你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
“导入数据”组件
本文介绍 Azure 机器学习设计器中的一个组件。
使用此组件可以将数据从现有的云数据服务加载到机器学习管道。
注意
此组件提供的所有功能都可以通过工作区登陆页中的“数据存储”和“数据集”来完成。 建议使用数据存储和数据集,因为它们包括数据监视等附加功能。 有关详细信息,请参阅文章如何访问数据和如何注册数据集。 注册数据集后,可以在设计器界面中的“数据集”->“我的数据集”类别中找到它。 此组件针对工作室(经典版)用户而保留,以便其获得熟悉的体验。
“导入数据”组件支持从以下源读取数据:
- 通过 HTTP 从 URL 读取
- 通过 数据存储的 Azure 云存储)
- Azure Blob 容器
- Azure 文件共享
- Azure Data Lake
- Azure Data Lake Gen2
- Azure SQL 数据库
- Azure PostgreSQL
在使用云存储之前,必须先在 Azure 机器学习工作区中注册一个数据存储。 有关详细信息,请参阅如何访问数据。
定义所需的数据并连接到源后, 导入数据 将根据每个列包含的值推断该列的数据类型,并将数据载入设计器管道。 “导入数据”的输出是可在任何设计器管道中使用的数据集。
如果源数据发生更改,可以通过重新运行导入数据来刷新数据集并添加新数据。
警告
如果工作区位于虚拟网络中,则必须将数据存储配置为使用设计器的数据可视化功能。 有关如何在虚拟网络中使用数据存储和数据集的详细信息,请参阅在 Azure 虚拟网络中使用 Azure 机器学习工作室。
如何配置“导入数据”
将“导入数据”组件添加到管道。 可以在设计器的“数据输入和输出”类别中找到此组件。
选择此组件以打开右侧面板。
选择“数据源”,然后选择数据源类型。 该类型可以是 HTTP 或数据存储。
如果选择数据存储,则可以选择已注册到 Azure 机器学习工作区的现有数据存储,或创建新的数据存储。 然后,定义数据在数据存储中的导入路径。 可以通过选择“浏览路径”来轻松浏览路径。
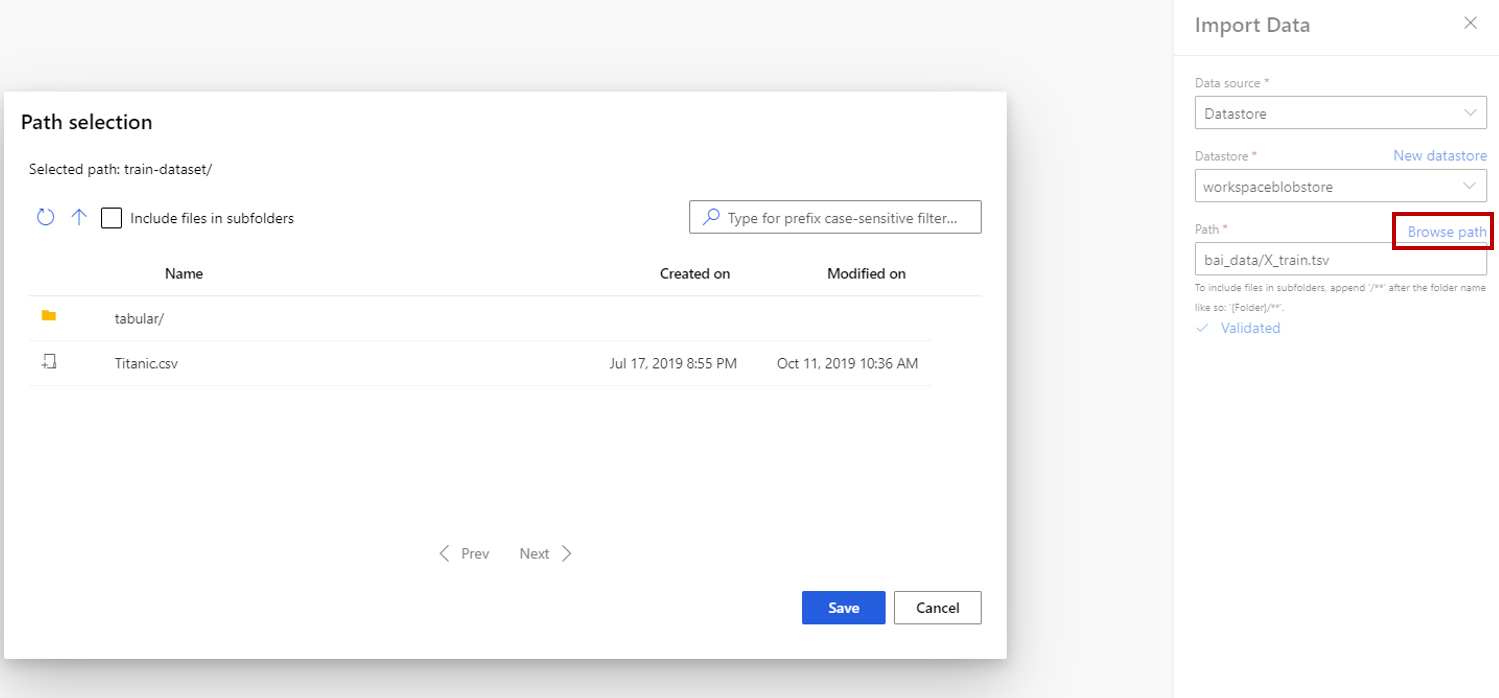
注意
“导入数据”组件仅适用于表格数据。 如果希望一次导入多个表格数据文件,则需要满足以下条件,否则会发生错误:
- 若要包含文件夹中的所有数据文件,需要为“路径”输入
folder_name/**。 - 所有数据文件都必须以 unicode-8 编码。
- 所有数据文件都必须具有相同的列数和列名。
- 导入多个数据文件的结果是按顺序串联多个文件中的所有行。
- 若要包含文件夹中的所有数据文件,需要为“路径”输入
选择“预览架构”以筛选要包含的列。 还可以在“分析”选项中定义高级设置,例如“分隔符”。
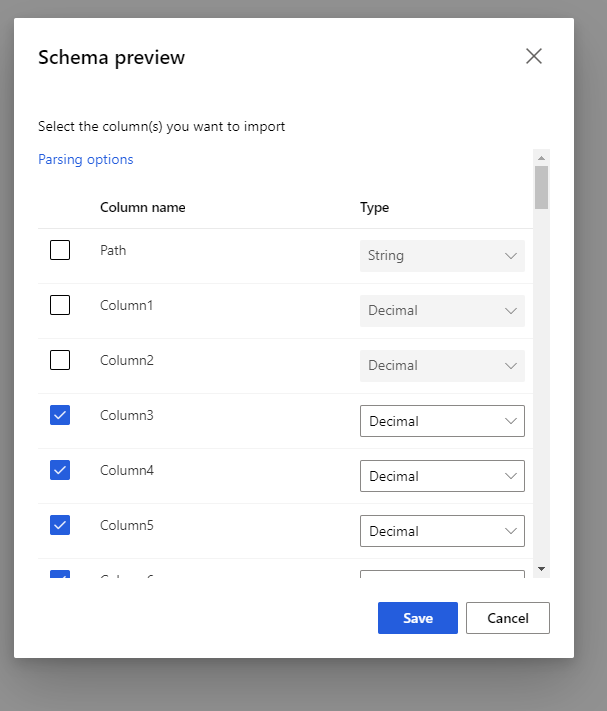
“重新生成输出”复选框决定是否在运行时执行组件以重新生成输出。
它默认处于未选中状态,这意味着,如果先前已使用相同的参数执行了该组件,系统会重复使用上次运行的输出以缩短运行时间。
如果选择它,系统会再次执行组件以重新生成输出。 因此,更新存储中的基础数据时,选择此选项可以帮助获取最新数据。
提交管道。
当“导入数据”将数据载入设计器时,它会根据每个列包含的值推断该列的数据类型:数字或分类。
如果标题存在,则使用该标题来命名输出数据集的列。
如果数据中没有现有的列标题,将使用以下格式生成新的列名称:col1, col2,…。 , coln*。

结果
导入完成后,请右键单击输出数据集,然后选择“可视化”以查看是否已成功导入数据。
如果要保存数据以供重用,而不想在每次运行管道时导入新的数据集,请在组件右侧面板的“输出 + 日志”选项卡下选择“注册数据集”图标。 选择数据集的名称。 保存的数据集将保留单击保存时存在的数据。 重新运行管道时不会更新数据集,即使管道中的数据集发生更改,也是如此。 这有助于创建数据快照。
导入数据后,可能需要对它进行一些额外的准备,才能将它用于建模和分析:
使用编辑元数据更改列名、将列处理为不同的数据类型,或指示某些列是标签或特征。
使用选择数据集中的列选择要转换的或要在建模中使用的列子集。 通过使用添加列组件,可以轻松地将转换或删除的列重新加入原始数据集。
使用分区和采样来分割数据集、执行采样或获取排名靠前的 n 行。
限制
由于存在数据存储访问限制,如果推理管道包含“导入数据”组件,它将在部署到实时终结点时被自动删除。
后续步骤
请参阅 Azure 机器学习可用的组件集。