你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
在 Azure 逻辑应用中处理错误和异常
适用范围:Azure 逻辑应用(消耗型 + 标准型)
恰当地处理依赖系统造成的停机或问题对任何集成体系结构而言可能都是一个难题。 为了帮助创建可适当处理问题和故障的可靠、可复原集成,Azure 逻辑应用提供了用于处理错误和异常的一流体验。
重试策略
对于最基本的异常和错误处理,可对触发器或操作(例如 HTTP 操作)使用重试策略(如果支持)。 如果触发器或操作的原始请求超时或失败,导致出现 408、429 或 5xx 响应,则重试策略将指定触发器或操作根据策略设置重新发送请求。
重试策略限制
有关重试策略、设置、限制和其他选项的详细信息,请查看重试策略限制。
重试策略类型
支持重试策略的连接器操作使用“默认”策略,除非你选择其他重试策略。
| 重试策略 | 说明 |
|---|---|
| Default | 对于大多数操作,“默认”重试策略是指数间隔策略,它采用指数级增长间隔最多发送 4 次重试。 这些间隔的增幅为 7.5 秒,但范围限定在 5 到 45 秒之间。 多个操作使用不同的“默认”重试策略,例如固定间隔策略。 有关详细信息,请查看默认重试策略类型。 |
| 无 | 不重新发送请求。 有关详细信息,请查看无 - 无重试策略。 |
| 指数间隔 | 此策略会等待从指数级增长的范围中随机选定的时间间隔,然后再发送下一个请求。 有关详细信息,请查看指数间隔策略类型。 |
| 固定间隔 | 此策略会等待指定的时间间隔,然后再发送下一个请求。 有关详细信息,请查看固定间隔策略类型。 |
在设计器中更改重试策略类型
在 Azure 门户中,打开设计器的逻辑应用工作流。
根据你使用的是消耗工作流还是标准工作流,打开触发器或操作的“设置”。
消耗:在操作形状上,打开省略号菜单 (...),然后选择“设置”。
标准:在设计器中选择操作。 在详细信息窗格中选择“设置”。
如果触发器或操作支持重试策略,请在“重试策略”下选择所需的策略类型。
在代码视图编辑器中更改重试策略类型
如有必要,请通过在设计器中完成上述步骤来确认触发器或操作是否支持重试策略。
在代码视图编辑器中打开你的逻辑应用工作流。
在触发器或操作定义中,将
retryPolicyJSON 对象添加到该触发器或操作的inputs对象。 否则,如果不存在retryPolicy对象,则触发器或操作使用default重试策略。"inputs": { <...>, "retryPolicy": { "type": "<retry-policy-type>", // The following properties apply to specific retry policies. "count": <retry-attempts>, "interval": "<retry-interval>", "maximumInterval": "<maximum-interval>", "minimumInterval": "<minimum-interval>" }, <...> }, "runAfter": {}必需
属性 值 类型 说明 type< retry-policy-type> String 要使用的重试策略类型: default、none、fixed或exponentialcount< retry-attempts> Integer 对于 fixed和exponential策略类型,该属性为重试次数,其值为 1 - 90。 有关详细信息,请查看固定间隔和指数间隔。interval< retry-interval> String 对于 fixed和exponential策略类型,重试间隔值采用 ISO 8601 格式。 对于exponential策略,还可以指定可选的最大和最小间隔。 有关详细信息,请查看固定间隔和指数间隔。
消耗:5 秒 (PT5S) 到 1 天 (P1D)。
标准:对于有状态工作流,值为 5 秒 (PT5S) 到 1 天 (P1D)。 对于无状态工作流,值为 1 秒 (PT1S) 到 1 分钟 (PT1M)。可选
属性 值 类型 说明 maximumInterval< maximum-interval> String 对于 exponential策略,值为随机选择的间隔的最大间隔,采用 ISO 8601 格式。 默认值为 1 天 (P1D)。 有关详细信息,请查看指数间隔。minimumInterval< minimum-interval> String 对于 exponential策略,值为随机选择的间隔的最小间隔,采用 ISO 8601 格式。 默认值为 5 秒 (PT5S)。 有关详细信息,请查看指数间隔。
默认重试策略
支持重试策略的连接器操作使用“默认”策略,除非你选择其他重试策略。 对于大多数操作,“默认”重试策略是指数间隔策略,它采用指数级增长间隔最多发送 4 次重试。 这些间隔的增幅为 7.5 秒,但范围限定在 5 到 45 秒之间。 多个操作使用不同的“默认”重试策略,例如固定间隔策略。
在工作流定义中,触发器或操作定义不会显式定义默认策略,但以下示例显示了默认重试策略针对 HTTP 操作的行为方式:
"HTTP": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "http://myAPIendpoint/api/action",
"retryPolicy" : {
"type": "exponential",
"interval": "PT7S",
"count": 4,
"minimumInterval": "PT5S",
"maximumInterval": "PT1H"
}
},
"runAfter": {}
}
无 - 无重试策略
要指定操作或触发器不重试失败的请求,请将 <retry-policy-type> 设置为 none。
固定间隔重试策略
要指定操作或触发器在等待指定的时间间隔后再发送下一个请求,请将 <retry-policy-type> 设置为 fixed。
示例
该重试策略在首次请求失败后再尝试获取最新资讯两次,每次尝试之间延迟 30 秒:
"Get_latest_news": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "https://mynews.example.com/latest",
"retryPolicy": {
"type": "fixed",
"interval": "PT30S",
"count": 2
}
}
}
指数间隔重试策略
指数间隔重试策略指定触发器或操作在发送下一个请求之前等待随机的时间间隔。 此随机时间间隔选自指数级增长的范围。 (可选)你可以根据使用的是消耗还是标准逻辑应用工作流,通过指定自己的最小和最大间隔来替代默认的最小和最大间隔。
| 名称 | 使用限制 | 标准限制 | 备注 |
|---|---|---|---|
| 最大延迟 | 默认值:1 天 | 默认值:1 小时 | 若要更改消耗逻辑应用工作流中的默认限制,请使用重试策略参数。 若要更改标准逻辑应用工作流中的默认限制,请查看在单租户 Azure 逻辑应用中编辑逻辑应用的主机和应用设置。 |
| 最小延迟 | 默认值:5 秒 | 默认值:5 秒 | 若要更改消耗逻辑应用工作流中的默认限制,请使用重试策略参数。 若要更改标准逻辑应用工作流中的默认限制,请查看在单租户 Azure 逻辑应用中编辑逻辑应用的主机和应用设置。 |
随机变量范围
对于指数间隔重试策略,下表显示了由 Azure 逻辑应用用来为每次重试生成指定范围内的统一随机变量的一般算法。 指定范围的上限可为重试次数(含)。
| 重试次数 | 最小间隔 | 最大间隔 |
|---|---|---|
| 1 | max(0, <minimum-interval>) | min(interval, <maximum-interval>) |
| 2 | max(interval, <minimum-interval>) | min(2 * interval, <maximum-interval>) |
| 3 | max(2 * interval, <minimum-interval>) | min(4 * interval, <maximum-interval>) |
| 4 | max(4 * interval, <minimum-interval>) | min(8 * interval, <maximum-interval>) |
| .... | .... | .... |
管理“此后运行”行为
在工作流设计器中添加操作时,会隐式声明要用于运行这些操作的顺序。 操作完成运行后,该操作将标记为“成功”、“失败”、“已跳过”或“超时”等状态。 默认情况下,在设计器中添加的操作仅在前置操作完成且状态为“成功”后运行。 在操作的基础定义中,runAfter 属性指定必须首先完成的前置操作,以及在后续任务操作可以运行之前该前置操作允许的状态。
当某个操作引发未处理的错误或异常时,该操作将标记为“失败”,并且任何后续操作都会标记为“已跳过”。 如果具有并行分支的操作发生此行为,则 Azure 逻辑应用引擎将遵循其他分支来确定其完成状态。 例如,如果某个分支以“已跳过”操作结尾,则该分支的完成状态将基于该跳过的操作的前置操作状态。 工作流运行完成后,引擎通过评估所有分支状态确定整个运行的状态。 如果任一分支以失败结束,则整个工作流运行将标记为“失败”。
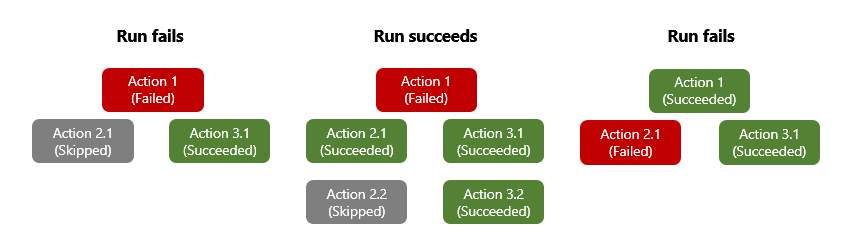
若要确保某个操作无论其前置操作状态如何仍可以运行,可以更改操作的“此后运行”行为,以处理前置操作的不成功状态。 这样,当前置操作的状态为“成功”、“失败”、“已跳过”、“超时”或所有这些状态时,将运行该操作。
例如,若要在 Excel Online 的“将行添加到表中”前置操作标记为“失败”而不是“成功”后运行 Office 365 Outlook 的“发送电子邮件”操作,请使用设计器或代码视图编辑器更改“此后运行”行为。
注意
在设计器中,“此后运行”设置不适用于紧接在触发器之后的操作,因为触发器必须先成功运行,然后才能运行第一个操作。
在设计器中更改“此后运行”行为
在 Azure 门户上的设计器中打开逻辑应用工作流。
在设计器中选择操作形状。 在详细信息窗格中选择“设置”。
“设置”窗格中的“此后运行”节将显示当前选定操作的前置操作。
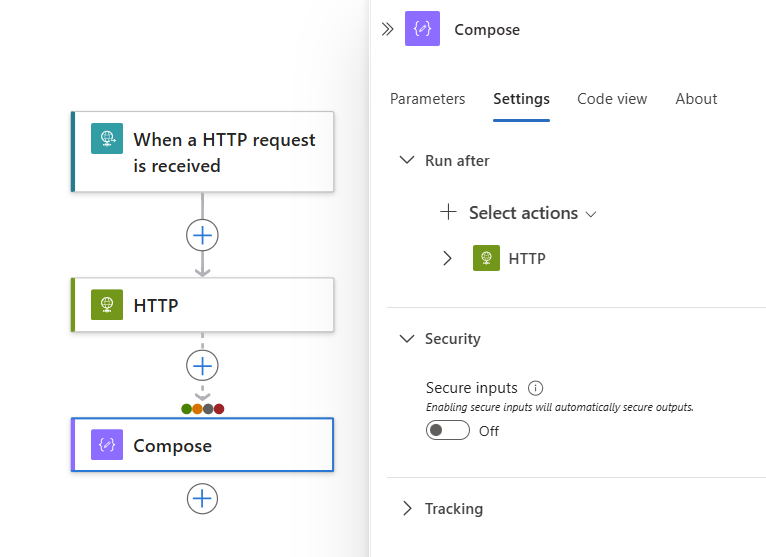
展开前置任务以查看所有可能的前置任务状态。
默认情况下,“此后运行”状态设置为“成功”。 因此,前置操作必须先成功完成,然后才能运行当前选定的操作。
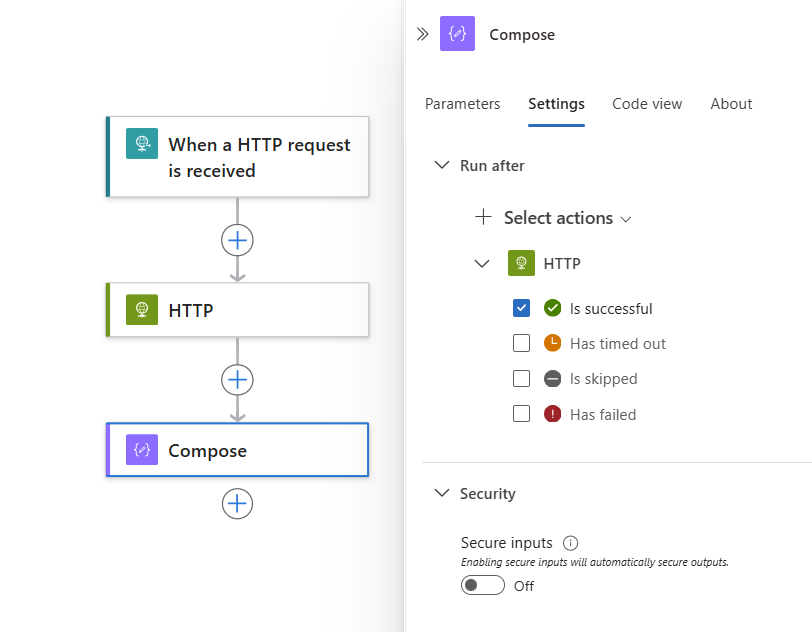
若要将“运行后”行为更改为所需的状态,请选择这些状态。 在清除默认选项之前,请确保先选择一个选项。 始终必须选择至少一个选项。
以下示例选择了“已失败”。
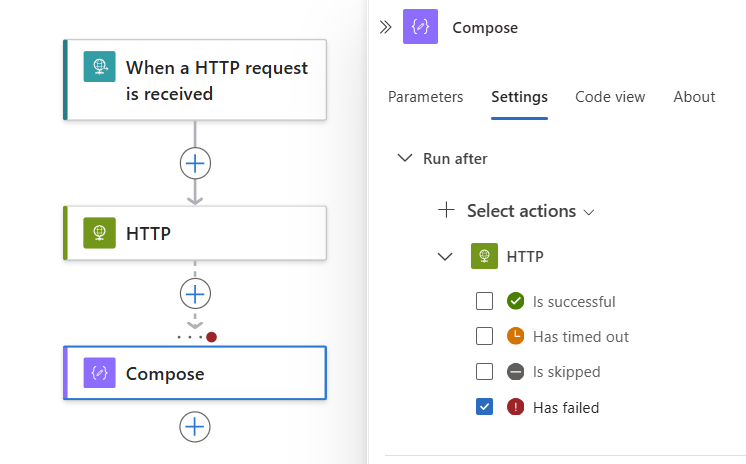
若要指定在前置任务完成后为“失败”、“跳过”或“超时”状态时运行当前操作, 请选择这些状态。
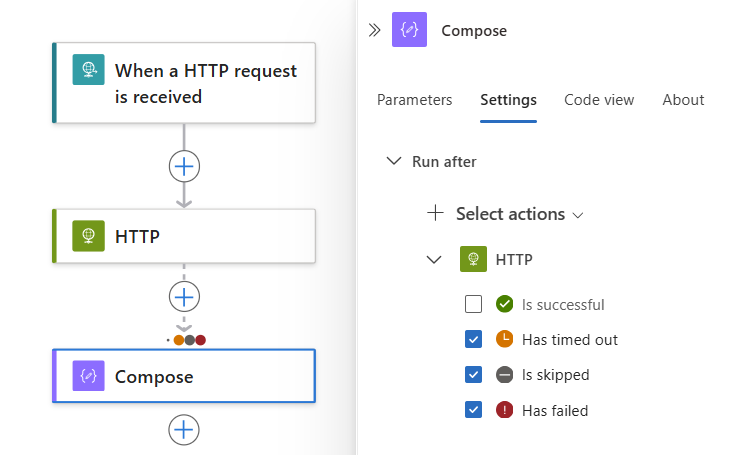
若要要求运行多个前置操作,并且每个操作具有自身的“此后运行”状态,请展开“选择操作”列表。 选择所需的前置操作,然后指定其所需的“此后运行”状态。
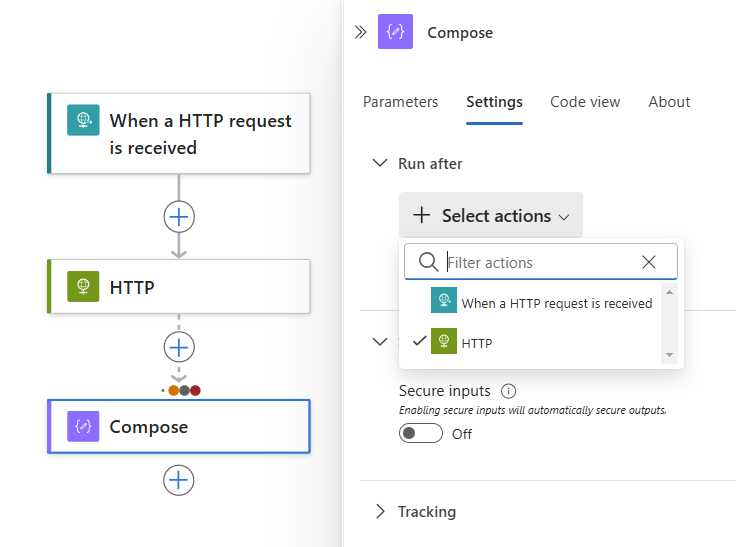
准备就绪后,选择“完成”。
在代码视图编辑器中更改“此后运行”行为
在 Azure 门户上的代码视图编辑器中打开逻辑应用工作流。
在操作的 JSON 定义中,编辑采用以下语法的
runAfter属性:"<action-name>": { "inputs": { "<action-specific-inputs>" }, "runAfter": { "<preceding-action>": [ "Succeeded" ] }, "type": "<action-type>" }对于本示例,请将
runAfter属性从Succeeded更改为Failed:"Send_an_email_(V2)": { "inputs": { "body": { "Body": "<p>Failed to add row to table: @{body('Add_a_row_into_a_table')?['Terms']}</p>", "Subject": "Add row to table failed: @{body('Add_a_row_into_a_table')?['Terms']}", "To": "Sophia.Owen@fabrikam.com" }, "host": { "connection": { "name": "@parameters('$connections')['office365']['connectionId']" } }, "method": "post", "path": "/v2/Mail" }, "runAfter": { "Add_a_row_into_a_table": [ "Failed" ] }, "type": "ApiConnection" }若要将操作指定为在前置任务操作被标记为
Failed、Skipped或TimedOut时都会运行,请添加其他状态:"runAfter": { "Add_a_row_into_a_table": [ "Failed", "Skipped", "TimedOut" ] },
评估具有作用域的操作及其结果
与使用“此后运行”设置在单个操作之后运行步骤类似,可以将操作分组到某个范围内。 如果希望以逻辑方式将各个操作组合在一起,可以使用作用域,评估作用域的聚合状态,并基于该状态执行操作。 当某个作用域中的所有操作都完成运行后,该作用域本身也确定了其自己的状态。
若要检查范围的状态,可以使用与用来检查工作流运行状态(例如“成功”、“失败”等)的条件相同的条件。
默认情况下,当作用域的所有操作都成功时,作用域的状态将被标记为 Succeeded。 如果范围内最后一个操作的状态为“失败”或“已中止”,则范围的状态将标记为“失败”。
若要捕获“失败”范围内的异常并运行用来处理那些错误的操作,可为该“失败”范围使用“此后运行”设置。 这样,如果范围内的任何操作失败并且为该范围使用了“此后运行”设置,则可以创建单个操作来捕获失败。
有关作用域的限制,请参阅限制和配置。
为异常处理设置“运行后”的范围
在 Azure 门户中,打开设计器的逻辑应用工作流。
工作流必须已有启动工作流的触发器。
在设计器中, 遵循以下通用步骤,将名为“范围”的“控件”操作添加到工作流。
在“范围”操作中,按照以下通用步骤操作来运行,例如:
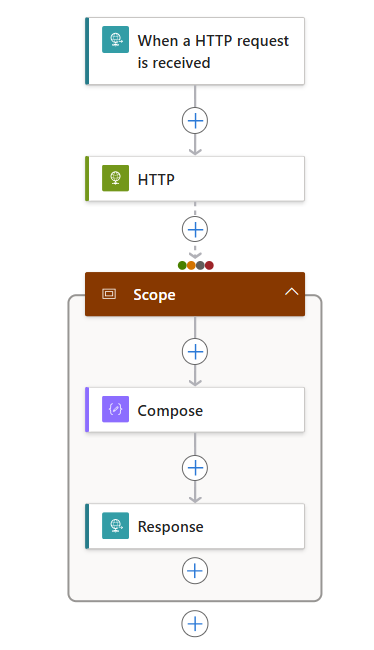
以下列表显示了一些示例操作,你可以在“范围”操作中包含这些操作:
- 从 API 获取数据。
- 处理数据。
- 将数据保存到数据库。
现在,定义用于在作用域中运行操作的“运行后”规则。
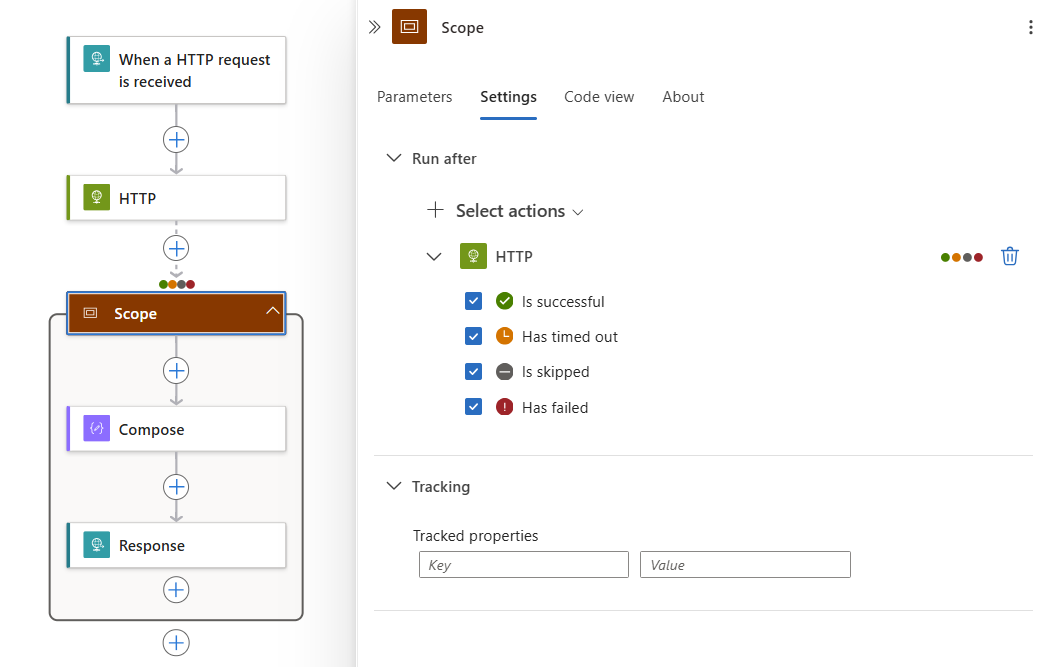
在设计器上,选择“范围”标题。 当作用域的信息窗格打开时,选择“设置”。
如果工作流中有多个前面的操作,请在“选择操作”列表中选择要运行作用域操作的操作。
对于所选操作,请选择可以运行作用域操作的所有操作状态。
换句话说,所选操作产生的任何所选状态都会导致作用域中的操作运行。
在以下示例中,在 HTTP 操作完成并具有任何所选状态后运行作用域的操作:
获取失败的上下文和结果
尽管从范围中捕获失败很有用,但你可能还需要更多上下文来帮助了解确切的失败操作以及任何错误或状态代码。
result() 函数返回范围操作中顶级操作的结果。 此函数接受范围的名称作为单个参数,并返回一个包含这些顶级操作的结果的数组。 这些操作对象包含的特性(例如操作的开始时间、结束时间、状态、输入、相关 ID 和输出)与 actions() 函数返回的特性相同。
注意
result() 函数仅返回顶级操作的结果,而不从更深的嵌套操作(例如切换或条件操作)返回结果。
若要获取范围内失败操作的上下文,可以结合范围名称和“此后运行”设置使用 @result() 表达式。 若要从返回的数组中筛选出“失败”状态的操作,可以添加“筛选数组”操作。 若要为返回的失败操作运行操作,请获取返回的筛选数组,并使用 For each 循环。
以下 JSON 示例发送 HTTP POST 请求,其中包含名为 My_Scope 的范围操作内失败的任何操作的响应正文。 示例后面提供了详细解释。
"Filter_array": {
"type": "Query",
"inputs": {
"from": "@result('My_Scope')",
"where": "@equals(item()['status'], 'Failed')"
},
"runAfter": {
"My_Scope": [
"Failed"
]
}
},
"For_each": {
"type": "foreach",
"actions": {
"Log_exception": {
"type": "Http",
"inputs": {
"method": "POST",
"body": "@item()['outputs']['body']",
"headers": {
"x-failed-action-name": "@item()['name']",
"x-failed-tracking-id": "@item()['clientTrackingId']"
},
"uri": "http://requestb.in/"
},
"runAfter": {}
}
},
"foreach": "@body('Filter_array')",
"runAfter": {
"Filter_array": [
"Succeeded"
]
}
}
以下步骤说明了此示例中发生的操作:
为了获取“My_Scope”中所有操作的结果,“筛选数组”操作使用了以下筛选表达式:
@result('My_Scope')“筛选数组”的条件是状态等于
Failed的任何@result()项。 此条件从包含“My_Scope”中的所有操作结果的数组中筛选出仅包含失败操作结果的数组。对“筛选后的数组”输出执行
For_each循环操作。 此步骤针对前面筛选的每个失败操作结果执行操作。如果作用域中只有一个操作失败,
For_each循环中的操作只运行一次。 如果存在多个失败的操作,则将对每个失败执行一次操作。针对
For_each项响应正文(即@item()['outputs']['body']表达式)发送 HTTP POST。@result()项的形状与@actions()形状相同,可按相同的方式进行分析。包括两个自定义标头,其中包含失败操作的名称 (
@item()['name']) 和失败的运行客户端跟踪 ID (@item()['clientTrackingId'])。
下面提供了单个 @result() 项的示例供参考,其中显示 name、body 和 clientTrackingId 属性已在前面的示例进行分析。 在 For_each 操作外部,@result() 会返回这些对象的数组。
{
"name": "Example_Action_That_Failed",
"inputs": {
"uri": "https://myfailedaction.azurewebsites.net",
"method": "POST"
},
"outputs": {
"statusCode": 404,
"headers": {
"Date": "Thu, 11 Aug 2016 03:18:18 GMT",
"Server": "Microsoft-IIS/8.0",
"X-Powered-By": "ASP.NET",
"Content-Length": "68",
"Content-Type": "application/json"
},
"body": {
"code": "ResourceNotFound",
"message": "/docs/folder-name/resource-name does not exist"
}
},
"startTime": "2016-08-11T03:18:19.7755341Z",
"endTime": "2016-08-11T03:18:20.2598835Z",
"trackingId": "bdd82e28-ba2c-4160-a700-e3a8f1a38e22",
"clientTrackingId": "08587307213861835591296330354",
"code": "NotFound",
"status": "Failed"
}
若要执行不同的异常处理模式,可以使用本文中前面所述的表达式。 可以选择在范围外部执行单个异常处理操作,此操作接受经过筛选的整个失败数组,并删除 For_each 操作。 如前面所述,还可以包含 \@result() 响应中其他有用的属性。
设置 Azure Monitor 日志
前面的模式非常适合用于处理运行中发生的错误和异常。 但是,你还可以识别和响应独立于运行发生的错误。 要评估运行状态,可以监视运行的日志和指标,或将它们发布到你习惯使用的任何监视工具中。
例如,Azure Monitor 提供了一种简便的方式,可将所有工作流事件(包括所有运行和操作状态)发送到目标。 可以在 Azure Monitor 中为特定指标和阈值设置警报。 还可以将工作流事件发送到 Log Analytics 工作区或 Azure 存储帐户。 或者,可以通过 Azure 事件中心将所有事件流式传输到 Azure 流分析。 在流分析中,可以根据诊断日志中的任何异常、平均值或失败编写实时查询。 可以使用流分析将信息发送到其他数据源,例如队列、主题、SQL、Azure Cosmos DB 或 Power BI。
有关详细信息,请参阅为 Azure 逻辑应用设置 Azure Monitor 日志并收集诊断数据。