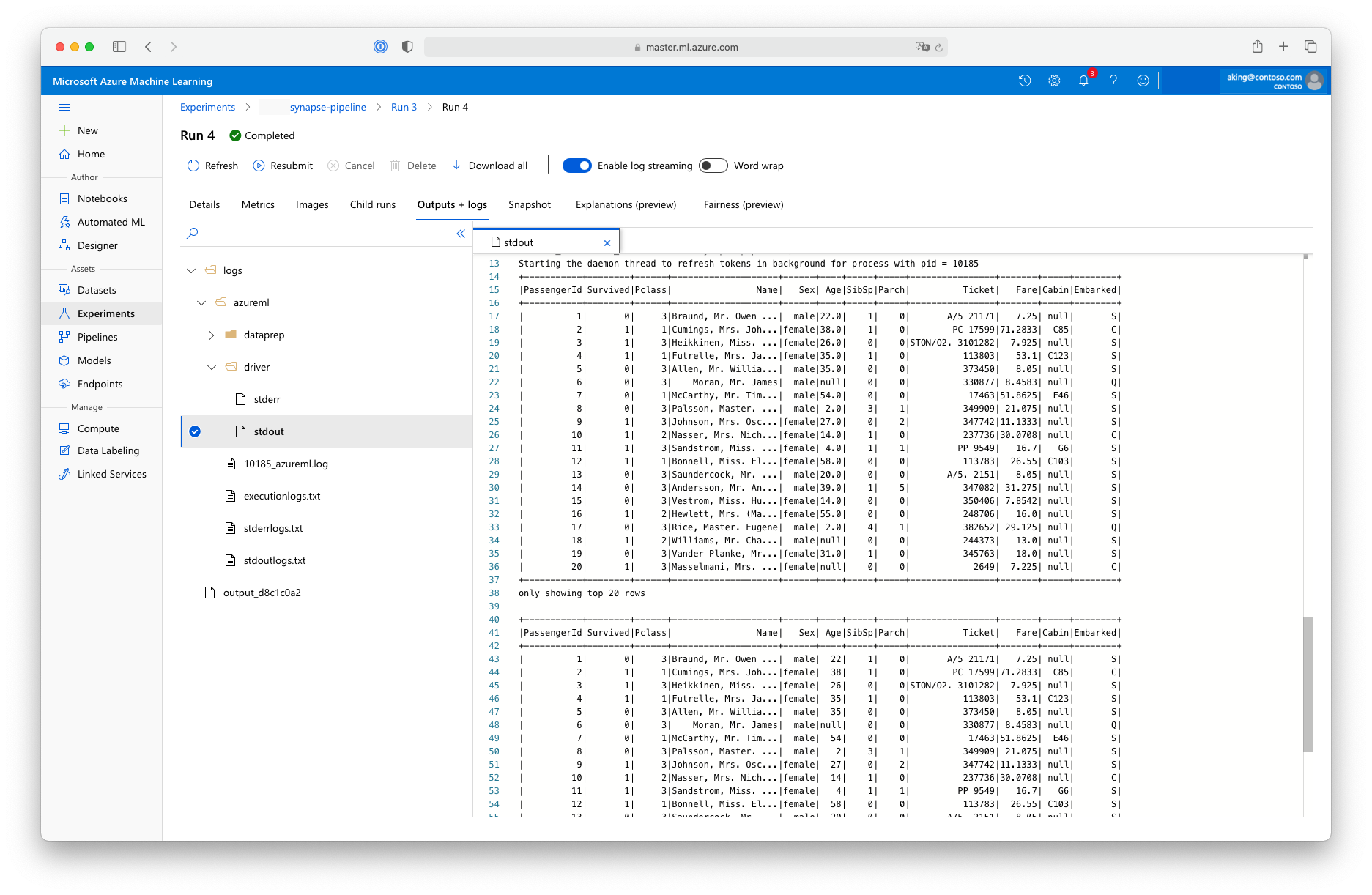
此“数据准备”脚本不执行任何实际数据转换,但它展示了如何检索数据、将数据转换为 Spark 数据帧,以及如何执行一些基本 Apache Spark 操作。 若要在 Azure 机器学习工作室中找到输出,请打开子作业,选择“输出 + 日志”选项卡,然后打开 logs/azureml/driver/stdout 文件,如以下屏幕截图所示:
在管道中使用 SynapseSparkStep
下一个示例使用在上一部分中创建的 SynapseSparkStep 中的输出。 管道中的其他步骤可能具有自己独特的环境,并可能在适合当前任务的不同计算资源上运行。 示例笔记本在小型 CPU 群集上运行“训练步骤”:
from azureml.core.compute import AmlCompute
cpu_cluster_name = "cpucluster"
if cpu_cluster_name in ws.compute_targets:
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
print('Found existing cluster, use it.')
else:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2', max_nodes=1)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
print('Allocating new CPU compute cluster')
cpu_cluster.wait_for_completion(show_output=True)
step2_input = step1_output.as_input("step2_input").as_download()
step_2 = PythonScriptStep(script_name="train.py",
arguments=[step2_input],
inputs=[step2_input],
compute_target=cpu_cluster_name,
source_directory="./code",
allow_reuse=False)
如果需要,此代码会创建新的计算资源。 然后,它将 step1_output 结果转换为训练步骤的输入。 as_download() 选项表示数据会移动到计算资源上,从而加快访问速度。 如果数据太大以至于无法放入本地计算硬盘驱动器,则必须使用 as_mount() 选项通过 FUSE 文件系统流式传输数据。 第二步的 compute_target 是 'cpucluster',而不是在数据准备步骤中使用的 'link1-spark01' 资源。 此步骤使用简单 train.py 脚本而不是在上一步中使用的 dataprep.py 脚本。 示例笔记本包含 train.py 脚本的详细信息。
定义完所有步骤后,可以创建并运行管道。
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(workspace=ws, steps=[step_1, step_2])
pipeline_run = pipeline.submit('synapse-pipeline', regenerate_outputs=True)
此代码会创建一个管道,其中包含由 Azure Synapse Analytics 提供支持的 Apache Spark 池上的数据准备步骤 (step_1) 和训练步骤 (step_2)。 Azure 会检查计算执行图的步骤之间的数据依赖关系。 在此例中,只有一个简单的依赖项。 这里,step2_input 一定需要 step1_output。
如有必要,pipeline.submit 调用会创建一个名为 synapse-pipeline 的试验,并异步启动其中的一个作业。 管道中的单个步骤作为此主作业的子作业运行,工作室的“试验”页可以监视和查看这些步骤。